mysql-(高级篇)-索引
其他
2021-03-20 01:14:00
阅读次数: 0
索引
概述
优势与劣势
- 提高数据索引效率,降低数据IO成本
- 通过索引排序,降低排序成本,降低CPU消耗
- 占用硬盘空间
- 增加维护索引时间,降低更新表的速度
索引结构
MYSQL索引结构
- 索引在mysql存储引擎层实现,每种存储引擎索引不一定完全相同,目前mysql提供四种索引:
- BTREE索引:最常见索引类型,大部分索引都支持B树索引
- HASH索引:只有Memory引擎支持,使用场景简单
- R-TREE索引(空间索引):MyISAM引擎的特殊索引,主要用于地理空间数据类型
- full-text索引(全文索引):MyISAM引擎的特殊索引,主要用于全文索引,innoDB从mysql5.6之后开始支持

B树 [TODO:增加B树的概念, B树的概念其他章节会做总结]
B-树(B树)
B+树
区别
MYSQL中的B+tree
- 对经典B+树进行优化,在原有基础上增加一个指向相邻叶子结点的链表指针,形成了带顺序指针的B+树,提高区间访问性能。

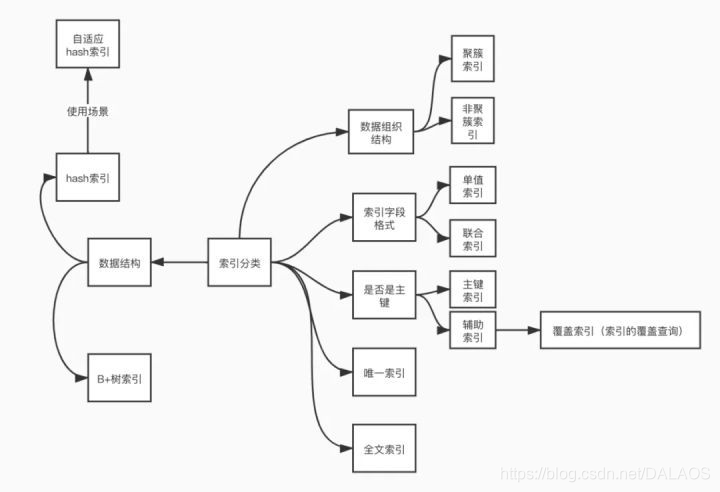
索引分类
分类(每种索引方式需要弄清他们之间的关系)
- 普通索引:这是最基本的索引,它没有任何限制
- 全文索引:在字符串数据中进行复杂的词搜索提供有效支持
- 唯一索引:与普通索引类似,不同的就是:索引列的值必须唯一,但允许有空值。如果是组合索引,则列值的组合必须唯一一
- 主键索引:为保持数据库表与表之间的关系,特殊的唯一索引,不允许有空值。一般是在建表的时候指定了主键,就会创建主键索引, CREATE INDEX不能用来创建主键索引,使用 ALTER TABLE来代替。
- 单值索引:一个索引只包含单个列,一个表可以有多个单列索引
- 复合索引:一个索引包含多个列,多个组合为索引
数据存储方式
- 聚集索引:表中行的物理顺序与键值的逻辑(索引)顺序相同
- 非聚集索引:与聚集索引的区别是表记录的排列顺序和与索引的排列顺序是否一致
索引类型关系
聚簇索引与非聚簇索引
- 当数据库一条记录里包含多个字段时,一棵B+树就只能存储主键,如果检索的是非主键字段,则主键索引失去作用,又变成顺序查找了。这时应该在第二个要检索的列上建立第二套索引。 这个索引由独立的B+树来组织。聚簇与非聚簇用于解决多个B+树访问同一套表数据的问题
- InnoDB使用的是聚簇索引,MyISM使用的是非聚簇索引
- 我找了很多资料,差不多都是用文字来描述两者区别,借用别人博文的图片来体现两者区别更加直观,下图为聚簇与非聚簇的差异
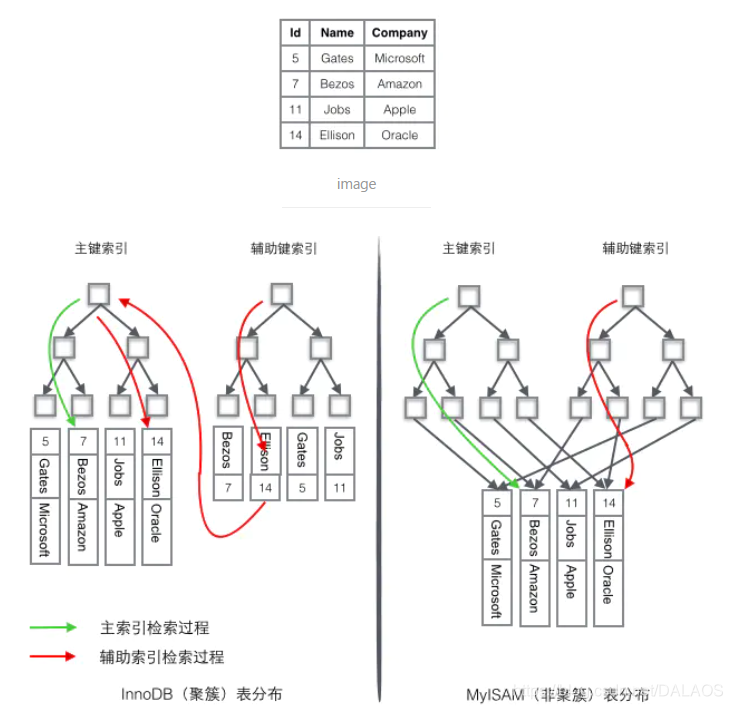
- 我们重点关注聚簇索引,看上去聚簇索引的效率明显要低于非聚簇索引,因为每次使用辅助索引检索都要经过两次B+树查找,这不是多此一举吗?聚簇索引的优势在哪?
聚簇索引的优势
- 由于行数据和叶子节点存储在一起,这样主键和行数据是一起被载入内存的,找到叶子节点就可以立刻将行数据返回了,如果按照主键Id来组织数据,获得数据更快
- 辅助索引使用主键作为"指针" 而不是使用地址值作为指针的好处是,减少了当出现行移动或者数据页分裂时辅助索引的维护工作,使用主键值当作指针会让辅助索引占用更多的空间,换来的好处是InnoDB在移动行时无须更新辅助索引中的这个"指针"。也就是说行的位置会随着数据库里数据的修改而发生变化,使用聚簇索引就可以保证不管这个主键B+树的节点如何变化,辅助索引树都不受影响。
索引使用场景(TODO)
索引语法(TODO)
索引设计原则(TODO)
- 选择表:对查询频次高,数据量大的表创建索引
- == 选择字段==:where子句中提取,选择最常用,过滤效果最好的组合
- 选择索引:尽量使用唯一索引,区分度越高,索引效率越高
- 尽可能减少索引数量,索引越多,维护代价越大
- 尽可能使用短索引
- 利用最左前缀,N个列组合而成的组合索引,那么相当于是创建了N个索引,如果查询时where子句中使用了组成该索引的前几个字段,那么这条查询SQL可以利用组合索引来提升查询效率。
转载自blog.csdn.net/DALAOS/article/details/112863050