树
在计算器科学中,树(英语:tree)是一种抽象数据类型或是实现这种抽象数据类型的数据结构,用来模拟具有树状结构性质的数据集合。它是由n(n>0)个有限节点组成一个具有层次关系的集合。把它叫做“树”是因为它看起来像一棵倒挂的树,也就是说它是根朝上,而叶朝下的。
树的特性
①每个节点有零个或多个子节点;
②没有父节点的节点称为根节点;
③每一个非根节点有且只有一个父节点;
④除了根节点外,每个子节点可以分为多个不相交的子树;
树的专业术语
节点深度:对任意节点x,x节点的深度表示为根节点到x节点的路径长度。所以根节点深度为0,第二层节点深度为1,以此类推
节点高度:对任意节点x,叶子节点到x节点的路径长度就是节点x的高度
树的深度:一棵树中节点的最大深度就是树的深度,也称为高度
父节点:若一个节点含有子节点,则这个节点称为其子节点的父节点
子节点:一个节点含有的子树的根节点称为该节点的子节点
节点的层次:从根节点开始,根节点为第一层,根的子节点为第二层,以此类推
兄弟节点:拥有共同父节点的节点互称为兄弟节点
度:节点的子树数目就是节点的度
叶子节点:度为零的节点就是叶子节点
祖先:对任意节点x,从根节点到节点x的所有节点都是x的祖先(节点x也是自己的祖先)
后代:对任意节点x,从节点x到叶子节点的所有节点都是x的后代(节点x也是自己的后代)
森林:m颗互不相交的树构成的集合就是森林
二叉树
概述:每个节点最多含有两个子树的树称为二叉树
二叉树的衍生树
满二叉树:除最后一层无任何子节点外,每一层上的所有结点都有两个子结点。也可以这样理解,除叶子结点外的所有结点均有两个子结点。节点数达到最大值,所有叶子结点必须在同一层上
完全二叉树:若设二叉树的深度为h,除第 h 层外,其它各层 (1~(h-1)层) 的结点数都达到最大个数,第h层所有的结点都连续集中在最左边,这就是完全二叉树。
二叉查找树:二叉查找树(英语:Binary Search Tree),也称为二叉搜索树、有序二叉树(ordered binary tree)或排序二叉树(sorted binary tree),是指一棵空树或者具有下列性质的二叉树:
- 若任意节点的左子树不空,则左子树上所有节点的值均小于它的根节点的值;
- 若任意节点的右子树不空,则右子树上所有节点的值均大于它的根节点的值;
- 任意节点的左、右子树也分别为二叉查找树;
- 没有键值相等的节点。
平衡二叉树(AVL树):当且仅当任何节点的两棵子树的高度差不大于1的二叉树;
为什么要有平衡二叉树:正常的情况下,二叉查找树的查找的时间复杂度为 O(logn),但是极端情况下二叉查找树退化成了链表,这时候查询的复杂度为O(n),为了解决这个问题,平衡二叉树出来了。
极端情况下的二叉查找树:

二叉树示意图:

二叉树的遍历方式
先序遍历:先根节点->遍历左子树->遍历右子树
中序遍历:遍历左子树->根节点->遍历右子树
后序遍历:遍历左子树->遍历右子树->根节点
红黑树
红黑树详细实现原理:https://blog.csdn.net/kartorz/article/details/8865997
概述:红黑树是每个节点都带有颜色属性的二叉查找树,颜色为红色或黑色。
红黑树的由来:算是平衡二叉树的优化,虽然平衡树解决了二叉查找树退化为近似链表的缺点,能够把查找时间控制在 O(logn),不过却不是最佳的,因为平衡树要求每个节点的左子树和右子树的高度差至多等于1,这个要求实在是太严了,导致每次进行插入/删除节点的时候,几乎都会破坏平衡树的第二个规则,进而我们都需要通过左旋和右旋来进行调整,使之再次成为一颗符合要求的平衡树。
显然,如果在那种插入、删除很频繁的场景中,平衡树需要频繁着进行调整,这会使平衡树的性能大打折扣,为了解决这个问题,于是有了红黑树。
特征:
- 每个结点要么是红的要么是黑的。(红或黑)
- 根结点是黑的。 (根黑)
- 每个叶结点(叶结点即指树尾端NIL指针或NULL结点)都是黑的。 (叶黑)
- 如果一个结点是红的,那么它的两个儿子都是黑的。 (红子黑)
- 对于任意结点而言,其到叶结点树尾端NIL指针的每条路径都包含相同数目的黑结点。(路径下黑相同)
红黑树的树状图

红黑树应用比较广泛:
1.java 1.8 中的HashMap数据结构是 数组+(链表或红黑树),当链表长度超过8时,就会由链表变成红黑树
2. 著名的linux进程调度Completely Fair Scheduler,用红黑树管理进程控制块。
3.epoll在内核中的实现,用红黑树管理事件块
4.nginx中,用红黑树管理timer等
B-tree(B-树或者B树)
概述:B树(英语:B-tree)是一种自平衡的树,能够保持数据有序。这种数据结构能够让查找数据、顺序访问、插入数据及删除的动作,都在对数时间内完成。B树,概括来说是一个一般化的二叉查找树(binary search tree),可以拥有最多2个子节点。与自平衡二叉查找树不同,B树适用于读写相对大的数据块的存储系统,例如磁盘。
B树特性:
- 根结点至少有两个子女。
- 每个中间节点都包含k-1个元素和k个孩子,其中 m/2 <= k <= m
- 每一个叶子节点都包含k-1个元素,其中 m/2 <= k <= m
- 所有的叶子结点都位于同一层。
- 每个节点中的元素从小到大排列,节点当中k-1个元素正好是k个孩子包含的元素的值域分划。

如图所示就是一颗符合规范的B树,由于相比于磁盘IO的速度,内存中的耗时几乎可以省略,所以只要树的高度足够低,IO次数足够小,就可以提升查询性能。
B树的增加删除同样遵循自平衡的性质,有旋转和换位。
B树的应用是文件系统及部分非关系型数据库索引。
B+树
概述:B+ 树是一种树数据结构,通常用于关系型数据库(如Mysql)和操作系统的文件系统中。B+ 树的特点是能够保持数据稳定有序,其插入与修改拥有较稳定的对数时间复杂度。B+ 树元素自底向上插入,这与二叉树恰好相反。
在B树基础上,为叶子结点增加链表指针(B树+叶子有序链表),所有关键字都在叶子结点 中出现,非叶子结点作为叶子结点的索引;B+树总是到叶子结点才命中。
b+树的非叶子节点不保存数据,只保存子树的临界值(最大或者最小),所以同样大小的节点,b+树相对于b树能够有更多的分支,使得这棵树更加矮胖,查询时做的IO操作次数也更少。

- 查找时,首先在根节点进行二分查找,在根节点中找到key所在的指针,然后递归到key子节点进行查找,直到找到那个叶子节点,然后在这个叶子节点上进行二分查找,找出key锁对应的data.
- 插入删除等操作会破坏其平衡性,这里的操作会很复杂,需要对树进行一个分裂、合并、旋转等操作来维护其平衡性。
B+Tree和B-Tree的区别
B-Tree
- 每个节点都存储key和data,所有节点组成这棵树,并且叶子节点指针为null,叶子结点不包含任何关键字信息
B+Tree
- 所有的叶子结点中包含了全部关键字的信息,非叶子节点只存储键值信息,及指向含有这些关键字记录的指针,且叶子结点本身依关键字的大小自小而大的顺序链接,所有的非终端结点可以看成是索引部分,结点中仅含有其子树根结点中最大(或最小)关键字。 (而B树的非终节点也包含需要查找的有效信息)
- 所有叶子节点之间都有一个链指针。
- 数据记录都存放在叶子节点中。
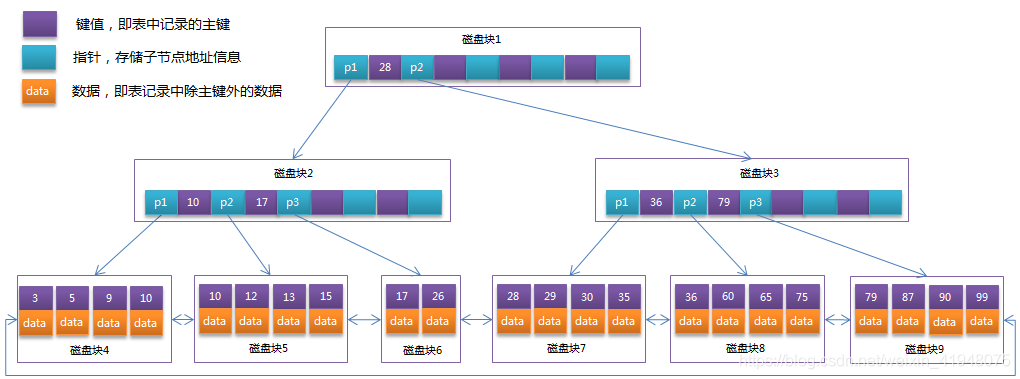
说白了就是为了减少io操作,内存操作基本忽略,而io操作才是真正耗时的。B+tree减低了树的高度。