现在我们已经转换了一组数据,我们可以使用它来为某些用户找到类似的电影。 有许多纯粹的和混合的相似度指标有所差异。
余弦相似度
欧几里德目的地
Jaccard的索引
皮尔森相关
这些指标,我们只检查一部分就可以。
4.1 余弦相似度
余弦相似度,又称为余弦相似性(Cosine similarity),是通过计算两个向量的夹角余弦值来评估他们的相似度。余弦相似度将向量根据坐标值,绘制到向量空间中,如最常见的二维空间。
我们要从指定的数据中找到两个或更多个元素的相似度时,就要用余弦相似度。它非常好并且经常使用,经常被用到机器学习行业。如果你第一次听到这个名词,或者以前学的忘了,建议去看余弦相似性的视频。
余弦相似度的数学公式:
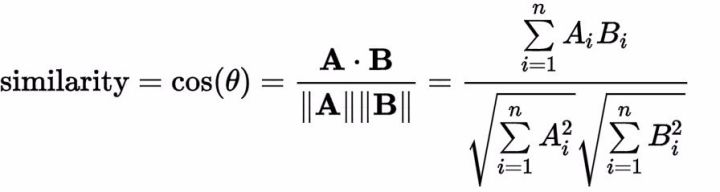
这个公式也可以翻译为:用户A与用户B对电影i的评分的总和,除以A评分的平方,乘以B评分的平方。
4.2 Pearson 相关性
Pearson的计算结果与余弦相似性非常相像。我们就不再详细讨论了,你可以维基百科的找到相关的名词解释。
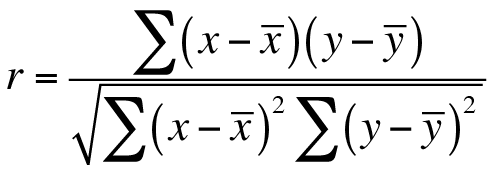
现在我们有一个函数,通过余弦相似度去计算用户兴趣相似性的函数,这大部分就是我们需要的。根据这些数据,我们就可以根据用户以前观看的内容做一个推荐感兴趣的电影的推荐系统。
我们通过以下的Python编程计算相似性功能。
def cos_similarity(people,movie1,movie2):
si={}
for item in people[movie1]:
if item in people[movie2]:
si[item]=1
if len(si)==0:
return 0
sum1=0
sum21=0
sum22=0
for item in si:
sum1+=(people[movie1][item]*people[movie2][item])
sum21+=pow(people[movie1][item],2)
sum22+=pow(people[movie2][item],2)
if sum21==0 or sum22==0:
return 0
return round(sum1/(sqrt(sum21)*sqrt(sum22)),2)
5.输出
最后,让我们来看输出结果。
第一步,需要有一个已观看电影的数据集合:
movies_watched=["You, Me and Dupree","Catch Me If You Can","Snitch"]
现在系统经过了学习,会为我们推荐喜欢的电影。当前是以前的计算结果 ,也会做出输出。
------------------------------ | You, Me and Dupree | ------------------------------- Catch Me If You Can 0.97 Just My Luck 0.85 Lady in the Water 0.96 Snakes on a Plane 0.97 Snitch 1.0 Superman Returns 0.98 The Night Listener 0.96 ------------------------------ | Catch Me If You Can | ------------------------------ Just My Luck 1.0 Lady in the Water 0.98 Snakes on a Plane 0.99 Snitch 1.0 Superman Returns 1.0 The Night Listener 0.92 You, Me and Dupree 0.97 ------------------------------ | Snitch | ------------------------------ Catch Me If You Can 1.0 Just My Luck 1.0 Lady in the Water 0.91 Snakes on a Plane 0.99 Superman Returns 0.99 The Night Listener 0.88 You, Me and Dupree 1.0 ------------------------------
可以看到系统建议的内容。 与“Snitch”最相似的是“Catch Me If You Can”,“Supermermen Returns”等,相当于相似性度量(电影片名之后的数字)。我们想要3个最相似的电影,可以添加阈值来识别相似度。 例如,我们可以将阈值设置为0.98,并且每个超过阈值的电影将出现在我们的屏幕上。
------------------------------ | You, Me and Dupree | ------------------------------- Snitch 1.0 Superman Returns 0.98 ------------------------------ | Catch Me If You Can | ------------------------------ Just My Luck 1.0 Lady in the Water 0.98 Snakes on a Plane 0.99 Snitch 1.0 Superman Returns 1.0 ------------------------------ | Snitch | ------------------------------ Catch Me If You Can 1.0 Just My Luck 1.0 Snakes on a Plane 0.99 Superman Returns 0.99 You, Me and Dupree 1.0 ------------------------------
以上介绍给大家的完整代码,已经全部在Github。
地址为:https://github.com/Mitko06/Recommender-System
结论
祝贺大家,现在我们已经知道如何构建推荐系统的基础知识。
当然,在现实世界中需要建立更复杂的推荐系统。但其中95%都是基于余弦相似性,欧几里德相似性,Pearson相关性等指标。
建立一个推荐系统需要时间和数据积累,本教程已经全部阐述如何构建推荐系统,大家可以依此开发不同的个性化推荐引擎。
现在评论分享你的想法,关于本教程,还有其它任何问题。