文章目录
1 Java8有哪些新特性?
- Lambda表达式
- 函数式接口
- 方法引用
- Stream
- 接口的默认方法和静态方法
- 新的时间日期API
- Optional类
- 其他的还有重复注解、js新引擎、Base64和一些新的并行容器等等
2 Lambda表达式
2.1 什么是Lambda表达式
可以把Lambda表达式理解为简洁地表示可传递的匿名函数的一种方式:它没有名称,但它有参数列表、函数主体、返回类型,可能还有一个可以抛出的异常列表。可以把一个Lambda表达式看成一个接口的实现类(更准确的说是一个函数式接口的实现类,函数式接口是一个只拥有一个抽象方法的接口)。因为一个函数式接口的实现类用很多冗余代码,使用Lambda表达式可以简化代码,而只保留核心的代码。
下面演示将代码简化为Lambda的过程:
2.1.1 使用实现类
先自定义一个类实现Runnable接口,并实现抽象方法。 为什么使用Runnable接口,因为Runnable接口是一个函数式接口,也就是只有一个抽象方法的接口。
import org.junit.Test;
/**
* @author RuiMing Lin
* @date 2020-12-30 20:45
* @description
*/
public class LambdaDemo {
@Test
public void test1() {
MyRunnable myRunnable = new MyRunnable();
Thread thread = new Thread(myRunnable);
thread.start();
}
}
class MyRunnable implements Runnable {
@Override
public void run() {
System.out.println("使用实现类");
}
}
2.1.2 使用匿名内部类
@Test
public void test2(){
Thread thread = new Thread(new Runnable() {
@Override
public void run() {
System.out.println("使用匿名实现类");
}
});
thread.start();
}
2.1.3 使用Lambda表达式
因为MyRunnable类实际有用的代码只有run方法的方法体内容,其他的均是冗余代码。
@Test
public void test3(){
Thread thread = new Thread(() -> {
System.out.println("使用Lambda表达式");
});
thread.start();
}
2.2 Lambda标准格式
Lambda省去面向对象的条条框框,格式由3个部分组成:
- 一个括号(参数列表)
- 一个箭头
- 一段代码(方法体)
Lambda表达式的标准格式为:
(参数类型 参数名称) -> { 代码语句 }
格式说明:
- 小括号内的语法与传统方法参数列表一致:无参数则留空;多个参数则用逗号分隔。
- ->是新引入的语法格式,代表指向动作。
- 大括号内的语法与传统方法体要求基本一致。
2.3 Lambda实战
2.3.1 无参无返回值
@Test
public void test4(){
// 语法格式一:无参,无返回值
Runnable runnable = () -> {
System.out.println("无参无返回值的Lambda表达式");
};
Thread thread = new Thread(runnable);
thread.start();
}
2.3.2 一个参数无返回值
Consumer接口是jdk自定义的一个函数式接口,可以接受一个参数但是没有返回值,意为“消费型接口”。
@Test
public void test5() {
// 语法格式二:一个参数,无返回值
Consumer<String> consumer = (String str) -> {
System.out.println(str);
};
consumer.accept("一个参数,无返回值");
}
2.3.3 多参数有返回值
@Test
public void test8(){
// 语法格式五:多参数有返回值
Comparator<Integer> comparator = (o1,o2) -> {
return Integer.compare(o1, o2);
};
int result = comparator.compare(5, 33);
System.out.println("result = " + result);
}
2.3.4 数据类型可以省略
Consumer在定义时已经定义了泛型,所以可以省略参数列表的数据类型
@Test
public void test6(){
// 语法格式三:数据类型可以省略
Consumer<String> consumer = (str) -> {
System.out.println(str);
};
consumer.accept("数据类型可以省略");
}
2.3.5 数据列表括号可以省略
@Test
public void test7(){
// 语法格式四:数据列表括号可以省略
Consumer<String> consumer = str -> {
System.out.println(str);
};
consumer.accept("数据列表括号可以省略");
}
2.3.6 方法体括号可以省略
@Test
public void test9(){
// 语法格式六:当方法体只有一条语句时,可以省略括号和return
Comparator<Integer> comparator = (o1,o2) -> Integer.compare(o1, o2);
int result = comparator.compare(5, 33);
System.out.println("result = " + result);
}
3 函数式接口
3.1 什么是函数式接口
函数式接口指的是有且仅有一个抽象方法的接口。 因为在Java 8中,新增了Lambda表达式,Lambda表达式为了实现自己推导方法,所使用的接口必须只能有一个抽象方法。所以,函数式接口就是专为Lambda而产生的特殊接口。
要定义一个函数式接口,那么该接口只能有一个抽象方法。为了确保只有一个抽象方法,同时也可以告诉别人这是一个抽象方法,我们通常在接口上添加一个注解:@FunctionalInterface。如果这个接口中的定义不满足函数式接口,那么就会报错。但是注解不是必需的,只是写上注解是良好的编程习惯。
/**
* @author RuiMing Lin
* @date 2020-03-16 20:38
*/
@FunctionalInterface
public interface MyFunctionalInterface {
public abstract void method1(); // 抽象方法
// 虽然函数式接口只能定义一个抽象方法,但是可以定义静态方法、默认方法、私有方法等
public static void method2(){
// ...
}
}
3.2 函数式接口的使用
定义一个函数式接口:
/**
* @author RuiMing Lin
* @date 2020-03-16 20:38
*/
@FunctionalInterface
public interface MyFunctionalInterface {
public abstract void method1(); // 抽象方法
}
定义一个函数式接口的实现类:
/**
* @author RuiMing Lin
* @date 2020-03-16 21:56
*/
public class MyFunctionalInterfaceImpl implements MyFunctionalInterface{
@Override
public void method1() {
System.out.println("使用实现类方式实现抽象方法");
}
}
定义一个测试类:
/**
* @author RuiMing Lin
* @date 2020-03-16 21:58
*/
public class Demo1 {
// 定义一个静态方法,调用函数式接口
public static void print(MyFunctionalInterface myFunctionalInterface){
myFunctionalInterface.method1();
}
public static void main(String[] args) {
// 1.使用方式一:实现类方式
print(new MyFunctionalInterfaceImpl());
// 2.使用方式二:使用匿名内部类方式
print(new MyFunctionalInterface() {
@Override
public void method1() {
System.out.println("使用匿名内部类方式实现抽象方法");
}
});
// 3.使用方式三:使用Lambda表达式
print(() -> System.out.println("使用Lambda实现抽象方法"));
}
}
3.3 JDK内置的函数式接口
3.3.1 Supplier接口
Supplier 接口是java.util.function包下的一个函数式接口,该接口的抽象方法是一个无参的方法:T get() ,用来获取一个泛型参数指定类型的对象数据。
使用Supplier接口案例一:
import java.util.function.Supplier;
public class Demo2 {
private static String getString(Supplier<String> supplier) {
return supplier.get();
}
public static void main(String[] args) {
String str1 = "Hello";
String str2 = "World";
System.out.println(getString(() ‐> str1 + str2));
}
}
使用Supplier接口案例二:
public class Demo3 {
public static int getMax(Supplier<Integer> supplier){
return supplier.get();
}
public static void main(String[] args) {
int arr[] = {
1,3,100,300,10,30};
int maxNum = getMax(()‐>{
//计算数组的最大值
int max = arr[0];
for(int i : arr){
f(i > max){
max = i;
}
}
return max;
});
System.out.println(maxNum);
}
}
3.3.2 Consumer接口
Consumer 接口则正好与Supplier接口相反,它不是生产一个数据,而是消费一个数据,其数据类型由泛型决定。 它提供了一个抽象方法:void accept(T t) ,作用是使用一个指定泛型的数据。
import java.util.function.Consumer;
/**
* @author RuiMing Lin
* @date 2020-03-19 0:14
*/
public class ConsumerTest {
private static void consumeString(String string, Consumer<String> consumer) {
consumer.accept(string);
}
public static void main(String[] args) {
String str = "123456789";
consumeString(str, (s) -> {
StringBuffer reverse = new StringBuffer(s).reverse();
System.out.println("reverse = " + reverse);
});
}
}
3.3.3 Predicate接口
Predicate 接口用来对某种类型的数据进行判断,该接口包含一个抽象方法:boolean test(T t) 。
import java.util.function.Predicate;
/**
* @author RuiMing Lin
* @date 2020-03-19 0:26
*/
public class PredicateTest {
private static void method(String string, Predicate<String> predicate) {
boolean flag = predicate.test(string);
if (flag){
System.out.println("该字符串长度大于10");
}else {
System.out.println("该字符串长度不大于10");
}
}
public static void main(String[] args) {
String string = "abcde123456789";
method(string,s -> {
return s.length() > 10;
});
}
}
此外,Predicate接口还提供了三个默认方法,and()、or()、negate()
and()使用方式如下:
import java.util.function.Predicate;
/**
* @author RuiMing Lin
* @date 2020-03-19 0:26
*/
public class PredicateTest {
private static void method(String string, Predicate<String> predicate1, Predicate<String> predicate2) {
boolean flag = predicate1.and(predicate2).test(string);
if (flag){
System.out.println("该字符串长度大于10且小于等于20");
}
}
public static void main(String[] args) {
String string = "abcde123456789";
method(string,s -> {
return s.length() > 10;
},s -> {
return s.length() <= 20;
});
}
}
or()使用方式如下
import java.util.function.Predicate;
/**
* @author RuiMing Lin
* @date 2020-03-19 0:26
*/
public class PredicateTest {
private static void method(String string, Predicate<String> predicate1, Predicate<String> predicate2) {
boolean flag = predicate1.or(predicate2).test(string);
if (flag){
System.out.println("该字符串长度大于10或者小于等于5");
}
}
public static void main(String[] args) {
String string = "123";
method(string,s -> {
return s.length() > 10;
},s -> {
return s.length() <= 5;
});
}
}
negate()使用方式如下
import java.util.function.Predicate;
/**
* @author RuiMing Lin
* @date 2020-03-19 0:26
*/
public class PredicateTest {
private static void method(String string, Predicate<String> predicate) {
boolean flag = predicate.negate().test(string); // 对原结果取非
if (flag){
System.out.println("该字符串长度不大于10");
}
}
public static void main(String[] args) {
String string = "123";
method(string,s -> {
return s.length() > 10;
});
}
}
3.3.4 Function接口
Function<T,R> 接口用来根据一个类型的数据得到另一个类型的数据,前者称为前置条件,后者称为后置条件。 Function 接口提供的抽象方法为: R apply(T t) ,根据类型T的参数获取类型R的结果。
import java.util.function.Function;
/**
* @author RuiMing Lin
* @date 2020-03-19 0:40
*/
public class FunctionTest {
private static void method(String numStr,Function<String, Integer> function) {
// 将数字字符串转化为integer类型
int num = function.apply(numStr);
System.out.println(num + 20);
}
public static void main(String[] args) {
method("100",(str) -> {
return Integer.parseInt(str);
});
}
}
3.3.5 其他内置函数式接口
通过查看java.util.function包下的接口,发现还有一系列其他的函数式接口,但用法与上述常用的函数式接口大同小异。
4 方法引用
4.1 什么是方法引用
当要传递给Lambda表达式的方法体已经有实现了,便可以使用方法引用!方法引用可以看做是Lambda表达式的更深层次的表达。换句话说,方法引用就是Lambda表达式,也就是函数式接口的一个实例,通过方法的名字来指向一个方法,可以认为是Lambda表达式的一个语法糖。
4.2 方法引用实战
4.2.1 对象的实例方法
使用jdk的类的实例方法(非静态方法)
@Test
public void test1(){
// 1.使用Lambda表达式
Consumer<String> consumer1 = (str) -> {
System.out.println(str);
};
consumer1.accept("使用Lambda表达式");
// 2.使用方法引用
PrintStream ps = System.out;
Consumer<String> consumer2 = ps::println;
consumer2.accept("使用方法引用");
}
使用自定义类的实例方法(非静态方法)
@Test
public void test2(){
// 1.使用Lambda表达式
Student student = new Student("小明", 23);
Function<Student, String> function1 = (stu) -> {
return stu.getName();
};
String name1 = function1.apply(student);
System.out.println("name1 = " + name1);
// 2.使用方法引用
Function<Student, String> function2 = Student::getName;
String name2 = function2.apply(student);
System.out.println("name2 = " + name2);
}
4.2.2 类的静态方法
@Test
public void test3(){
// 1.使用Lambda表达式
Comparator<Integer> comparator1 = (t1,t2) -> {
return Integer.compare(t1, t2);
};
int result1 = comparator1.compare(5, 13);
System.out.println("result1 = " + result1);
// 2.使用方法引用
Comparator<Integer> comparator2 = Integer::compareTo;
int result2 = comparator2.compare(5, 13);
System.out.println("result2 = " + result2);
}
4.2.3 类的实例方法
@Test
public void test4() {
// 1.使用Lambda表达式
Comparator<String> comparator1 = (s1, s2) -> {
return s1.compareTo(s2);
};
int result1 = comparator1.compare("abc", "cba");
System.out.println("result1 = " + result1);
// 2.使用方法引用
Comparator<String> comparator2 = String::compareTo;
int result2 = comparator2.compare("abc", "cba");
System.out.println("result2 = " + result2);
}
4.2.4 构造器引用
无参数构造器的引用
@Test
public void test5() {
// 1.使用Lambda表达式
Supplier<Student> supplier1 = () -> {
return new Student(); // 使用无参数构造器创建一个学生对象
};
Student student1 = supplier1.get();
student1.setName("小明");
student1.setAge(12);
System.out.println("student1 = " + student1);
// 2.使用方法引用
Supplier<Student> supplier2 = Student::new;
Student student2 = supplier2.get();
student2.setName("小红");
student2.setAge(13);
System.out.println("student2 = " + student2);
}
有参数构造器的引用:根据传入的参数类型以及数量确定所使用的构造器是哪一个
@Test
public void test6(){
// 1.使用Lambda表达式
BiFunction<String, Integer, Student> biFunction1 = (name, age) -> {
return new Student(name, age); // 使用有参数构造器创建一个学生对象
};
Student student1 = biFunction1.apply("小明", 23);
System.out.println("student1 = " + student1);
// 2.使用方法引用
BiFunction<String, Integer, Student> biFunction2 = Student::new;
Student student2 = biFunction2.apply("小红", 24);
System.out.println("student2 = " + student2);
}
5 Stream
5.1 Stream流的介绍
Java 8新增了Lambda表达式,于是也带来了函数式接口。同时,还带来了一种简化编程的stream流式编程。一定要清楚,stream流和IO stream流 一!点!关!系!都!没!有!
5.2 Stream流的引入
可以用工厂的流水线生产来比喻Stream流编程,一般一个产品需要多步加工操作,通过流水线可以大大提高生产效率。同理,使用stream流进行编程,可以大大简化我们的开发难度。Stream流编程可以总结出三个特点:①Stream 自己不会存储元素;②Stream 不会改变源对象。相反,他们会返回一个持有结果的新Stream; ③Stream 操作是延迟执行的,这意味着他们会等到需要结果的时候才执行。
下面以一个小案例为例子,看一看Stream流编程和传统的集合操作比较有什么优点:
案例:找出列表中姓夏侯且姓名长度为3的名字
5.2.1 传统方式实现:
import java.util.ArrayList;
/**
* @author RuiMing Lin
* @date 2020-03-19 12:22
*/
public class Demo1 {
public static void main(String[] args) {
// 1.定义一个列表
ArrayList<String> list = new ArrayList<>();
list.add("刘备");
list.add("关羽");
list.add("张飞");
list.add("诸葛亮");
list.add("夏侯惇");
list.add("夏侯渊");
list.add("夏侯嘉正");
// 2.挑选姓夏侯的
ArrayList<String> list1 = new ArrayList<>();
for (String s : list) {
if (s.startsWith("夏侯")){
list1.add(s);
}
}
// 3.挑选名字长度为3的
ArrayList<String> list2 = new ArrayList<>();
for (String s : list1) {
if (s.length() == 3){
list2.add(s);
}
}
// 4、遍历
for (String s : list2) {
System.out.println("s = " + s);
}
}
}
5.2.2 stream流实现:
import java.util.ArrayList;
/**
* @author RuiMing Lin
* @date 2020-03-19 12:22
*/
public class Demo1 {
public static void main(String[] args) {
// 1.定义一个列表
ArrayList<String> list = new ArrayList<>();
list.add("刘备");
list.add("关羽");
list.add("张飞");
list.add("诸葛亮");
list.add("夏侯惇");
list.add("夏侯渊");
list.add("夏侯嘉正");
list.stream()
.filter((name) -> {
return name.startsWith("夏侯"); })
.filter((name) -> {
return name.length() == 3;})
.forEach((name) -> {
System.out.println("name = " + name);
});
}
}
可以看出使用Stream流编程不仅可以简化代码,而且语义会更清晰,如果你写了一堆逻辑代码,阅读起来或许很不方便。而使用Stream流编程便可以见函数名而知意,比如使用filter函数就可以知道是用来过滤数据的,也就是筛选满足要求的数据,使用foreach函数就知道是用来遍历集合的。
5.3 Stream流的常用API
5.3.1 Stream流的获取
Stream流的获取有四种方法,第一种方法是单列集合(Collection体系的类)均有一个stream()或者是一个parallelStream(),二者的区别是前者返回一个串行流,后者返回一个并行流(关于并行流会在5.4节详细描述),二者的区别见如下代码:
import org.junit.Test;
import java.util.ArrayList;
import java.util.stream.Stream;
/**
* @author RuiMing Lin
* @date 2021-01-19 22:43
* @description
*/
public class StreamDemo {
@Test
public void test1(){
ArrayList<String> list = new ArrayList<>();
list.add("刘备");
list.add("关羽");
list.add("张飞");
list.add("诸葛亮");
list.add("曹操");
list.add("孙权");
list.add("孙尚香");
list.add("夏侯惇");
list.add("夏侯渊");
list.add("夏侯嘉正");
// 1.使用串行流
Stream<String> stream = list.stream();
stream.forEach((name) -> {
System.out.println("name = " + name);
});
System.out.println("----------华丽分隔符------------");
// 2.使用并行流
Stream<String> parallelStream = list.parallelStream();
parallelStream.forEach((name) -> {
System.out.println("name = " + name);
});
}
}
输出结果因为并行流是基于多线程的,通俗而言是将集合分配到多个线程异步执行,所以输出结果与串行流不一定相同:

第二种方法是使用数组工具类Arrays的steam(),如果是基本数据类型的数组则会产生一个xxxStream对象,如果是引用数据类型的话则会产生一个Stream对象,具体代码如下:
@Test
public void test2() {
int[] arr = {
1, 3, 5, 7, 2, 4, 6};
IntStream intStream = Arrays.stream(arr);
intStream.forEach((num) -> {
System.out.println("num = " + num);
});
Student[] students = {
new Student("小明", 23),
new Student("小红", 24)
};
Stream<Student> studentStream = Arrays.stream(students);
studentStream.forEach((stu) -> {
System.out.println("stu = " + stu);
});
}
第三种方法是使用Stream类的静态方法of()创建流对象,具体代码如下:
@Test
public void test3() {
Stream<Integer> intStream = Stream.of(1, 3, 5, 7, 2, 4, 6);
intStream.forEach((num) -> {
System.out.println("num = " + num);
});
}
第四种方法是创建一个无限流,创建一个无限流可以使用Stream类的iterate()或者generate(),iterate()需要传入一个种子,也就是初始值,还有一个UnaryOperator接口,该接口继承了Function接口。generate()则需要传入一个Supplier接口的实现类。具体代码如下:
@Test
public void test4() {
// 1.iterate 生成偶数无限流,需要手动停止
// Stream.iterate(0, (t) -> t+2).forEach(System.out::println);
// 2.iterate 生成10个偶数
Stream.iterate(0, (t) -> t+2).limit(10).forEach(System.out::println);
// 3.generate
Stream.generate(Math::random).limit(10).forEach(System.out::println);
}
5.3.2 中间操作
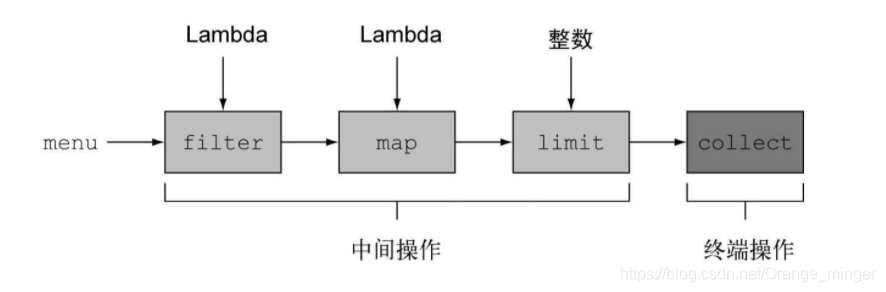
像filter或sorted等中间操作会返回另一个流。这让多个操作可以连接起来形成一个查询。重要的是,除非流水线上触发一个终端操作,否则中间操作不会执行任何处理——它们很懒(延迟加载)。这是因为中间操作一般都可以合并起来,在终端操作时一次性全部处理。
Stream的中间操作大致可以分为三类,①筛选和切片,主要有filter(),distinct(),limit(),skip();②映射方法,主要有map(),flatMap();③排序,主要有sorted()。下面对这些方法进行代码演示:
5.3.2.1 filter()
@Test
public void test5() {
// 中间操作1:filter(),传入一个predicate实例,如果为True就进入一个stream
ArrayList<String> list = new ArrayList<>();
list.add("刘备");
list.add("夏侯惇");
list.add("夏侯渊");
list.add("夏侯嘉正");
Stream<String> stream = list.stream().filter((name) -> name.startsWith("夏侯")); // 中间操作,生成一个新流
stream.forEach(System.out::println); // 使用终止操作,查看流的结果
}
5.3.2.2 limit()
@Test
public void test6() {
// 中间操作2:limit(),截断流,使元素不超过指定的n数量
ArrayList<String> list = new ArrayList<>();
list.add("刘备");
list.add("夏侯惇");
list.add("夏侯渊");
list.add("夏侯嘉正");
Stream<String> stream = list.stream().limit(2); // 中间操作,只获得前两个
stream.forEach(System.out::println); // 使用终止操作,查看流的结果
}
5.3.2.3 skip()
@Test
public void test7() {
// 中间操作3:skip(),跳过指定数量的流
ArrayList<String> list = new ArrayList<>();
list.add("刘备");
list.add("夏侯惇");
list.add("夏侯渊");
list.add("夏侯嘉正");
Stream<String> stream = list.stream().skip(1); // 中间操作,跳过第一个
stream.forEach(System.out::println); // 使用终止操作,查看流的结果
}
5.3.2.4 distinct()
@Test
public void test8() {
// 中间操作4,distinct(),根据元素的hashcode和equals去除重复元素
ArrayList<String> list = new ArrayList<>();
list.add("刘备");
list.add("刘备");
list.add("刘备");
list.add("夏侯惇");
list.add("夏侯渊");
list.add("夏侯嘉正");
Stream<String> stream = list.stream().distinct();
stream.forEach(System.out::println);
}
5.3.2.5 map()
map()是对每一个元素做一次映射,然后生成一个新的流。
比如实现字符串的小写字符转化为大写字母:
@Test
public void test9() {
// 中间操作5,map(),对每一个元素进行映射
ArrayList<String> list = new ArrayList<>();
list.add("aa");
list.add("bb");
list.add("cc");
Stream<String> stream = list.stream().map((str) -> str.toUpperCase());
stream.forEach(System.out::println);
}
@Test
public void test10() {
// 中间操作5,map(),对每一个元素进行映射
ArrayList<String> list = new ArrayList<>();
list.add("aa");
list.add("bb");
list.add("cc");
Stream<String> stream = list.stream().map(String::toUpperCase);
stream.forEach(System.out::println);
}
5.3.2.6 flapMap()
map()方法很好理解,就是将原来的流中的每一个元素做一次映射变为新的元素放进新的流中。但是flapMap()就有点不好理解了,flapMap()接收一个函数作为参数,将流中的每个值都换成另一个流,然后把所有流连接成一个流,这样解释其实有点拗口,所以以下图为例。
现在有一个需求:**对于一张单词表,如何返回一张列表,列出里面各不相同的字符呢?例如,给定单词列表[“Hello”, “World”],你想要返回列表[“H”, “e”, “l”, “o”, “W”, “r”, “d”]。**如果使用Map()方法,对每一个单词先进行字符切割,然后使用distinct去重,结果并不能得到想要的结果。
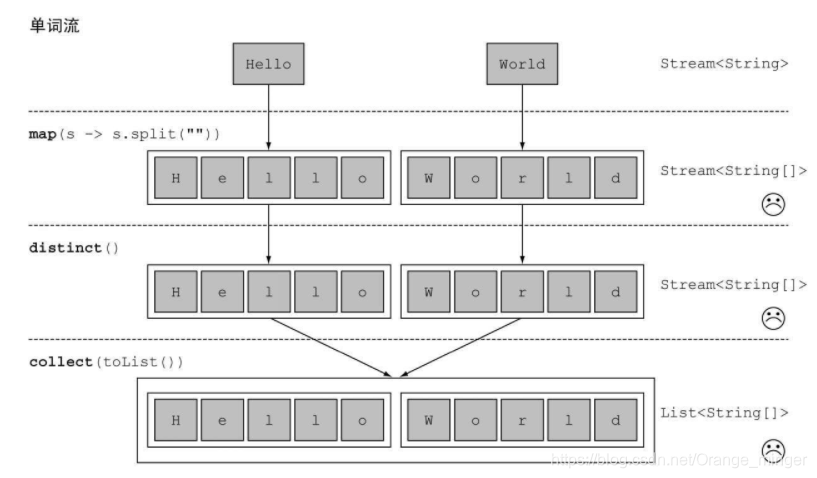
如果使用flapMap(),各个数组并不是分别映射成一个流,而是映射成流的内容。所有使用map(Arrays::stream)时生成的单个流都被合并起来,即扁平化为一个流。
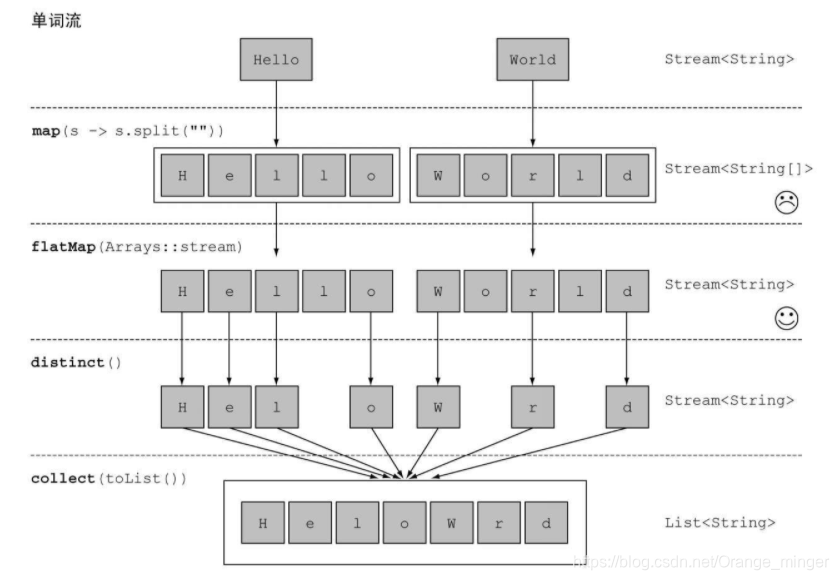
@Test
public void test11() {
// 中间操作5,flapMap(),扁平化映射
ArrayList<String> list = new ArrayList<>();
list.add("hello");
list.add("world");
Stream<String> stream = list.stream().map((word) -> word.split(""))
.flatMap(Arrays::stream)
.distinct();
stream.forEach(System.out::println);
}
5.3.2.7 sorted()
sorted()可以不传任何参数,即按照默认方式排序,也可以传入一个比较器comparator,按照比较器的方式进行比较,下面代码演示两种情况:
@Test
public void test12() {
// 中间操作5,sorted()
ArrayList<Integer> list = new ArrayList<>();
list.add(27);
list.add(7);
list.add(777);
Stream<Integer> stream = list.stream().sorted();
stream.forEach(System.out::println);
}
传入一个比较器
@Test
public void test13() {
// 中间操作5,sorted()
ArrayList<Student> list = new ArrayList<>();
list.add(new Student("小明",23));
list.add(new Student("小红",16));
list.add(new Student("小琦",27));
Stream<Student> stream = list.stream().sorted((stu1, stu2) -> {
return Integer.compare(stu1.getAge(), stu2.getAge());
});
stream.forEach(System.out::println);
}
5.3.3 终止操作
终止操作返回的都不再是stream类型的了,可以是基本数据类型,也可以是void类型。终止操作包括①查找和匹配,主要有allMatch()、anyMatch()、noneMatch()、findFirst()和findAny();②归约,主要有reduce()
5.3.3.1 匹配
@Test
public void test14(){
// 终止操作。allMatch(Predicate p),anyMatch(Predicate p),noneMatch(Predicate p)
// findFirst(),findAny()
ArrayList<Student> list = new ArrayList<>();
list.add(new Student("小明",23));
list.add(new Student("小红",16));
list.add(new Student("小琦",27));
boolean b1 = list.stream().allMatch(student -> student.getAge() > 20);
System.out.println("是否均大于20岁 = " + b1);
boolean b2 = list.stream().anyMatch(student -> student.getAge() > 20);
System.out.println("是否有人大于20岁 = " + b2);
boolean b = list.stream().noneMatch(student -> student.getAge() < 17);
System.out.println("没有人小于17岁,对吗" + b);
Optional<Student> first = list.stream().findFirst();
System.out.println("first = " + first);
Optional<Student> any = list.stream().findAny();
System.out.println("any = " + any);
}
5.3.3.2 统计
@Test
public void test15(){
// 终止操作。count(),max(),min()
ArrayList<Student> list = new ArrayList<>();
list.add(new Student("小明",23));
list.add(new Student("小红",16));
list.add(new Student("小琦",27));
long count = list.stream().filter(student -> student.getAge() > 20).count();
System.out.println("大于20岁的学生有多少人= " + count);
Optional<Integer> max = list.stream().map(student -> student.getAge()).max(Integer::compareTo);
System.out.println("学生最大岁数 = " + max.get());
Optional<Integer> min = list.stream().map(student -> student.getAge()).min(Integer::compareTo);
System.out.println("学生最小岁数 = " + min.get());
}
5.3.3.3 规约
归约,也就是reduce(),这个方法与map()结合的思想和hadoop的MapReduce的思想是一致的,先对数据做映射,然后再做规约。
比如求a-f的ASCII码之和:
@Test
public void test16() {
Character[] bet = {
'a', 'b', 'c', 'd', 'e', 'f', 'g' };
Integer sum = Arrays.stream(bet).map(character -> (int) character) // 先将字符转化为ASCII码
.reduce(0, Integer::sum); // 再将ASCII码相加,0表示第一个被加数
System.out.println("sum = " + sum);
}
5.3.3.4 收集
收集是将流转换为其他形式,如list或者map,使用的是collect(),接收一个 Collector接口的实现,用于给Stream中元素做汇总的方法。
wordCount是Hadoop乃至大数据学习的helloworld,下面使用collect()和其它函数来实现wordcount:
@Test
public void test17(){
String str1 = "I love China.";
String str2 = "I am a Chinese.";
String str3 = "I hope i will be a greater Chinese!";
String str4 = "China is a peace-loving country!";
Stream<String> stream = Stream.of(str1, str2, str3, str4);
Map<String, Long> collect = stream.map(str -> str.replaceAll("[,]|[.]|[!]", " ")) // 字符替换,将标点符号转化为空格
.map(str -> str.toLowerCase().split(" ")) // 字符串切割
.flatMap(Arrays::stream) // 扁平化
.collect(Collectors.groupingBy(String::toString, Collectors.counting()));
collect.forEach((k,v) -> {
System.out.println(k + "...." + v);
});
}
Collectors还有很多其它的静态方法,具体如下:


5.4 并行流
5.4.1 Java7之前
在Java 7之前,并行处理数据集合非常麻烦。第一,你得明确地把包含数据的数据结构分成若干子部分。第二,你要给每个子部分分配一个独立的线程。第三,你需要在恰当的时候对它们进行同步来避免不希望出现的竞争条件,等待所有线程完成,最后把这些部分结果合并起来。
5.4.2 Java7
Java 7引入了一个叫作分支/合并(Fork/Join)的框架,让这些操作更稳定、更不易出错。分支/合并框架的目的是以递归方式将可以并行的任务拆分成更小的任务,然后将每个子任务的结果合并起来生成整体结果。它是ExecutorService接口的一个实现,它把子任务分配给线程池(称为ForkJoinPool)中的工作线程。
5.4.3 Java8
5.4.3.1 如何使用并行流
如前面提到的,使用stream()可以得到一个串行流,而使用parallelStream()可以得到一个并行流,并行流可以通过开启多个线程并行计算从而提到计算效率。下面以一段求和代码为例:
@Test
public void test18() {
long start1 = System.currentTimeMillis();
Stream.iterate(1L, i -> i+1)
.limit(10000000)
.reduce(0L,Long::sum);
long end1 = System.currentTimeMillis();
System.out.println("串行执行运行时间: " + (end1 - start1) + "ms");
// 可以通过设置全局系统属性java.util.concurrent.ForkJoinPool.common.parallelism来控制并行度
String parallelismNum1 = System.getProperty("java.util.concurrent.ForkJoinPool.common.parallelism");
System.out.println("parallelismNum1 = " + parallelismNum1);
System.setProperty("java.util.concurrent.ForkJoinPool.common.parallelism","6"); // 将线程数设置为8,这个数应该和你的CPU息息相关
String parallelismNum2 = System.getProperty("java.util.concurrent.ForkJoinPool.common.parallelism");
System.out.println("parallelismNum2 = " + parallelismNum2);
long start2 = System.currentTimeMillis();
Stream.iterate(1L, i -> i+1)
.parallel()
.limit(10000000)
.reduce(0L,Long::sum);
long end2 = System.currentTimeMillis();
System.out.println("并行执行运行时间: " + (end2 - start2) + "ms");
}
结果如下:

可以看出,使用并行流反而更慢了!分析其原因主要有几点:①iterate生成的是装箱的对象,必须拆箱成数字才能求和;② 我们很难把iterate分成多个独立块来并行执行;③在计算复杂度不高的情况下,线程上下文切换反而更浪费时间。 因此我们修改了针对性的代码:
@Test
public void test19() {
long start1 = System.currentTimeMillis();
LongStream.rangeClosed(1, 10000000)
.reduce(0L,Long::sum);
long end1 = System.currentTimeMillis();
System.out.println("串行执行运行时间: " + (end1 - start1) + "ms");
// 可以通过设置全局系统属性java.util.concurrent.ForkJoinPool.common.parallelism来控制并行度
String parallelismNum1 = System.getProperty("java.util.concurrent.ForkJoinPool.common.parallelism");
System.out.println("parallelismNum1 = " + parallelismNum1);
System.setProperty("java.util.concurrent.ForkJoinPool.common.parallelism","12"); // 将线程数设置为8,这个数应该和你的CPU息息相关
String parallelismNum2 = System.getProperty("java.util.concurrent.ForkJoinPool.common.parallelism");
System.out.println("parallelismNum2 = " + parallelismNum2);
long start2 = System.currentTimeMillis();
LongStream.rangeClosed(1, 10000000)
.parallel()
.reduce(0L,Long::sum);
long end2 = System.currentTimeMillis();
System.out.println("并行执行运行时间: " + (end2 - start2) + "ms");
}
结果如下:

5.4.3.2 高效使用并行流的建议
- 把顺序流转成并行流轻而易举,但却不一定是好事,因为并行流并不总是比顺序流快。此外,并行流有时候会和你的直觉不一致,所以在考虑选择顺序流还是并行流时,第一个也是最重要的建议就是用适当的基准来检查其性能。
- 留意装箱。自动装箱和拆箱操作会大大降低性能。Java 8中有原始类型流(IntStream、LongStream、DoubleStream)来避免这种操作,但凡有可能都应该用这些流。
- 有些操作本身在并行流上的性能就比顺序流差。特别是limit和findFirst等依赖于元素顺序的操作,它们在并行流上执行的代价非常大。例如,findAny会比findFirst性能好,因为它不一定要按顺序来执行。你总是可以调用unordered方法来把有序流变成无序流。那么,如果你需要流中的n个元素而不是专门要前n个的话,对无序并行流调用limit可能会比单个有序流(比如数据源是一个List)更高效。
- 还要考虑流的操作流水线的总计算成本。设N是要处理的元素的总数,Q是一个元素通过流水线的大致处理成本,则N*Q就是这个对成本的一个粗略的定性估计。Q值较高就意味着使用并行流时性能好的可能性比较大。
- 对于较小的数据量,选择并行流几乎从来都不是一个好的决定。并行处理少数几个元素的好处还抵不上并行化造成的额外开销。
- 要考虑流背后的数据结构是否易于分解。例如,ArrayList的拆分效率比LinkedList高得多,因为前者用不着遍历就可以平均拆分,而后者则必须遍历。另外,用range工厂方法创建的原始类型流也可以快速分解。
- 流自身的特点,以及流水线中的中间操作修改流的方式,都可能会改变分解过程的性能。例如,一个SIZED流可以分成大小相等的两部分,这样每个部分都可以比较高效地并行处理,但筛选操作可能丢弃的元素个数却无法预测,导致流本身的大小未知。
- 还要考虑终端操作中合并步骤的代价是大是小(例如Collector中的combiner方法)。如果这一步代价很大,那么组合每个子流产生的部分结果所付出的代价就可能会超出通过并行流得到的性能提升。
- 最后,如果是ArrayList、基本数据类型的话使用并行流是极佳的;如果是HashSet、TreeSet,也同样建议使用并行流。如果是链表、iterate无限流,不建议使用并行流,因为有很多限制因素。
6 接口的默认方法和静态方法
在Java8中,接口可以定义默认方法和静态方法了,这极大地丰富了接口的功能,同时也让接口看起来有点像一个普通类了。
interface Animal {
//抽象方法
public void doSomething();
//默认方法
default void defaultMethod1() {
System.out.println("I can breath");
}
//默认方法可以有多个
default void DefaultMethod2() {
System.out.println("I can fly");
}
//静态方法
static void staticMethod1() {
System.out.println("animal...static_1");
}
//静态方法也可以有多个
static void StaticMethod2() {
System.out.println("animal...static_2");
}
}
特点:
- 可以有多个默认方法
- 可以有多个静态方法
- 默认方法可以重写
- 静态方法不可以重写
7 新的时间日期API
7.1 Java8之前
7.1.1 Date类
Date类是JDK1.0就出现的类,时代久远,大部分方法都已经弃用了,因为有更好的方法代替了。
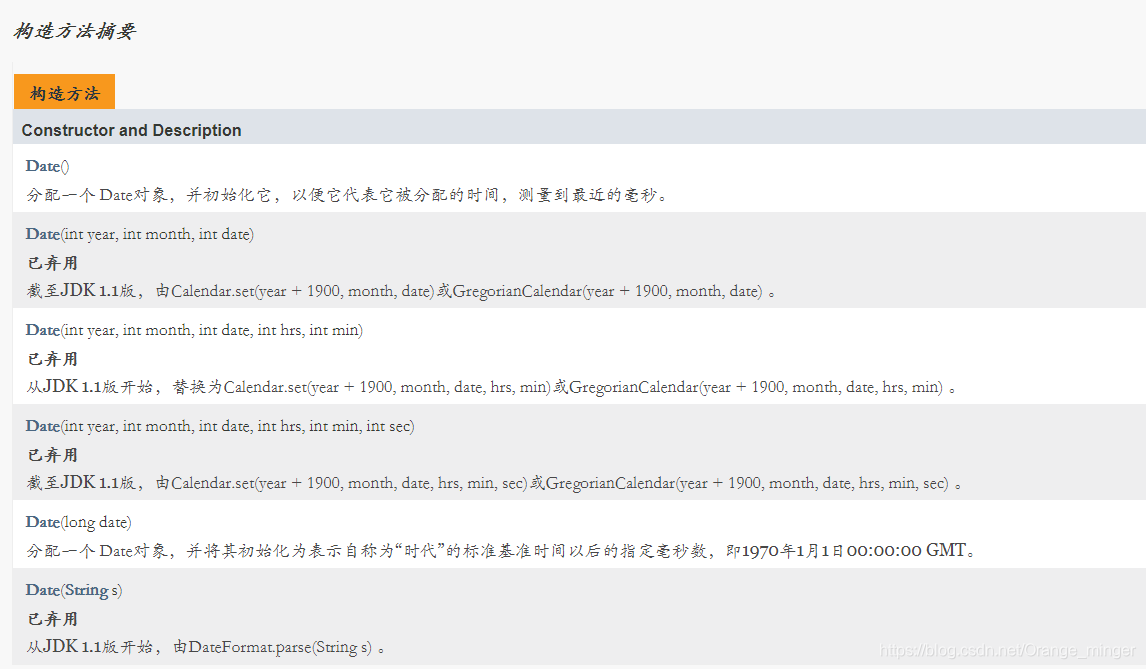
从图中可以看出,构造方法只有两个没有被标记为弃用,具体使用代码如下:
@Test
public void test1(){
// 分配一个 Date对象,并初始化它,以便它代表它被分配的时间,测量到最近的毫秒。
Date date1 = new Date();
System.out.println("date1 = " + date1);
//分配一个 Date对象,并将其初始化为表示自称为“时代”的标准基准时间以后的指定毫秒数,即1970年1月1日00:00:00 GMT。
Date date2 = new Date(1000 * 60 * 60 * 24);
System.out.println("date2 = " + date2);
// getTime()
long time = date2.getTime();
System.out.println("time = " + time);
}
7.1.2 SimpleDateFormat类
SimpleDateFormat是一个具体的类,用于以区域设置敏感的方式格式化和解析日期。 它允许格式化(日期文本),解析(文本日期)和归一化。对于格式,需要重点记住几个常用的,见下图红色方框内:

具体使用方法如下
@Test
public void test2() throws ParseException {
// 格式化日期
Date date = new Date();
String strDateFormat = "yyyy-MM-dd HH:mm:ss";
SimpleDateFormat sdf = new SimpleDateFormat(strDateFormat);
System.out.println(sdf.format(date));
// 解析日期
String dateStr = "2021-01-21 16:21:46";
Date parse = sdf.parse(dateStr);
System.out.println("parse = " + parse);
}
7.1.3 Calendar类
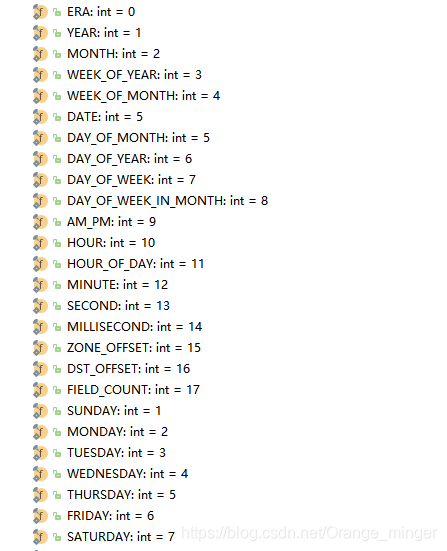
Calendar类是一个抽象类,意思是日历。可以为在某一特定时刻和一组之间的转换的方法calendar fields如YEAR、MONTH 、DAY_OF_MONTH、HOUR 等等,以及用于操纵该日历字段,如获取的日期下个星期。时间上的瞬间可以用毫秒值表示,该值是从1970年1月1日00:00 00:00.000 GMT(Gregorian)的Epoch的偏移量。该类还提供了用于在包外部实现具体日历系统的其他字段和方法。 这些字段和方法定义为protected 。与其他区域设置敏感的类一样,Calendar提供了一种类方法getInstance,用于获取此类型的一般有用的对象。
Calendar类有很多字段,表示一个日历上常见的属性。
7.1.3.1 获取Calendar对象
Calendar是一个抽象类,所以无法对其进行实例化。通常是使用静态方法getInstance()来获得其实例对象。getInstance()有几个重载方法,区别可以设置指定时区和区域设置的日历。


然后通过TimeZone和Locale的不同再去调用createCalendar():
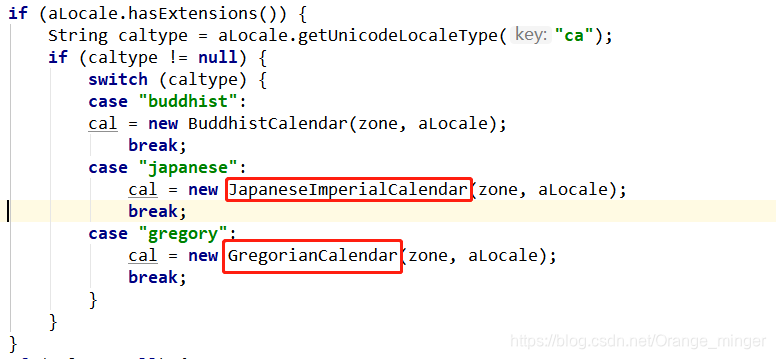
最后会调用Calendar类的实现类
7.1.3.2 使用Calendar对象
使用Calendar 获取年、月、日、时、分、秒
@Test
public void test3() {
Calendar calendar = Calendar.getInstance();
int year = calendar.get(Calendar.YEAR);
int month = calendar.get(Calendar.MONTH) + 1;
int date = calendar.get(Calendar.DATE);
int hour = calendar.get(Calendar.HOUR_OF_DAY);
int minute = calendar.get(Calendar.MINUTE);
int second = calendar.get(Calendar.SECOND);
System.out.println(String.format("现在时间为%d/%d/%d %d:%d:%d", year,month,date,hour,minute,second));
}
7.1.3.3 修改Calendar对象
修改calendar的时间:
@Test
public void test4(){
Calendar calendar = Calendar.getInstance();
calendar.add(Calendar.YEAR, -1); // 将时间修改为一年期
System.out.println(calendar.getTime());
calendar.add(Calendar.MONTH,2); //将时间修改2个月后
System.out.println(calendar.getTime());
int year = calendar.get(Calendar.YEAR);
int month = calendar.get(Calendar.MONTH) + 1;
int date = calendar.get(Calendar.DATE);
int hour = calendar.get(Calendar.HOUR_OF_DAY);
int minute = calendar.get(Calendar.MINUTE);
int second = calendar.get(Calendar.SECOND);
System.out.println(String.format("现在时间为%d/%d/%d %d:%d:%d", year,month,date,hour,minute,second));
}
设置calendar的时间:
@Test
public void test5(){
Calendar calendar = Calendar.getInstance();
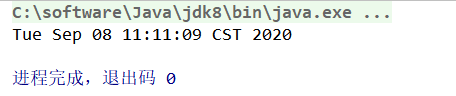
calendar.set(2020, 8, 8, 11, 11);
System.out.println(calendar.getTime());
}
注意,月份设置为8,但是输出是September(9月)
7.2 Java8
7.2.1 为什么需要java.time包
Java原本自带的java.util.Date和java.util.Calendar类,实际上两种类有线程不安全的风险,并且还有使用上不方便的特点,所以Java8推出了新的时间类库的java.time。
出现的问题包括:①毫秒值与日期直接转换比较繁琐,其次通过毫秒值来计算时间的差额步骤较多;②API线程不安全问题;③可以使用数字设置时间而没有使用枚举类,不符合开发规范(不允许使用没有经过定义的魔法数字)。
7.2.2 java.time包常用类
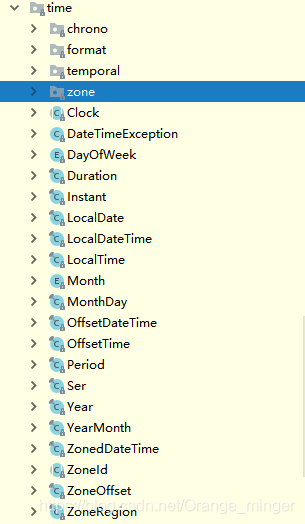
- Instant类:Instant类对时间轴上的单一瞬时点建模,可以用于记录应用程序中的事件时间戳,之后学习的类型转换中,均可以使用Instant类作为中间类完成转换。
- Duration类:Duration类表示秒或纳秒时间间隔,适合处理较短的时间,需要更高的精确性。
- Period类:Period类表示一段时间的年、月、日。
- LocalDate类:LocalDate是一个不可变的日期时间对象,表示日期,通常被视为年月日。
- LocalTime类:LocalTime是一个不可变的日期时间对象,代表一个时间,通常被看作是小时-秒,时间表示为纳秒精度。
- LocalDateTime类:LocalDateTime类是一个不可变的日期时间对象,代表日期时间,通常被视为年-月-日=时-分-秒。
- ZonedDateTime类:ZonedDateTime是具有时区的日期时间的不可变表示,此类存储所有日期和时间字段,精度为纳秒,时区为区域偏移量,用于处理模糊的本地日期时间。
7.2.3 now()
time包的时间类都包含一个now方法,获取当前时间,只是表示方式不同。
@Test
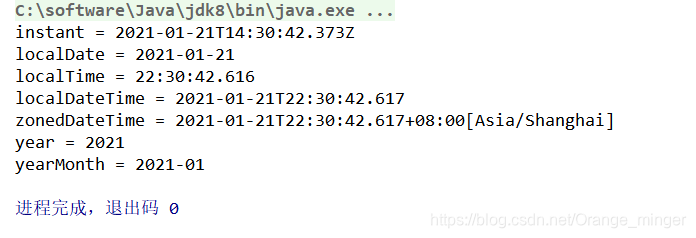
public void test6(){
Instant instant = Instant.now();
System.out.println("instant = " + instant);
LocalDate localDate = LocalDate.now();
System.out.println("localDate = " + localDate);
LocalTime localTime = LocalTime.now();
System.out.println("localTime = " + localTime);
LocalDateTime localDateTime = LocalDateTime.now();
System.out.println("localDateTime = " + localDateTime);
ZonedDateTime zonedDateTime = ZonedDateTime.now();
System.out.println("zonedDateTime = " + zonedDateTime);
Year year = Year.now();
System.out.println("year = " + year);
YearMonth yearMonth = YearMonth.now();
System.out.println("yearMonth = " + yearMonth);
MonthDay monthDay = MonthDay.now();
System.out.println("monthDay = " + monthDay);
}
结果输出如下:
7.2.4 of()
of方法可以根据给定的参数生成对应的日期/时间对象,基本上每个基本类都有of方法用于生成的对应的对象,而且重载形式多变,可以根据不同的参数生成对应的数据。下面以LocalDateTime类为例:

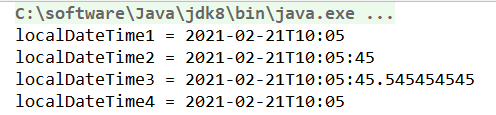
@Test
public void test7(){
LocalDateTime localDateTime1 = LocalDateTime.of(2021, 2, 21, 10, 5);
System.out.println("localDateTime1 = " + localDateTime1);
LocalDateTime localDateTime2 = LocalDateTime.of(2021, 2, 21, 10, 5,45);
System.out.println("localDateTime2 = " + localDateTime2);
LocalDateTime localDateTime3 = LocalDateTime.of(2021, 2, 21, 10, 5,45, 545454545);
System.out.println("localDateTime3 = " + localDateTime3);
LocalDate localDate = LocalDate.of(2021, 2, 21);
LocalTime localTime = LocalTime.of(10, 5);
LocalDateTime localDateTime4 = LocalDateTime.of(localDate, localTime);
System.out.println("localDateTime4 = " + localDateTime4);
}
8 Optional类
8.1 为什么使用Optional
在一个大型的项目里面,总是不可避免的会遇到NullPointerException,也就是空指针异常的情况。在传统的方法中,我们通常会对对象进行判断,如果对象非空,才进行下一步操作。假设现在有三个类:学生类(Stu)、老师类(Teacher)、学校类(School)。学生有一个属性是老师,老师有一个属性是学校,具体代码如下:
import org.junit.Test;
/**
* @author RuiMing Lin
* @date 2021-01-20 23:43
* @description
*/
public class OptionalDemo {
@Test
public void test1(){
// 正常情况下
School school = new School("揭阳第一中学");
Teacher teacher = new Teacher("林老师", school);
Stu stu = new Stu("陈同学", teacher);
// 获取陈同学是哪个学校的
String name = stu.getTeacher().getSchool().getName();
System.out.println("name = " + name);
}
}
class School{
private String name;
public School() {
}
public School(String name) {
this.name = name;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}
class Teacher {
private String name;
private School school;
public Teacher() {
}
public Teacher(String name, School school) {
this.name = name;
this.school = school;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public School getSchool() {
return school;
}
public void setSchool(School school) {
this.school = school;
}
}
class Stu {
private String name;
private Teacher teacher;
public Stu() {
}
public Stu(String name, Teacher teacher) {
this.name = name;
this.teacher = teacher;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Teacher getTeacher() {
return teacher;
}
public void setTeacher(Teacher teacher) {
this.teacher = teacher;
}
}
正常情况下,这样做是没问题的。但是很多情况下,其中很多字段可能是空的,比如数据库中该字段是缺失数据,而我们又是从数据库中查询数据。在传统方法中,我们会使用逻辑判断来增强代码的健壮性,代码如下:
@Test
public void test2(){
Teacher teacher = new Teacher("林老师", null);
Stu stu = new Stu("陈同学", teacher);
// 获取陈同学是哪个学校的
// String name = stu.getTeacher().getSchool().getName(); // 这样做就会报错
Teacher tea = stu.getTeacher();
if (tea != null){
School school = tea.getSchool();
if (school != null){
String name = school.getName();
if (name != null){
System.out.println("name = " + name);
}
}
}
System.out.println("name = " + "未查询到陈同学的学校");
}
这样做的极其不好的,首先是代码冗余,可读性差,难以维护。其次是它自身是毫无意义的,因为null自身没有任何的语义。
8.2 Optional是什么
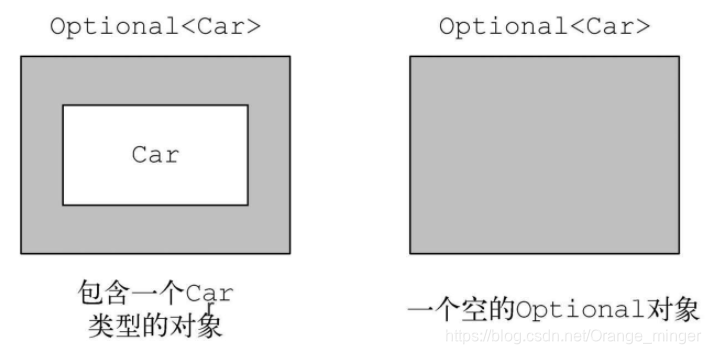
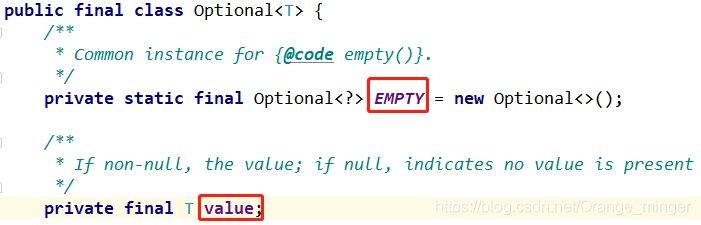
Optional是一个封装Optional值的类。举例来说,使用Optional意味着,如果你知道一个人可能有也可能没有车,那么Person类内部的car变量就不应该声明为Car,遭遇某人没有车时把null引用赋值给它,而是应该直接将其声明为Optional类型。通过看Optional类的源码可以知道,其实Optional可以理解为一个容器,装载着一个T类型的值value,或者可以创建一个空的Optional也就是EMPTY。
8.3 Optional使用
8.3.1 Optional容器的创建
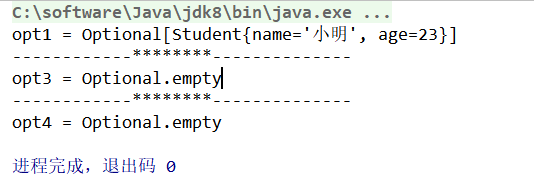
@Test
public void test3(){
/**
* Optional.of(T t) : 创建一个 Optional 实例,t必须非空;
* Optional.empty() : 创建一个空的 Optional 实例
* Optional.ofNullable(T t):t可以为null
*/
Student student = new Student("小明", 23);
Optional<Student> opt1 = Optional.of(student);
System.out.println("opt1 = " + opt1);
System.out.println("------------********--------------");
student = null;
// Optional<Student> opt2 = Optional.of(student); // 会报错,t不可以为null
Optional<Student> opt3 = Optional.ofNullable(student);
System.out.println("opt3 = " + opt3);
System.out.println("------------********--------------");
Optional<Object> opt4 = Optional.empty();
System.out.println("opt4 = " + opt4);
}
结果如下:
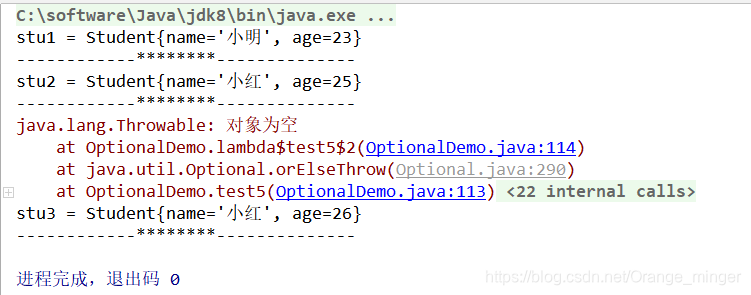
8.3.2 Optional容器的判断方法
@Test
public void test4(){
/**
* 判断Optional容器中是否包含对象:
* boolean isPresent() : 判断是否包含对象
* void ifPresent(Consumer<? super T> consumer) :如果有值,就执行Consumer
* 接口的实现代码,并且该值会作为参数传给它。
*/
Student student = new Student("小明", 23);
Optional<Student> opt1 = Optional.of(student);
boolean b1 = opt1.isPresent();
System.out.println("student是否非空 = " + b1);
System.out.println("------------********--------------");
opt1.ifPresent((stu) -> {
// 如果student非空,则输出student的name
System.out.println(stu.getName());
});
}
8.3.3 Optional容器的判断方法
@Test
public void test5(){
/**
* T get(): 如果调用对象包含值,返回该值,否则抛异常
* T orElse(T other) :如果有值则将其返回,否则返回指定的other对象。
* T orElseGet(Supplier<? extends T> other) :如果有值则将其返回,否则返回由Supplier接口实现提供的对象。
* T orElseThrow(Supplier<? extends X> exceptionSupplier) :如果有值则将其返回,否则抛出由Supplier接口实现提供的异常。
*/
Student student = new Student("小明", 23);
Optional<Student> opt1 = Optional.of(student);
Student stu1 = opt1.get();
System.out.println("stu1 = " + stu1);
System.out.println("------------********--------------");
Optional<Student> opt2 = Optional.empty(); // 创建一个空的optional
Student stu2 = opt2.orElse(new Student("小红", 25));
System.out.println("stu2 = " + stu2);
System.out.println("------------********--------------");
Student stu3 = opt2.orElseGet(() -> {
return new Student("小红", 26);
});
System.out.println("stu3 = " + stu3);
System.out.println("------------********--------------");
try {
Student stu4 = opt2.orElseThrow(() -> {
return new Throwable("对象为空");
});
} catch (Throwable throwable) {
throwable.printStackTrace();
}
}