## ✌✌✌古人有云,好记性不如烂笔头,千里之行,始于足下,每日千行代码必不可少,每日总结写一写,目标大厂,满怀希望便会所向披靡,哈哈哈!!!✌✌✌

一、✌题目要求
文件1:a.txt

文件2:b.txt

文件3:c.txt

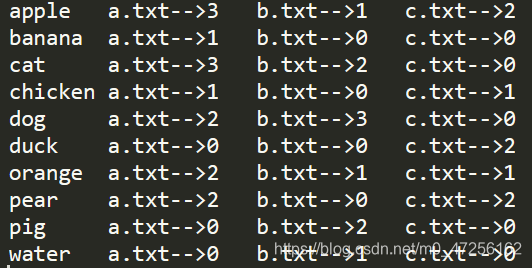
最终输出格式:
二、✌实现思想
> 首先在map阶段,获得每个单词所在的文件名称
> 然后在方法中,每个单词作为Key,所在文件名称+1作为Value
> 在Reduce阶段,针对每个Key,对他们的Value迭代,将Value切割获得个数,不断累加
> 最终按照指定格式写出
三、✌代码实现
1.✌Map类
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import java.io.IOException;
public class Map extends Mapper<LongWritable, Text, Text, Text> {
String name;
//获得切片文件名称
@Override
protected void setup(Context context) throws IOException, InterruptedException {
FileSplit inputSplit = (FileSplit) context.getInputSplit();
name = inputSplit.getPath().getName();
}
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] words = line.split(" ");
//输出格式为:apple a.txt2 pear b.txt1
for (String word : words) {
context.write(new Text(word), new Text(name + 1));
}
}
}
2.✌Reduce类
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class Reduce extends Reducer<Text, Text, Text, Text> {
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
int a_sum = 0, b_sum = 0, c_sum = 0;
//计数,对每个key
for (Text value : values) {
if (value.toString().contains("a.txt")) {
a_sum += 1;
} else if (value.toString().contains("b.txt")) {
b_sum += 1;
} else {
c_sum += 1;
}
}
//输出格式:apple a.txt-->3 b.txt-->1 c.txt-->2
context.write(key, new Text("a.txt-->" + a_sum + "\t" + "b.txt-->" + b_sum + "\t" + "c.txt-->" + c_sum + "\t"));
}
}
3.✌Driver类
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.log4j.BasicConfigurator;
import java.io.IOException;
public class Driver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
//配置文件路径
args = new String[]{
"D:/input/inputword", "D:/output"};
//打印日志信息
BasicConfigurator.configure();
//设置配置文件
Configuration conf = new Configuration();
//获得Job对象
Job job = Job.getInstance(conf);
//关联Map、Reduce、Driver类
job.setJarByClass(Driver.class);
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);
//设置Map输出格式
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
//设置最终输出格式
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
//设置文件路径
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//提交任务
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}
、