一 目标:实现倒排索引
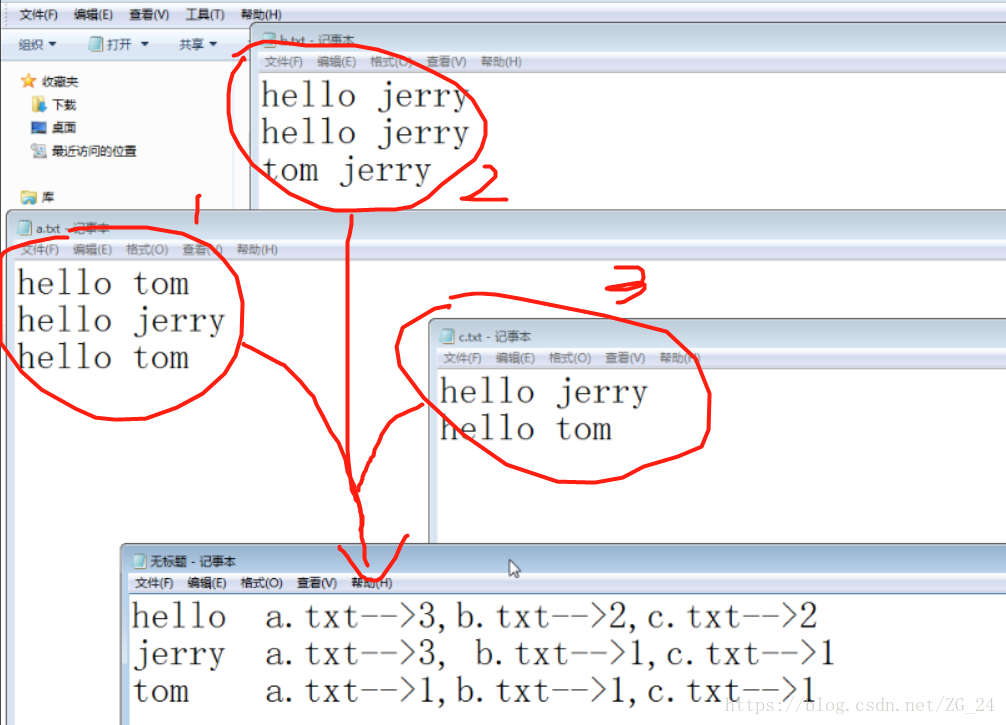
由于多个文件得到如下结果:
二 分析
---------------------------------mapper//context.wirte("hello->a.txt", "1")
//context.wirte("hello->a.txt", "1")
//context.wirte("hello->a.txt", "1")
---------------------------------reducer
/context.write("hello", "a.txt->3")
//context.write("hello", "b.txt->2")
//context.write("hello", "c.txt->2")
-----------------------------------------------mapper
//context.write("hello", "a.txt->3")
//context.write("hello", "b.txt->2")
//context.write("hello", "c.txt->2")
<"hello", {"a.txt->3", "b.txt->2", "c.txt->2"}>
---------------------------------------------- reducer
context.write("hello", "a.txt->3 b.txt->2 c.txt->2")
hello a.txt->3 b.txt->2 c.txt->2
jerry a.txt->1 b.txt->3 c.txt->1
tom a.txt->2 b.txt->1 c.txt->1
三 第一步
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
/**
* 倒排索引步骤一job
* @author [email protected]
*
*/
public class InverseIndexStepOne {
public static class StepOneMapper extends Mapper<LongWritable, Text, Text, LongWritable>{
@Override
protected void map(LongWritable key, Text value,Context context)
throws IOException, InterruptedException {
//拿到一行数据
String line = value.toString();
//切分出各个单词
String[] fields = StringUtils.split(line, " ");
//获取这一行数据所在的文件切片
FileSplit inputSplit = (FileSplit) context.getInputSplit();
//从文件切片中获取文件名
String fileName = inputSplit.getPath().getName();
for(String field:fields){
//封装kv输出 , k : hello-->a.txt v: 1
context.write(new Text(field+"-->"+fileName), new LongWritable(1));
}
}
}
public static class StepOneReducer extends Reducer<Text, LongWritable, Text, LongWritable>{
// <hello-->a.txt,{1,1,1....}>
@Override
protected void reduce(Text key, Iterable<LongWritable> values,Context context)
throws IOException, InterruptedException {
long counter = 0;
for(LongWritable value:values){
counter += value.get();
}
context.write(key, new LongWritable(counter));
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(InverseIndexStepOne.class);
job.setMapperClass(StepOneMapper.class);
job.setReducerClass(StepOneReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
FileInputFormat.setInputPaths(job, new Path(args[0]));
//检查一下参数所指定的输出路径是否存在,如果已存在,先删除
Path output = new Path(args[1]);
FileSystem fs = FileSystem.get(conf);
if(fs.exists(output)){
fs.delete(output, true);
}
FileOutputFormat.setOutputPath(job, output);
System.exit(job.waitForCompletion(true)?0:1);
}
}四 第二步
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.Reducer;
public class InverseIndexStepTwo {
public static class StepTwoMapper extends Mapper<LongWritable, Text, Text, Text>{
//k: 行起始偏移量 v: {hello-->a.txt 3}
@Override
protected void map(LongWritable key, Text value,Context context)
throws IOException, InterruptedException {
String line = value.toString();
String[] fields = StringUtils.split(line, "\t");
String[] wordAndfileName = StringUtils.split(fields[0], "-->");
String word = wordAndfileName[0];
String fileName = wordAndfileName[1];
long count = Long.parseLong(fields[1]);
context.write(new Text(word), new Text(fileName+"-->"+count));
//map输出的结果是这个形式 : <hello,a.txt-->3>
}
}
public static class StepTwoReducer extends Reducer<Text, Text,Text, Text>{
@Override
protected void reduce(Text key, Iterable<Text> values,Context context)
throws IOException, InterruptedException {
//拿到的数据 <hello,{a.txt-->3,b.txt-->2,c.txt-->1}>
String result = "";
for(Text value:values){
result += value + " ";
}
context.write(key, new Text(result));
//输出的结果就是 k: hello v: a.txt-->3 b.txt-->2 c.txt-->1
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
//先构造job_one
// Job job_one = Job.getInstance(conf);
//
// job_one.setJarByClass(InverseIndexStepTwo.class);
// job_one.setMapperClass(StepOneMapper.class);
// job_one.setReducerClass(StepOneReducer.class);
//......
//构造job_two
Job job_tow = Job.getInstance(conf);
job_tow.setJarByClass(InverseIndexStepTwo.class);
job_tow.setMapperClass(StepTwoMapper.class);
job_tow.setReducerClass(StepTwoReducer.class);
job_tow.setOutputKeyClass(Text.class);
job_tow.setOutputValueClass(Text.class);
FileInputFormat.setInputPaths(job_tow, new Path(args[0]));
//检查一下参数所指定的输出路径是否存在,如果已存在,先删除
Path output = new Path(args[1]);
FileSystem fs = FileSystem.get(conf);
if(fs.exists(output)){
fs.delete(output, true);
}
FileOutputFormat.setOutputPath(job_tow, output);
//先提交job_one执行
// boolean one_result = job_one.waitForCompletion(true);
// if(one_result){
System.exit(job_tow.waitForCompletion(true)?0:1);
// }
}
}