版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/qq_24452475/article/details/79904237
场景描述
- 通过切入具体示例代码,解决问题,从而积累 Hadoop 实战经验。
- 倒排索引,源于实际应用中需要根据属性的值来查找记录,通过倒排索引,可以根据单词快速获取包含这个单词的文档列表。
实验数据
- 输入
tom,LittleApple
jack,YesterdayOnceMore
Rose,MyHeartWillGoOn
jack,LittleApple
John,MyHeartWillGoOn
kissinger,LittleApple
kissinger,YesterdayOnceMore- 输出结果
- 使用 | 分隔 用户名,去掉末尾多余字符
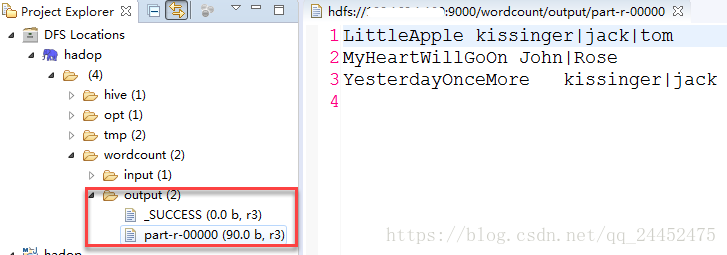
LittleApple kissinger|jack|tom
MyHeartWillGoOn John|Rose
YesterdayOnceMore kissinger|jack- 代码实现
- 本地运行, 若导出至 jar包, 需要 稍作修改,使代码整体显得较为优雅。
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
/**
*
* @ClassName: Music
*
* @Description: 输入用户播放音乐记录数据,统计歌曲被哪些用户播放过
*
* @author kngines
*
* @date 2018年4月11日
*/
public class Music {
public static class MusicMap extends Mapper<Object, Text, Text, Text> {
@Override
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
String content = itr.nextToken();
String[] splits = content.split(",");
String name = splits[0];
String music = splits[1];
context.write(new Text(music), new Text(name));
}
}
}
public static class MusicReduce extends Reducer<Text, Text, Text, Text> {
private Text userNames = new Text();
@Override
public void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
userNames.set("");
StringBuffer result = new StringBuffer();
int i = 0;
for (Text tempText : values) {
result.append(tempText.toString().trim() + "|");
i++;
}
userNames.set(result.toString().substring(0,result.length()-1)); // 去除尾部分隔符
context.write(key, userNames);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
conf.set("mapred.jop.tracker", "hdfs://"+args[2]+":9001"); // args[2] 远程服务器 IP地址(伪分布式Hadoop服务器地址)
conf.set("fs.default.name", "hdfs://"+args[2]+":9000");
String[] otherArgs = new GenericOptionsParser(conf, args)
.getRemainingArgs();
Job job = Job.getInstance(conf);
job.setJarByClass(Music.class);
job.setMapperClass(MusicMap.class);
job.setReducerClass(MusicReduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
if(otherArgs.length < 2){
System.err.println("Usage: MinMaxCountDriver <in> <out>");
System.exit(-1);
}
Path iPath = new Path(otherArgs[0]); // 输入文件路径
Path oPath = new Path(otherArgs[1]); // 输出文件路径
// 指定要处理的数据所在的位置
FileSystem fs = FileSystem.get(conf);
if (fs.exists(iPath)) {
FileInputFormat.addInputPath(job, iPath);
}
// 指定处理完成之后的结果所保存的位置
fs.delete(oPath, true);
FileOutputFormat.setOutputPath(job, oPath);
// 向yarn集群提交这个job
boolean res = job.waitForCompletion(true);
System.exit(res ? 0 : 1);
}
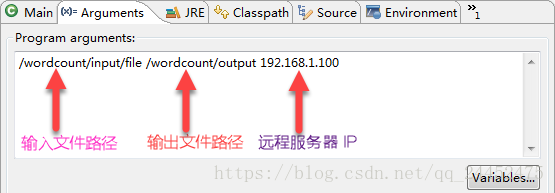
}eclipse 中运行参数 配置
- 输入文件路径, 输出文件路径,远程服务器 IP 地址,以空格间隔
- 输入文件路径, 输出文件路径,远程服务器 IP 地址,以空格间隔
输入结果显示
问题记录
- Apache Hadoop MapReduce Common. Maven Conf
- hadoop-mapreduce-client-common-2.6.2.jar 包引入,否则无法访问远程Hadoop 服务器。
- 本地机器(无线网,可能会多个无线网切换)、虚拟机(Hadoop服务器)
- 切换网络再切回网络,同一网段下,本机、虚拟机 ping 不通,可以通过【禁用–启用】本地网络、注销虚拟机方式,使网络互通。
- 个人在实验时,网络不通时,在虚拟机中 jps 命令, 不存在Hadoop 5 个基础进程,修复网络后,jps 进程正常。