1. VS项目属性不同字符集的区别
单字节字符集:顾名思义,单字节字符集就是用一个字节表示一个字符,简称SBCS。ASCII就是单字节字符集。在编码的过程中char类型就是单字节编码。
Unicode字符集:前面咱已经介绍什么是Unicode字符集了,不懂的请看前面的文章字符集与字符编码。默认编码是USC-2,即所有的字符都是固定的使用2个字节进行编码。因为比单字节字符宽,所有又叫宽字节编码。宽字节编码有很多,Unicode编码只是宽字节编码中的一种实现方式,其它的比如:USC-4。
多字节字符集:指使用多个字节表示一个字符,其实就是ANSI编码。有的字符使用一个字节,如ASCII字符,有的字符使用多个字节表示,如中文。英文名简称MBCS,由于Windows里使用的多字节字符绝大部分是两个字节,所以MBCS常被用**DBCS(双字节字符)**代替。
选择这两者的优缺点比较:

另外Unicode是国际通用的字符集,所以很容易在不同字符集之间进行转换,有利于软件的国际化。
2. wchar_t 、 _T 、TCHAR等含义
wchar_t意思是宽字节,w是Wide(宽)的缩写,所以只有在选择Unicode编码时才能使用。
wchar_t的定义为:typedef unsigned short wchar_t;
从这里我们可以看到,所谓的宽字节就是无符号短整型,即2个字节。
使用时前面加大写的“L”,比如:wchar_t str = L"Hello";*
选择宽字节字符集在编码的过程中字符串的类型是wchar_t,跟双字节字符集的类型char不一致,这样导致了两个问题:
1、像strlen()只能接受标准C字符的类型(char),所有使用char* 类型参数的函数都要重新
2、如何使编写的代码能够同时支持 多字节编码 和 宽字节(Unicode)编码的系统上运行?
对于第一个问题:
解决办法就是对函数进行重写,比如strlen的宽字节版本是wcslen,需要加入头文件Windows.h
需要注意的是:strlen是字符串的所占字节数,wcslen是字符串中字符个数,乘以2才是字节数。
对于第二个问题:
通过定义 宏 或者 起别名 的方式对 替代名称 做 不同定义 来实现的,比如tchar.h头文件中:
之所以能实现,主要通过编译器来实现,通过使用条件编译#ifdef _UNICODE(有下划线) 来对 替代名称 的不同定义。
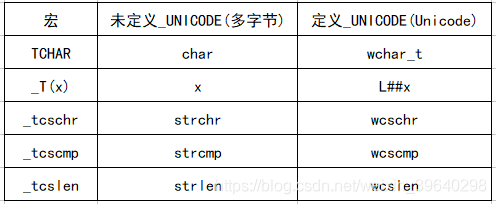
这样子您就知道_T和TCHAR的啥意思了,它是为了方便程序员编码使用的。
说的这里了,您可能又有疑问了,哪里定义_UNICODE宏呢?
这里又回到最初了,我们在项目属性中选择 “使用多字节字符集” 或者 “使用Unicode字符集”时,VS在“C++ -> 预处理器”中增加了宏定义,分别是 _MBCS 和 _UNICODE,注意 _MBCS和_UNICODE是相互排斥的。
最后说一下一个细节,有Windows编码经验的人可能发现了,还有一个UNICODE宏,很多的定义跟_UNICODE是一样的,这是为什么呢?
UNICODE是Windows 提供的宏,Windows有一些系统API也要用到字符串,但是C库没有,比如:SetWindowText()和MessageBox()等,微软就对_UNICODE进行了重写和扩展,但是本质是一样,都是为了方便处理两种编码程序。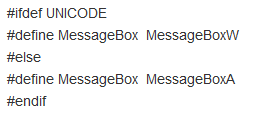
3. 字符转换
#include <locale>
#include <stdio.h>
#include <codecvt>
using namespace std;
//Unicode转ANSI
const std::string WstringToString(const std::wstring& src)
{
std::locale sys_locale("");
const wchar_t* data_from = src.c_str();
const wchar_t* data_from_end = src.c_str() + src.size();
const wchar_t* data_from_next = 0;
int wchar_size = 4;
char* data_to = new char[(src.size() + 1) * wchar_size];
char* data_to_end = data_to + (src.size() + 1) * wchar_size;
char* data_to_next = 0;
memset(data_to, 0, (src.size() + 1) * wchar_size);
typedef std::codecvt<wchar_t, char, mbstate_t> convert_facet;
mbstate_t out_state = { 0 };
auto result = std::use_facet<convert_facet>(sys_locale).out(
out_state, data_from, data_from_end, data_from_next,
data_to, data_to_end, data_to_next);
if (result == convert_facet::ok)
{
std::string dst = data_to;
delete[] data_to;
return dst;
}
else
{
printf("convert error!\n");
delete[] data_to;
return std::string("");
}
}
//ANSI转Unicode
const std::wstring StringToWstring(const std::string& src)
{
std::locale sys_locale("");
const char* data_from = src.c_str();
const char* data_from_end = src.c_str() + src.size();
const char* data_from_next = 0;
wchar_t* data_to = new wchar_t[src.size() + 1];
wchar_t* data_to_end = data_to + src.size() + 1;
wchar_t* data_to_next = 0;
wmemset(data_to, 0, src.size() + 1);
typedef std::codecvt<wchar_t, char, mbstate_t> convert_facet;
mbstate_t in_state = { 0 };
auto result = std::use_facet<convert_facet>(sys_locale).in(
in_state, data_from, data_from_end, data_from_next,
data_to, data_to_end, data_to_next);
if (result == convert_facet::ok)
{
std::wstring dst = data_to;
delete[] data_to;
return dst;
}
else
{
printf("convert error!\n");
delete[] data_to;
return std::wstring(L"");
}
}
//Unicode转UTF-8
const std::string WstringToUTF8(const std::wstring& src)
{
std::wstring_convert<std::codecvt_utf8<wchar_t>> conv;
return conv.to_bytes(src);
}
//UTF-8转Unicode
const std::wstring UTF8ToWstring(const std::string& src)
{
std::wstring_convert<std::codecvt_utf8<wchar_t> > conv;
return conv.from_bytes(src);
}
//GBK转Unicode
wstring GBKToWstring(const string &str)
{
wstring_convert<codecvt<wchar_t, char, mbstate_t>> gbk_cvt(new codecvt<wchar_t, char, mbstate_t>("chs"));
return gbk_cvt.from_bytes(str);
}
//Unicode转GBK
string WstringToGBK(const wstring &str)
{
wstring_convert<codecvt<wchar_t, char, mbstate_t>> gbk_cvt(new codecvt<wchar_t, char, mbstate_t>("chs"));
return gbk_cvt.to_bytes(str);
}
//UTF8转GBK
string UTF8ToGBK(const string &str)
{
wstring_convert<codecvt_utf8<wchar_t>> utf8_cvt; // utf8-》unicode转换器
wstring_convert<codecvt<wchar_t, char, mbstate_t>> gbk_cvt(new codecvt<wchar_t, char, mbstate_t>("chs")); // unicode-》gbk转换器
wstring t = utf8_cvt.from_bytes(str);
return gbk_cvt.to_bytes(t);
}
//GBK转UTF8
string GBKToUTF8(const string &str)
{
wstring_convert<codecvt_utf8<wchar_t>> utf8_cvt;
wstring_convert<codecvt<wchar_t, char, mbstate_t>> gbk_cvt(new codecvt<wchar_t, char, mbstate_t>("chs")); // unicode-》gbk转换器
wstring t = gbk_cvt.from_bytes(str);
return utf8_cvt.to_bytes(t);
}