从ZF-Net开始人们就在研究神经网络和filter的可视化
结合了多篇文章整理了好久,网上写的真的鱼龙混杂,代码具有可操作性的不多.......也或者是我的coding水平还没到?sad.
CNN各层输出可视化
import os import torch import torchvision as tv import torchvision.transforms as transforms import torch.nn as nn import torch.optim as optim import argparse import skimage.data import skimage.io import skimage.transform import numpy as np import matplotlib.pyplot as plt import torchvision.models as models from PIL import Image import cv2 #提取某一层网络特征图 class FeatureExtractor(nn.Module): def __init__(self, submodule, extracted_layers): super(FeatureExtractor, self).__init__() self.submodule = submodule self.extracted_layers = extracted_layers def forward(self, x): outputs = {} for name, module in self.submodule._modules.items(): if "fc" in name: x = x.view(x.size(0), -1) x = module(x) print(name) if (self.extracted_layers is None) or (name in self.extracted_layers and 'fc' not in name): outputs[name] = x # print(outputs) return outputs def get_picture(pic_name, transform): img = skimage.io.imread(pic_name) img = skimage.transform.resize(img, (256, 256)) #读入图片时将图片resize成(256,256)的 img = np.asarray(img, dtype=np.float32) return transform(img) def make_dirs(path): if os.path.exists(path) is False: os.makedirs(path) pic_dir = 'dataset/dogsvscats/train/cat.1700.jpg' transform = transforms.ToTensor() img = get_picture(pic_dir, transform) # 插入维度 img = img.unsqueeze(0) device = torch.device("cuda" if torch.cuda.is_available() else "cpu") img = img.to(device) net = models.resnet101(pretrained=True).to(device) dst = './feautures' therd_size = 256 myexactor = FeatureExtractor(submodule=net, extracted_layers=None) output = myexactor(img) #output是dict #dict_keys(['conv1', 'bn1', 'relu', 'maxpool', 'layer1', 'layer2', 'layer3', 'layer4', 'avgpool', 'fc']) for idx,val in enumerate(output.items()): k,v = val features = v[0] iter_range = features.shape[0] for i in range(iter_range): # plt.imshow(features.data.cpu().numpy()[i,:,:],cmap='jet') if 'fc' in k: #不可视化fc层 continue feature = features.data.cpu().numpy() feature_img = feature[i, :, :] feature_img = np.asarray(feature_img * 255, dtype=np.uint8) dst_path = os.path.join(dst, str(idx)+'-'+k) make_dirs(dst_path) feature_img = cv2.applyColorMap(feature_img, cv2.COLORMAP_JET) if feature_img.shape[0] < therd_size: tmp_file = os.path.join(dst_path, str(i) + '_' + str(therd_size) + '.png') tmp_img = feature_img.copy() tmp_img = cv2.resize(tmp_img, (therd_size, therd_size), interpolation=cv2.INTER_NEAREST) cv2.imwrite(tmp_file, tmp_img) dst_file = os.path.join(dst_path, str(i) + '.png') cv2.imwrite(dst_file, feature_img)输入的原图是kaggle的猫狗数据集中的一张图片
依次提取的各层
conv1
bn1
relu
maxpool
layer1
layer2
layer3
layer4
avgpool
fc输出
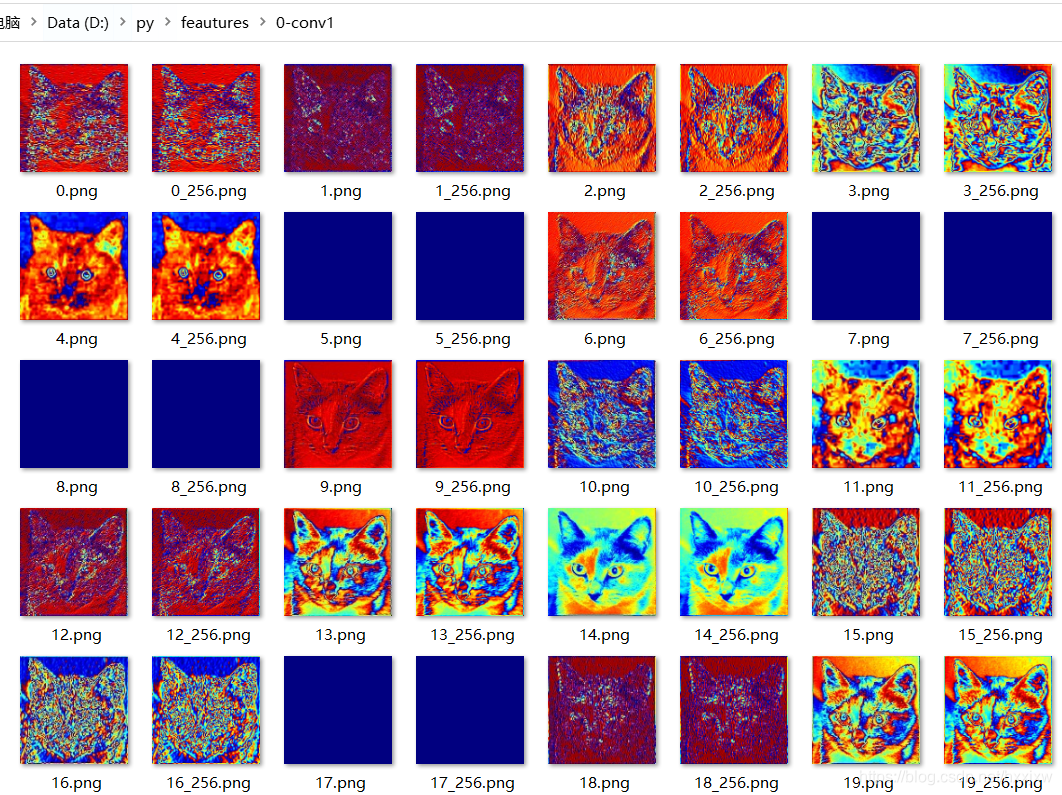
因为到后期的图片会越来越小,所以我们有一个缩放操作,每张图片有一个输出的原图,还有一个放大后的图片
0-conv1
1-bn1
2-relu
3-maxpool
4-layer1
5-layer2
6-layer3
7-layer4
8-avgpool
可以看出,第一层的卷积层输出,特征图里面还可以看出猫的形状,到了后面卷积网络的输出特征图,看着有点像热力图,并且完全没有猫的样子,是更加抽象的图片表达










CNN 卷积 feature map可视化
我们一个conv层,比如有64个filter,每个filter又是个三维的,要扫过R,G,B通道,这里可视化的时候只选择了每个filter的第一个channel来显示
import torch import torchvision.models as models import matplotlib.pyplot as plt from PIL import Image from torchvision import transforms input_image = Image.open('dataset/dogsvscats/train/cat.1700.jpg') preprocess = transforms.Compose([ transforms.Resize(256), transforms.CenterCrop(224), transforms.ToTensor(), transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]), ]) input_tensor = preprocess(input_image) input_batch = input_tensor.unsqueeze(0) # create a mini-batch as expected by the model model = models.alexnet(pretrained=True) if torch.cuda.is_available(): input_batch = input_batch.to('cuda') model.to('cuda') with torch.no_grad(): output = model(input_batch) #卷积可视化 #将数据灌入模型后,pytorch框架会进行对应的前向传播,要对卷积核可视化,我们需要把卷积核从框架中提取出来。多谢torch提供的接口,我们可以直接把对应层的权重取出 for layer in dict(model.features.named_children()).keys(): if layer not in ['0','3','6','8','10']: #只有conv层可以可视化,maxpooling层和relu层不能可视化 continue filter = dict(model.features.named_children())[layer] filter = filter.weight.cpu().clone() print("total of number of filter : ", len(filter)) num = len(filter) plt.figure(figsize=(20, 17)) for i in range(1,64): plt.subplot(9, 9, i) plt.axis('off') plt.imshow(filter[i][0, :, :].detach(),cmap='gray') plt.show()conv1
conv2
conv3
conv4
conv5
可以看出第一层卷积核 人类还是可以比较容易理解,有些提取的是边缘,有些提取的是圆形,有些提取的是斑点等。
最后一层卷积层的卷积核就已经看不出来是提取的什么东西了,即卷积核提取的是更加抽象的特征。
https://blog.csdn.net/weixin_44023658/article/details/106123841




