写在前面:根据b站博主霹雳吧啦Wz 学习CNN,作为个人的学习记录。
目录
模型参数:
LeNet是上个世纪出现的典型卷积神经网络,最早用于数字识别的CNN。
输入层为32*32大小,除了输入共有7层。详细内容如下图所示

模型搭建:
import torch.nn as nn
import torch.nn.functional as F
class LeNet(nn.Module):
def __init__(self):
super(LeNet, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5) # 输入通道大小,输出通道大小,卷积核大小
self.pool1 = nn.MaxPool2d(2, 2) # 卷积核大小,步距stride
self.conv2 = nn.Conv2d(6, 16, 5)
self.pool2 = nn.MaxPool2d(2, 2)
self.fc1 = nn.Linear(16*5*5, 120) # 上一层的输出,节点个数(输出大小)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10) # 这里的10,是最后要分为10个类别。
def forward(self, x):
x = F.relu(self.conv1(x)) # input(3, 32, 32) output(6, 28, 28)
x = self.pool1(x) # output(6, 14, 14)
x = F.relu(self.conv2(x)) # output(16, 10, 10)
x = self.pool2(x) # output(16, 5, 5)
x = x.view(-1, 16*5*5) # output(16*5*5) # 使用view函数展平成一维向量
x = F.relu(self.fc1(x)) # output(120)
x = F.relu(self.fc2(x)) # output(84)
x = self.fc3(x) # output(10)
return x
应用:
使用torchvision.datasets下面的CIFAR10数据集进行分类,该数据集有飞机、汽车、鸟、猫等3*32*32大小的十种类别图像。
训练:
import torch
import torchvision
import torch.nn as nn
from model import LeNet
import torch.optim as optim
import torchvision.transforms as transforms
def main():
### 1.图像预处理
# transform:对图像进行预处理的函数
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
### 2.下载且划分训练集和验证集
# 50000张训练图片
# 第一次使用时要将download设置为True才会自动去下载数据集
train_set = torchvision.datasets.CIFAR10(root='./data', train=True,
download=False, transform=transform)
train_loader = torch.utils.data.DataLoader(train_set, batch_size=36,
shuffle=True, num_workers=0)
# 10000张验证图片
# 第一次使用时要将download设置为True才会自动去下载数据集
val_set = torchvision.datasets.CIFAR10(root='./data', train=False,
download=False, transform=transform)
val_loader = torch.utils.data.DataLoader(val_set, batch_size=5000,
shuffle=False, num_workers=0)
val_data_iter = iter(val_loader) # 将val_loader转化为一个可迭代的迭代器
val_image, val_label = next(val_data_iter) # 获取迭代器中的这批数据。在这里的标签已经变成0-9这些数字标签了
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck') # 类别
### 3.定义网络、损失函数、优化器
net = LeNet() # 网络
loss_function = nn.CrossEntropyLoss() # 定义损失函数
optimizer = optim.Adam(net.parameters(), lr=0.001) # 定义优化器
### 4.训练
# 迭代5次
for epoch in range(5): # loop over the dataset multiple times
running_loss = 0.0
for step, data in enumerate(train_loader, start=0):
# get the inputs; data is a list of [inputs, labels]
inputs, labels = data
# zero the parameter gradients
optimizer.zero_grad() # 清零历史梯度
# forward + backward + optimize
outputs = net(inputs) # 进入网络,通过正向传播获得输出
loss = loss_function(outputs, labels) # 计算损失。outputs是网络预测值,labels是真实标签
loss.backward() # 反向传播
optimizer.step() # 通过优化器进行参数更新
# print statistics
running_loss += loss.item() # 计算出损失就加到running_loss里
if step % 500 == 499: # print every 500 mini-batches # 每隔500步打印一次数据信息
with torch.no_grad(): # 不计算每个节点的误差梯度
outputs = net(val_image) # [batch, 10] # 验证集进入网络进行预测,获得所有的预测结果和预测值
predict_y = torch.max(outputs, dim=1)[1] # 寻找概率最大的索引在哪
accuracy = torch.eq(predict_y, val_label).sum().item() / val_label.size(0) # 将预测值与真实值进行对比,如果相等,eq(predict_y, val_label)返回为1,否则为0;然后用sum求和求出预测对了多少,获得求和数值后再除以总的验证集大小,就是准确率
print('[%d, %5d] train_loss: %.3f test_accuracy: %.3f' %
(epoch + 1, step + 1, running_loss / 500, accuracy))
running_loss = 0.0 # 损失清零,进行下一次五百步的训练
print('Finished Training')
### 5.保存参数
save_path = './Lenet.pth'
torch.save(net.state_dict(), save_path)
if __name__ == '__main__':
main()
分为五步:
- 定义图像预处理方式:transforms是图像预处理包,用compose把多个步骤整合在一起。ToTensor是首先将原来为(高*宽*通道数)图像变成(通道数*高*宽),因为在模型那里的图像格式是(C*H*W);然后将图像像素值从[0,255]变成[0,1],即归一化。Normalize是用均值和标准差归一化张量图像,将像素值变成[-1,1];具体来说,img=(img-mean)/std,其中mean和std是设置的参数决定,三个值代表三个通道。
- 下载且划分训练集和验证集:torch.utils.data.DataLoader对数据进行batch的划分,返回所有样本的img和label。参数:dataset:包含所有数据的数据集;batch_size每一组所包含数据的数量;shuffle:是否打乱数据位置,True是打乱;num_workers使用线程的数量,一般都为0。
- 定义网络、损失函数、优化器
- 训练
- 保存训练好的参数(模型)
训练结果:
在32*32大小的图片上预测结果有67.4%,也不容易的...
预测:
随便找一张图片,修改预测程序中的第三步图片位置信息和名称,运行。
import torch
import torchvision.transforms as transforms
from PIL import Image
from model import LeNet
def main():
### 1.图像预处理,网络输入需要32*32的,所以要先resize,然后归一化和标准化和训练时一样
transform = transforms.Compose(
[transforms.Resize((32, 32)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
### 2.载入网络和训练好的模型参数
net = LeNet()
net.load_state_dict(torch.load('Lenet.pth'))
### 3.打开一张图片
im = Image.open('1.jpg')
im = transform(im) # [C, H, W]
im = torch.unsqueeze(im, dim=0) # [N, C, H, W],unsqueeze用于增加一个batch
### 4.和训练那里一样,不计算误差梯度
with torch.no_grad():
outputs = net(im) # 通过网络后的预测值和概率
predict = torch.max(outputs, dim=1)[1].numpy() # 概率最大值的所在索引返回给predict
print(classes[int(predict)]) # 打印出索引所在的类别
if __name__ == '__main__':
main()
预测结果:
图片:

预测结果:

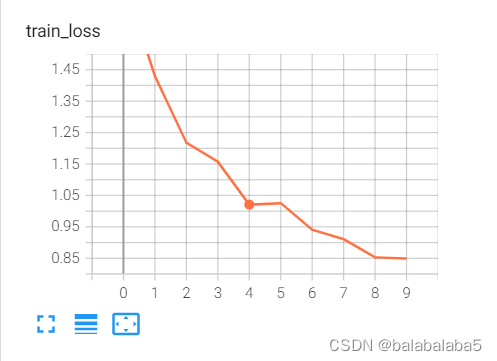
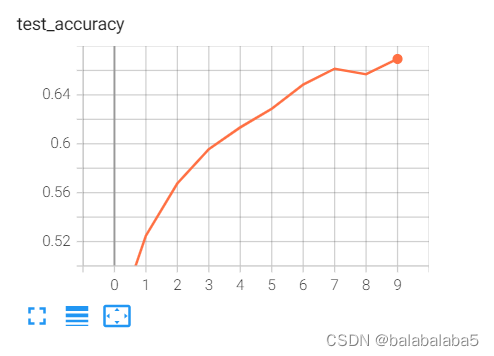
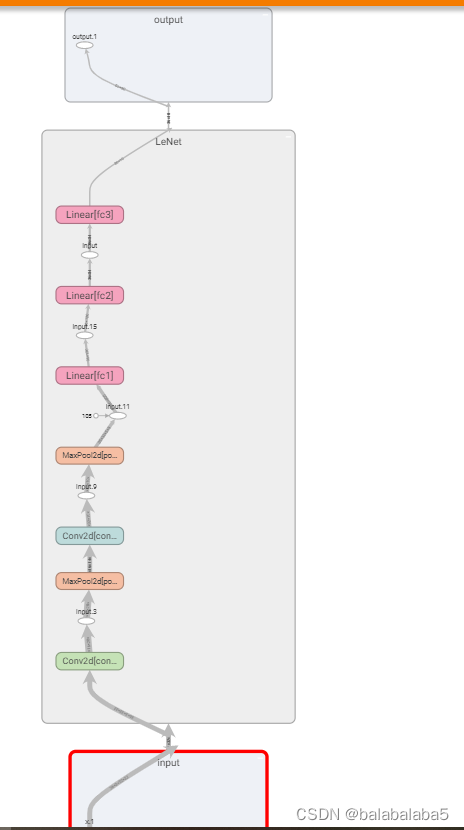
数据可视化:
用tensorboard将训练次数-loss值、训练次数-准确率、网络架构画出来:
此时完整代码:
import torch
import torchvision
import torch.nn as nn
from model import LeNet
import torch.optim as optim
import torchvision.transforms as transforms
from torch.utils.tensorboard import SummaryWriter
def main():
n=0
# transform:对图像进行预处理的函数
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
# 50000张训练图片
# 第一次使用时要将download设置为True才会自动去下载数据集
train_set = torchvision.datasets.CIFAR10(root='./data', train=True,
download=False, transform=transform)
train_loader = torch.utils.data.DataLoader(train_set, batch_size=36,
shuffle=True, num_workers=0)
# 10000张验证图片
# 第一次使用时要将download设置为True才会自动去下载数据集
val_set = torchvision.datasets.CIFAR10(root='./data', train=False,
download=False, transform=transform)
val_loader = torch.utils.data.DataLoader(val_set, batch_size=5000,
shuffle=False, num_workers=0)
val_data_iter = iter(val_loader)
val_image, val_label = next(val_data_iter)
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
net = LeNet() # 网络
loss_function = nn.CrossEntropyLoss() # 定义损失函数
optimizer = optim.Adam(net.parameters(), lr=0.001) # 定义优化器
# dummy_input = torch.rand(512, 1, 28, 28) # 网络中输入的数据维度
# with SummaryWriter(comment='LeNet') as w:
# w.add_graph(net, (dummy_input,)) # net是你的网络名
for epoch in range(5): # loop over the dataset multiple times
running_loss = 0.0
for step, data in enumerate(train_loader, start=0):
# get the inputs; data is a list of [inputs, labels]
inputs, labels = data
# zero the parameter gradients
optimizer.zero_grad()
# forward + backward + optimize
outputs = net(inputs)
loss = loss_function(outputs, labels)
loss.backward()
optimizer.step()
# print statistics
running_loss += loss.item()
if step % 500 == 499: # print every 500 mini-batches
with torch.no_grad():
outputs = net(val_image) # [batch, 10]
predict_y = torch.max(outputs, dim=1)[1]
accuracy = torch.eq(predict_y, val_label).sum().item() / val_label.size(0)
print('[%d, %5d] train_loss: %.3f test_accuracy: %.3f' %
(epoch + 1, step + 1, running_loss / 500, accuracy))
writer = SummaryWriter("runs/logs_fina") # 存放log文件的目录
writer.add_scalar('train_loss', running_loss / 500, n) # 画loss,横坐标为训练次数
writer.add_scalar('test_accuracy', accuracy, n) # 画accuracy,横坐标为训练次数
writer.add_graph(net, inputs)
n+=1
running_loss = 0.0
writer.close()
print('Finished Training')
save_path = './Lenet.pth'
torch.save(net.state_dict(), save_path)
if __name__ == '__main__':
main()