写在前面:根据b站博主霹雳吧啦Wz 学习CNN,作为个人的学习记录。
目录
论文:
2014年提出的VGG,使用很小的卷积核,加深了网络架构,表明将深度推至16-19个权重层,可以实现有效改进。
另外,论文表示,一个7*7的卷积核可以使用三个3*3的卷积核替代,一个5*5的卷积核可以使用两个3*3的卷积核替代。
这么替换有什么好处?以三个3*3卷积核代替一个7*7卷积核为例。
首先,引入了三个非线性校正层,而不是单一校正层,使决策函数更具有辨识性。
其次,参数的数量会大幅度减少:假设输入图片的通道为C,输出通道数也为C,那么一个7*7卷积核所计算的参数为7*7*C*C=49C*C,一个3*3卷积核所计算的参数为3*3*C*C=9C*C,三个3*3卷积核的话就是27C*C,相比于49C*C,计算的参数少了不少。
原始论文地址:《VERY DEEP CONVOLUTIONAL NETWORKS FOR LARGE-SCALE IMAGE RECOGNITION》
论文里面有提到过1*1这种更小的卷积核, 并且在C通道里使用了这个卷积核(模型参数里的C通道)。使用这个1*1卷积核的方式最开始源于一种2013年提出的网中网(NIN),用来加深加宽网络结构的(论文地址:《Network In Network》)。
1*1卷积核的作用:
- 改变特征层的通道数。这个作用就好比通过池化来改变特征层的高和宽一样。
- 会增加非线性。因为卷积之后会使用非线性激活函数,从而允许网络学习更复杂的功能。
模型架构:
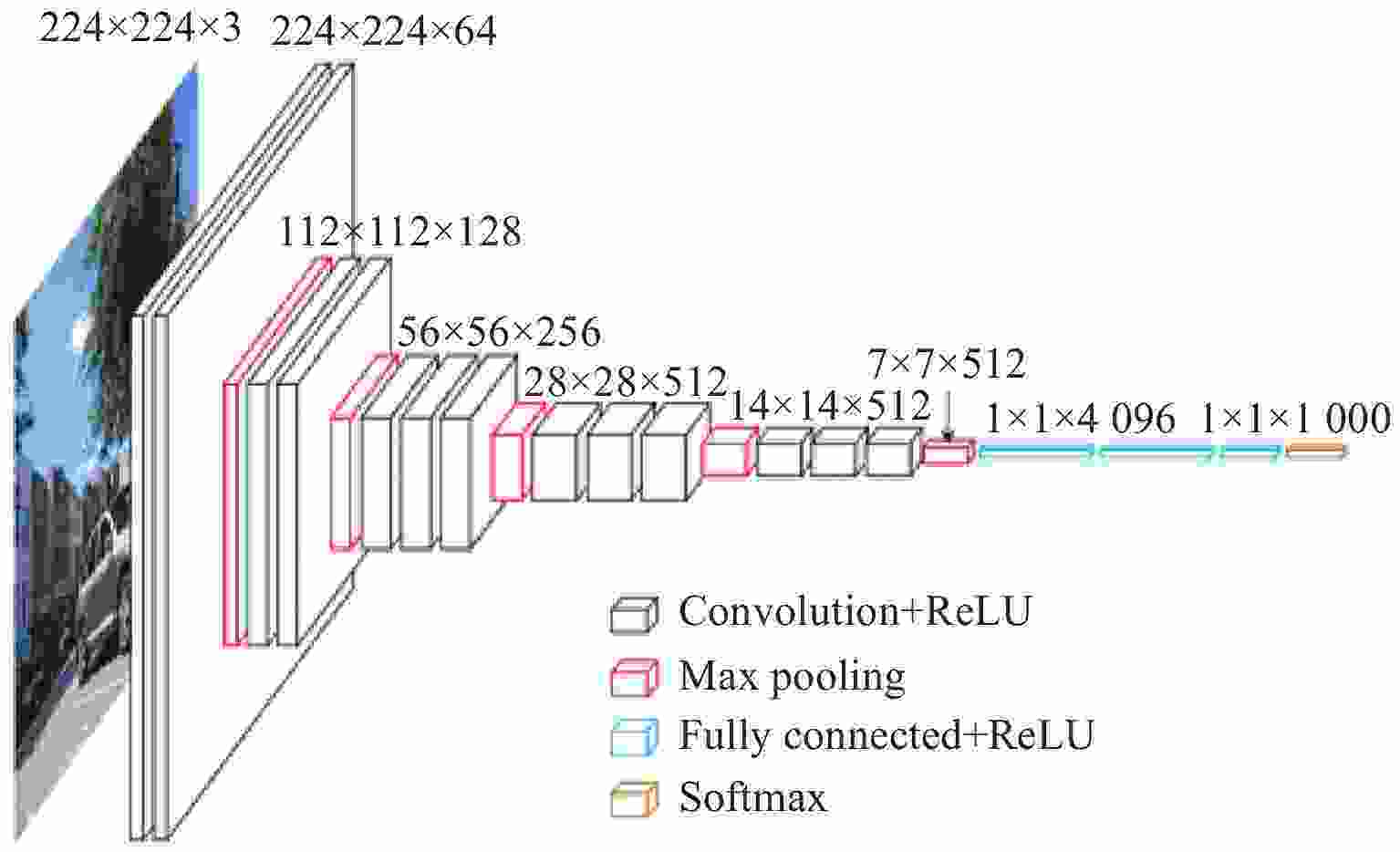
模型参数:
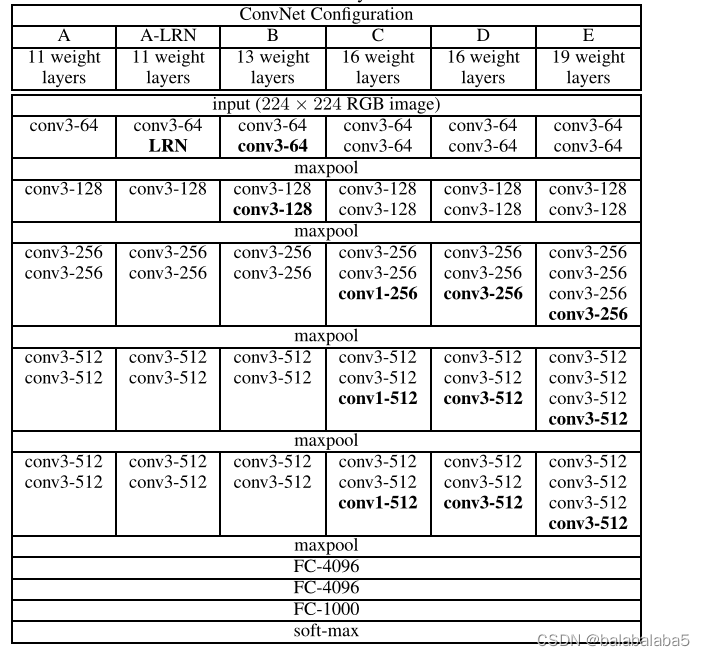
上面是论文作者做的所有模型,听得最多的是VGG16,即D通道的参数。
卷积层所有的核大小为3*3,padiing为1,stride为1;
池化层所有的核大小为2*2,padding为0,stride为2。
模型搭建:
1、列表
首先,因为VGG有VGG11、VGG13、VGG16、VGG19,这几个的区别就是卷积核的个数以及池化层的位置不同,所以针对这个问题,先写出来一个列表:
cfgs = {
'vgg11': [64, 'M', 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'vgg13': [64, 64, 'M', 128, 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'vgg16': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M'],
'vgg19': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 256, 'M', 512, 512, 512, 512, 'M', 512, 512, 512, 512, 'M'],
}比如VGG11,对应的是模型参数里的A通道,首先是64个3*3卷积核,于是列表的第一个数为64;接下来是一个池化层,于是列表的第二个数是“M”;然后是128个3*3卷积核,于是列表的第三个数为128。以此类推。
2、定义特征提取网络结构
所有的卷积层和池化层就是提取特征。
def make_features(cfg: list):
layers = []
in_channels = 3
for v in cfg:
if v == "M":
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
else:
conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1)
layers += [conv2d, nn.ReLU(True)]
in_channels = v
return nn.Sequential(*layers)
- 定义了一个空的数组layers以此来存放层信息。
- 定义了一个输入通道数,因为第一层的输入通道数一定是3,因为是RGB图像。
- 根据传进来的cfg参数来遍历里面的内容,cfg就是第一步里面采用哪种VGG模型。
- 如果遍历到的内容为“M”,那么代表的是需要创建一个池化层。于是在layers里加上一个核大小为2*2,步长为2的池化层;
- 如果是其他的内容,那么代表需要创建一个卷积层+relu激活函数。于是在layers里加上一个输入通道数为3的,输出通道数是v即卷积核个数大小,卷积核大小为3*3,padding为1的卷积层,然后使用relu激活函数,最后将in_channels变成卷积核个数大小,来作为下一次创建卷积层时的输入通道大小。
- 遍历结束后,返回所有的特征层。
返回值:总共是31层

3、定义分类网络结构
加上全连接层且初始化权重
def __init__(self, features, num_classes=1000, init_weights=False):
super(VGG, self).__init__()
self.features = features
self.classifier = nn.Sequential(
nn.Dropout(p=0.5),
nn.Linear(512*7*7, 4096),
nn.ReLU(True),
nn.Dropout(p=0.5),
nn.Linear(4096, 4096),
nn.ReLU(True),
nn.Linear(4096, num_classes)
)
if init_weights:
self._initialize_weights()先将第二步的特征网络结构传进来,然后制作由全连接层组成的分类网络结构。
首先使用Dropout进行随机失活神经元;然后构建全连接层,第一个全连接层输入的大小为512*7*7,节点数为4096;最后进行relu激活函数。进行两次。
最后一层的全连接层是需要进行softmax的,所以就没有使用relu。
初始化权重:使用xavier_uniform_方法
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.xavier_uniform_(m.weight)
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.xavier_uniform_(m.weight)
nn.init.constant_(m.bias, 0)4、正向传播
def forward(self, x):
# N x 3 x 224 x 224
x = self.features(x)
# N x 512 x 7 x 7
x = torch.flatten(x, start_dim=1)
# N x 512*7*7
x = self.classifier(x)
return x先是特征提取网络结构,然后展平,进入分类网络结构,最后返回。
在展平那里,因为x的维度是N*C*H*W,但进入分类网络结构是需要C*H*W的,所以设置一个start_dim=1,表示从Channel这个维度开始展平。
5、调用的方法
def vgg(model_name="vgg16", **kwargs):
assert model_name in cfgs, "Warning: model number {} not in cfgs dict!".format(model_name)
cfg = cfgs[model_name]
model = VGG(make_features(cfg), **kwargs)
return model通过往vgg这个方法里面传参数,从而达到构建模型的目的。
最终只需要使用下面的语句就可以搭建好模型了。
vgg_model = vgg(model_name="vgg11")
vgg11可以用"vgg13"、"vgg16" 、"vgg19"代替。
应用:
训练:
用的数据集是上一篇AlexNet网络的数据集,训练的代码也和那篇大同小异。
import os
import sys
import json
import torch
import torch.nn as nn
from torchvision import transforms, datasets
import torch.optim as optim
from tqdm import tqdm
from model import vgg
def main():
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print("using {} device.".format(device))
data_transform = {
"train": transforms.Compose([transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]),
"val": transforms.Compose([transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])}
data_root = os.path.abspath(os.path.join(os.getcwd(), "../..")) # get data root path
image_path = os.path.join(data_root, "data_set", "flower_data") # flower data set path
assert os.path.exists(image_path), "{} path does not exist.".format(image_path)
train_dataset = datasets.ImageFolder(root=os.path.join(image_path, "train"),
transform=data_transform["train"])
train_num = len(train_dataset)
# {'daisy':0, 'dandelion':1, 'roses':2, 'sunflower':3, 'tulips':4}
flower_list = train_dataset.class_to_idx
cla_dict = dict((val, key) for key, val in flower_list.items())
# write dict into json file
json_str = json.dumps(cla_dict, indent=4)
with open('class_indices.json', 'w') as json_file:
json_file.write(json_str)
batch_size = 32
nw = min([os.cpu_count(), batch_size if batch_size > 1 else 0, 8]) # number of workers
print('Using {} dataloader workers every process'.format(nw))
train_loader = torch.utils.data.DataLoader(train_dataset,
batch_size=batch_size, shuffle=True,
num_workers=nw)
validate_dataset = datasets.ImageFolder(root=os.path.join(image_path, "val"),
transform=data_transform["val"])
val_num = len(validate_dataset)
validate_loader = torch.utils.data.DataLoader(validate_dataset,
batch_size=batch_size, shuffle=False,
num_workers=nw)
print("using {} images for training, {} images for validation.".format(train_num,
val_num))
# test_data_iter = iter(validate_loader)
# test_image, test_label = test_data_iter.next()
model_name = "vgg16"
net = vgg(model_name=model_name, num_classes=5, init_weights=True)
net.to(device)
loss_function = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters(), lr=0.0001)
epochs = 30
best_acc = 0.0
save_path = './{}Net.pth'.format(model_name)
train_steps = len(train_loader)
for epoch in range(epochs):
# train
net.train()
running_loss = 0.0
train_bar = tqdm(train_loader, file=sys.stdout)
for step, data in enumerate(train_bar):
images, labels = data
optimizer.zero_grad()
outputs = net(images.to(device))
loss = loss_function(outputs, labels.to(device))
loss.backward()
optimizer.step()
# print statistics
running_loss += loss.item()
train_bar.desc = "train epoch[{}/{}] loss:{:.3f}".format(epoch + 1,
epochs,
loss)
# validate
net.eval()
acc = 0.0 # accumulate accurate number / epoch
with torch.no_grad():
val_bar = tqdm(validate_loader, file=sys.stdout)
for val_data in val_bar:
val_images, val_labels = val_data
outputs = net(val_images.to(device))
predict_y = torch.max(outputs, dim=1)[1]
acc += torch.eq(predict_y, val_labels.to(device)).sum().item()
val_accurate = acc / val_num
print('[epoch %d] train_loss: %.3f val_accuracy: %.3f' %
(epoch + 1, running_loss / train_steps, val_accurate))
if val_accurate > best_acc:
best_acc = val_accurate
torch.save(net.state_dict(), save_path)
print('Finished Training')
if __name__ == '__main__':
main()
预测:
预测的代码也大同小异。
import os
import json
import torch
from PIL import Image
from torchvision import transforms
import matplotlib.pyplot as plt
from model import vgg
def main():
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
data_transform = transforms.Compose(
[transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
# load image
img_path = "../tulip.jpg"
assert os.path.exists(img_path), "file: '{}' dose not exist.".format(img_path)
img = Image.open(img_path)
plt.imshow(img)
# [N, C, H, W]
img = data_transform(img)
# expand batch dimension
img = torch.unsqueeze(img, dim=0)
# read class_indict
json_path = './class_indices.json'
assert os.path.exists(json_path), "file: '{}' dose not exist.".format(json_path)
with open(json_path, "r") as f:
class_indict = json.load(f)
# create model
model = vgg(model_name="vgg16", num_classes=5).to(device)
# load model weights
weights_path = "./vgg16Net.pth"
assert os.path.exists(weights_path), "file: '{}' dose not exist.".format(weights_path)
model.load_state_dict(torch.load(weights_path, map_location=device))
model.eval()
with torch.no_grad():
# predict class
output = torch.squeeze(model(img.to(device))).cpu()
predict = torch.softmax(output, dim=0)
predict_cla = torch.argmax(predict).numpy()
print_res = "class: {} prob: {:.3}".format(class_indict[str(predict_cla)],
predict[predict_cla].numpy())
plt.title(print_res)
for i in range(len(predict)):
print("class: {:10} prob: {:.3}".format(class_indict[str(i)],
predict[i].numpy()))
plt.show()
if __name__ == '__main__':
main()
写在最后:
由于数据集只有三千多张,vgg网络比AlexNet深多了,从而导致用cpu来训练的话,时间是翻倍的(我尝试了一下cpu,才30轮用了有14个小时,所以好的设备---GPU是十分重要的),效果却一般般,最终才73%左右。
下次使用大的数据集和好的GPU再来测试vgg网络。
