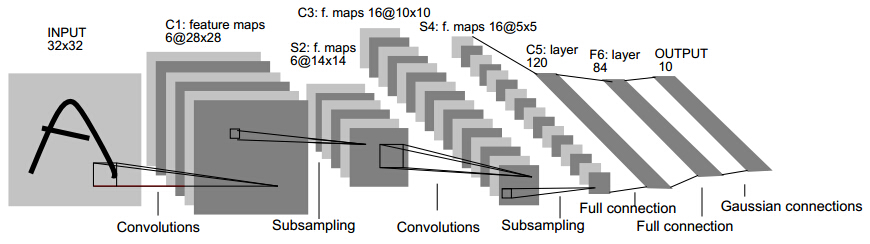
Lenet(1986)
主要用于识别10个手写邮政编码数字,5*5卷积核,stride=1,最大池化。
Alexnet(2012)
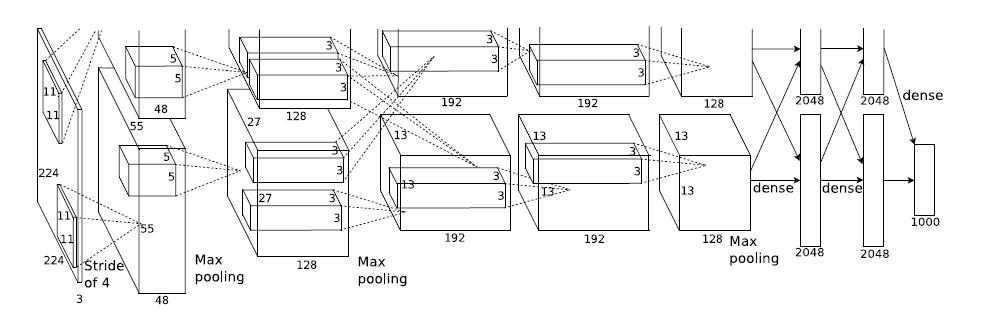
卷积部分都是画成上下两块,意思是说吧这一层计算出来的feature map分开,但是前一层用到的数据要看连接的虚线。
局部响应归一化LRN:利用前后几层(对应位置的点)对中间这一层做一下平滑约束,增加泛化能力,公式为:
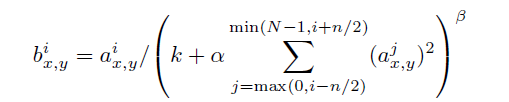
GooleNet(2014)
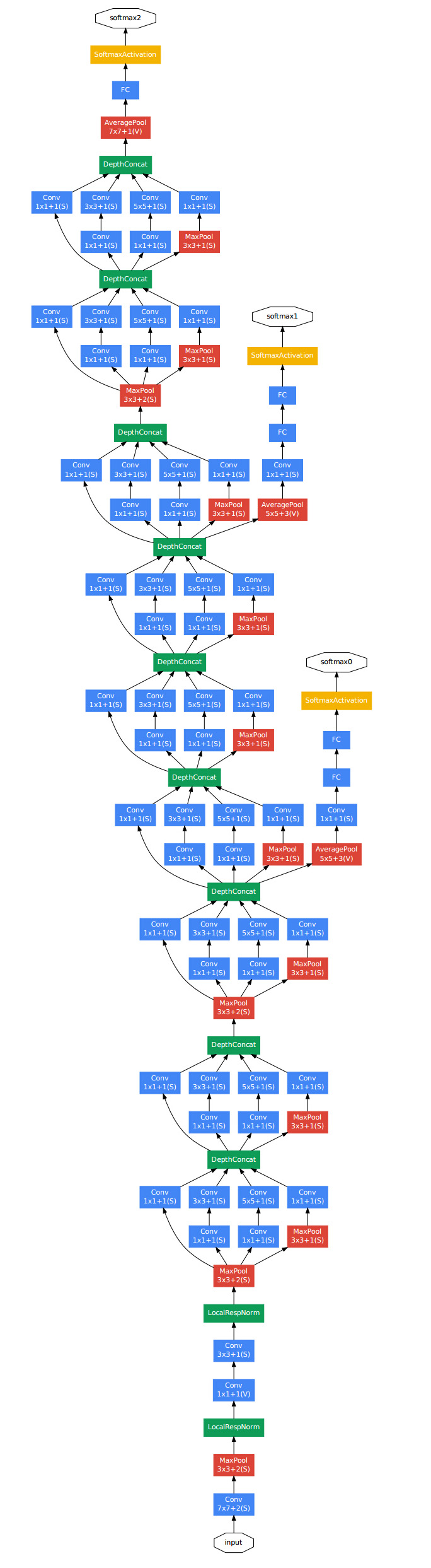
inception的结构,一分四,然后做一些不同大小的卷积,之后再堆叠feature map。
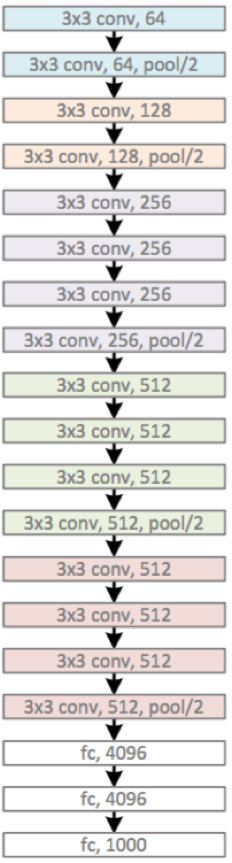
VGG(2014)
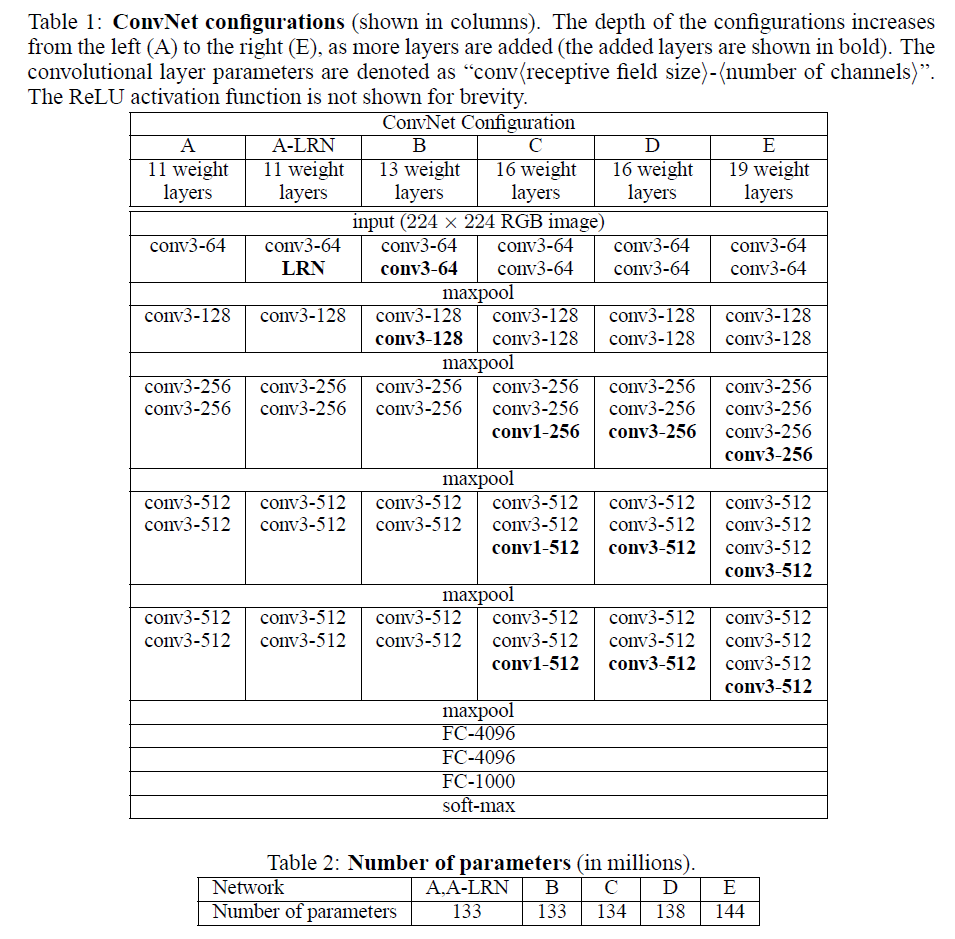
由5层卷积层、3层全连接层、softmax输出层构成。用了3*3的卷积核(c模型用了1*1的卷积核,但一般都只用d、e模型,1*1不必管它),步长stride=1,padding=1,max池化,pooling窗口为2*2,pooling步长为2
VGG系列网络使用的是3x3的小卷积核,这是有中心和上下左右的最小单元(中心+八邻域);两个3x3的卷积层连在一起可视为5x5的filter,三个连在一起可视为一个7x7的。和大卷积核相比:(1)可以减少参数(2)进行了更多的非线性映射,增加网络的拟合、表达能力。
VGG缺陷:参数量大,有140M
需要注意到LRN只在A-LRN出现,且A-LRN结果没有A好,说明LRN作用不大。A效果不如更深的BCDE;B与C比较:增加1x1filter,增加了额外的非线性提升效果;与D比较:3x3 的filter(结构D)比1x1(结构C)的效果好。
全连层的作用:从特征空间映射到样本标记空间。
可以顺便看一下卷积层代替全连层的说明。
假设最后一个卷积层的输出为7×7×512,连接此卷积层的全连接层为1×1×4096。连接层实际就是卷积核大小为上层特征大小的卷积运算,卷积后的结果为一个节点,就对应全连接层的一个点。如果将这个全连接层转化为卷积层:
1.共有4096组滤波器
2.每组滤波器含有512个卷积核
3.每个卷积核的大小为7×7
4.则输出为1×1×4096
------------------------------------------
若后面再连接一个1×1×4096全连接层。相当于就是将特征组合起来进行4096个分类分数的计算,得分最高的就是划到的正确的类别。则其对应的转换后的卷积层的参数为:
1.共有4096组滤波器
2.每组滤波器含有4096个卷积核
3.每个卷积核的大小为1×1
4.输出为1X1X4096
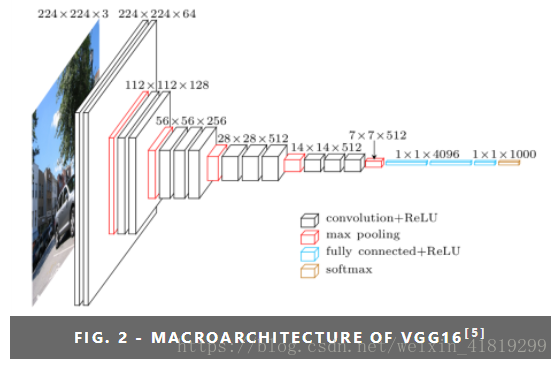
VGG16模型(2+2+3+3+3个卷积层,3个全连接层):
VGG19模型:
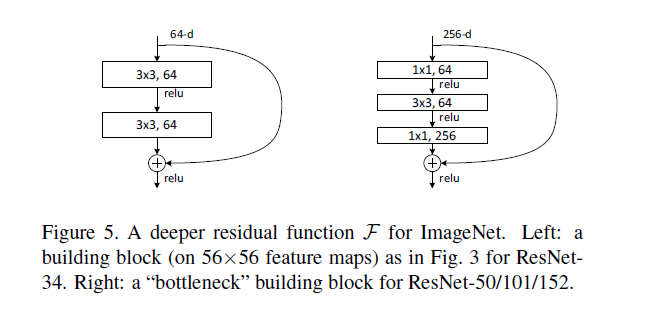
ResNet(2015)
设计了“bottleneck”形式的block(有跨越几层的直连)
用全局平均池化GAP代替全连层FC,解决全连接层参数冗余的问题,但FC的优势在于在迁移学习中可改善微调的效果。
1*1卷积核
本质上其实就是channels的线性叠加
作用:
(1)升/降特征的维度,指改变通道数(厚度),不改变宽高。举个例子:W*H*6——用5个1*1厚度为6的卷积核卷积——W*H*5
(2)加入非线性,卷积后经过激励层,提高网络表达能力,实现泛化。
卷积后计算feature map尺寸大小
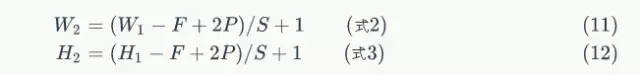
参考网址:
https://blog.csdn.net/oppo62258801/article/details/73525505
https://blog.csdn.net/Teeyohuang/article/details/75214758