最近一直在学习目标检测,计算机视觉的一个重要领域。而cnn是现在语音分析和图像识别的一个研究重点,它的共享权值策略不仅降低了网络模型的复杂度,也减少了训练的权值的数量。
CNN网络的训练
第一阶段,向前传播阶段:
a)从样本集中取一个样本(X,Yp),将X输入网络;
b)计算相应的实际输出Op。
在此阶段,信息从输入层经过逐级的变换,传送到输出层。这个过程也是网络在完成训练后正常运行时执行的过程。在此过程中,网络执行的是计算(实际上就是输入与每层的权值矩阵相点乘,得到最后的输出结果):
Op=Fn(…(F2(F1(XpW(1))W(2))…)W(n))
第二阶段,向后传播阶段
a)算实际输出Op与相应的理想输出Yp的差;
b)按极小化误差的方法反向传播调整权矩阵
本文主要介绍LeNet5,Alexnet,Googlenet,VGG
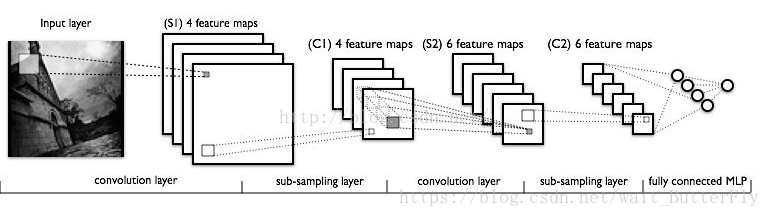
LeNet5:
是用于手写字体识别的一个经典CNN,曾用于银行签名识别。
AlexNet:(7层+softmax层用于分类)
2012年,Imagenet比赛冠军的model-Alexnet (以第一作者alex命名),是Alex在寝室熬出来的模型。
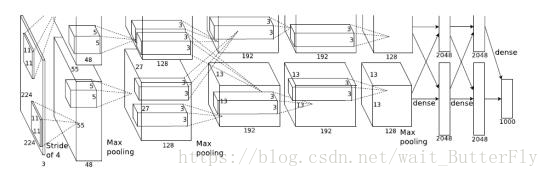
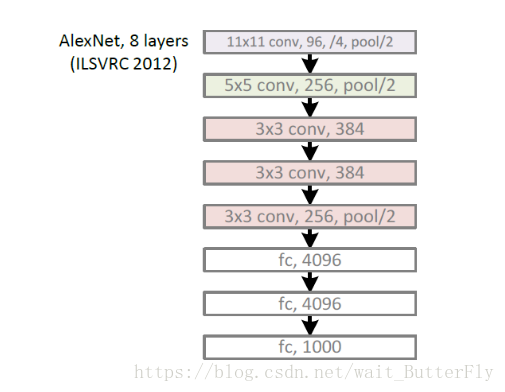
1)con - relu - pooling - LRN

具体计算都在图里面写了,要注意的是input层是227*227,而不是paper里面的224*224,这里可以算一下,主要是227可以整除后面的conv1计算,224不整除。如果一定要用224可以通过自动补边实现,不过在input就补边感觉没有意义,补得也是0。
2)conv - relu - pool - LRN

和上面基本一样,唯独需要注意的是group=2,这个属性强行把前面结果的feature map分开,卷积部分分成两部分做。
3)conv - relu

4)conv-relu

5)conv - relu - pool

6)fc - relu - dropout

这里有一层特殊的dropout层,在alexnet中是说在训练的以1/2概率使得隐藏层的某些neuron的输出为0,这样就丢到了一半节点的输出,BP的时候也不更新这些节点。
7)fc - relu - dropout

8)fc - softmax

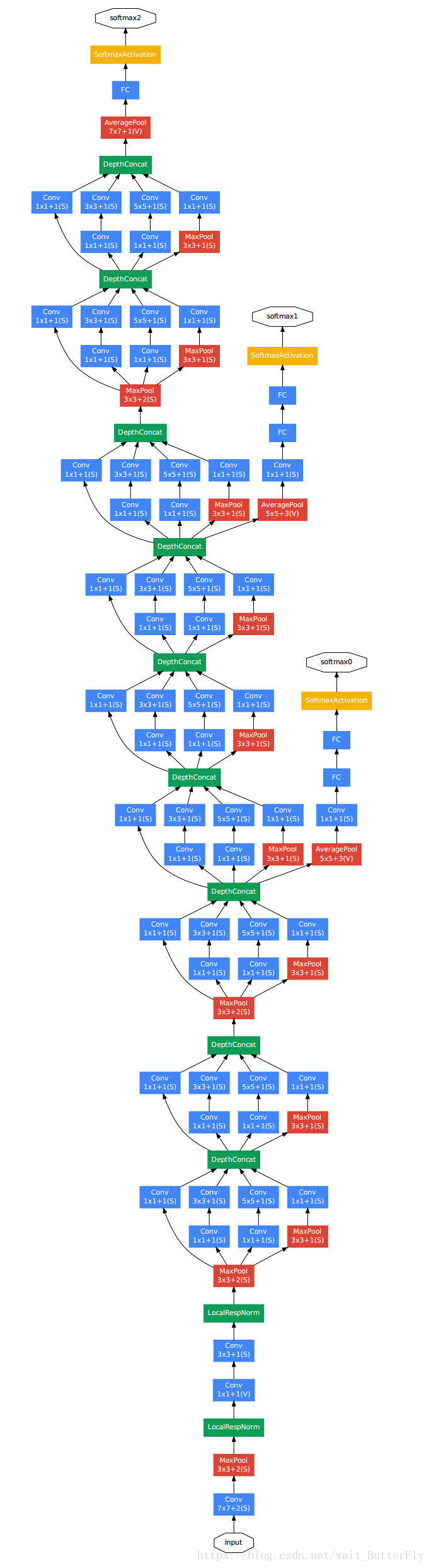
GoogleNet(22层):
14年比赛冠军的model,它证明,使用更多的卷积,更深的层次可以得到更好的结构。
VGG(Visual Geometry Group)(19层):
在ILSVRC上定位第一,分类第二,ILSVRC——ImageNet Large-Scale Visual Recongnition Challenge)
vgg和googlenet是2014年imagenet竞赛的双雄,这两类模型结构有一个共同特点是 go deeper
VGG有很多个版本,也算是比较稳定和经典的model。它的特点也是连续conv多,计算量巨大
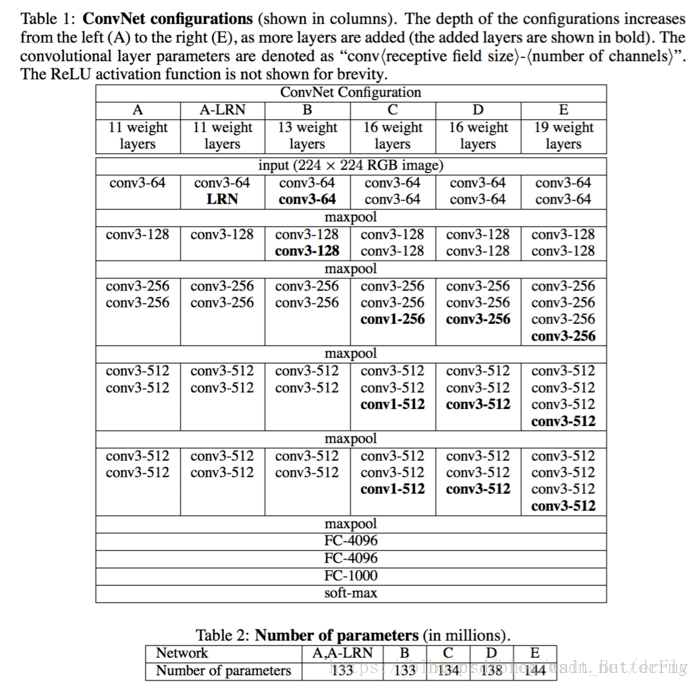
VGGNet改进点总结
一、使用了更小的3*3卷积核,和更深的网络。两个3*3卷积核的堆叠相对于5*5卷积核的视野,三个3*3卷积核的堆叠相当于7*7卷积核的视野。这样一方面可以有更少的参数(3个堆叠的3*3结构只有7*7结构参数数量的(3*3*3)/(7*7)=55%);另一方面拥有更多的非线性变换,增加了CNN对特征的学习能力。
二、在VGGNet的卷积结构中,引入1*1的卷积核,在不影响输入输出维度的情况下,引入非线性变换,增加网络的表达能力,降低计算量。
三、训练时,先训练级别简单(层数较浅)的VGGNet的A级网络,然后使用A网络的权重来初始化后面的复杂模型,加快训练的收敛速度。
四、采用了Multi-Scale的方法来训练和预测。可以增加训练的数据量,防止模型过拟合,提升预测准确率
参考文献:https://www.jianshu.com/p/bf398d78aedc