1.摘要
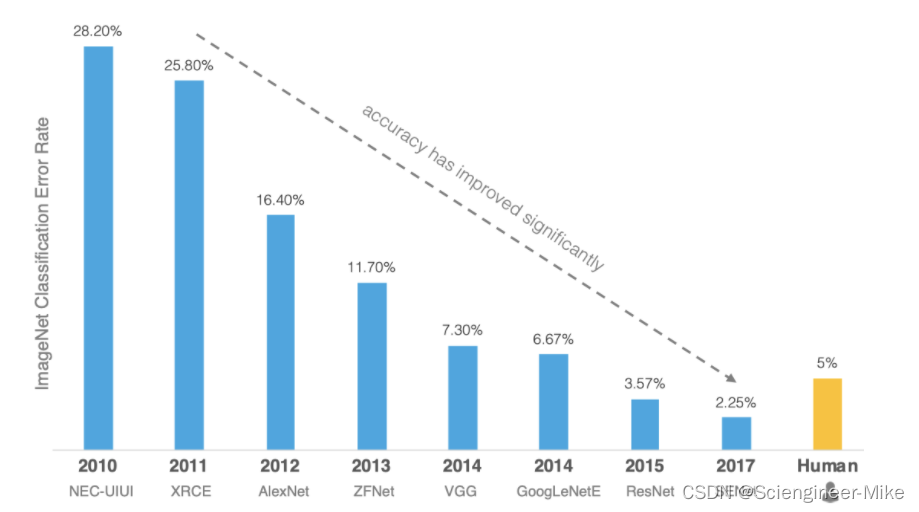
ImageNet数据集是ILSVRC竞赛使用的是数据集,由斯坦福大学李飞飞教授主导,包含了超过1400万张全尺寸的有标记图片,大约有22000个类别的数据。ILSVRC全称ImageNet Large-Scale Visual Recognition Challenge,是视觉领域最受追捧也是最具权威的学术竞赛之一,代表了图像领域的最高水平。从2010年开始举办到2017年最后一届,使用ImageNet数据集的一个子集,总共有1000类。而从2012年起,该项赛事的比赛获胜者都是使用深度学习算法,如下图。当下深度学习算法层出不穷的情况下,我们对于经典深度学习算法的学习是非常值得的,对于我们未来开发新型算法可提供思路与借鉴。接下来,我将AlexNet,Vgg,GoogLeNet,ResNet经典算法进行解读,希望对大家的学习有所帮助。
2.AlexNet
2.1.网络模型
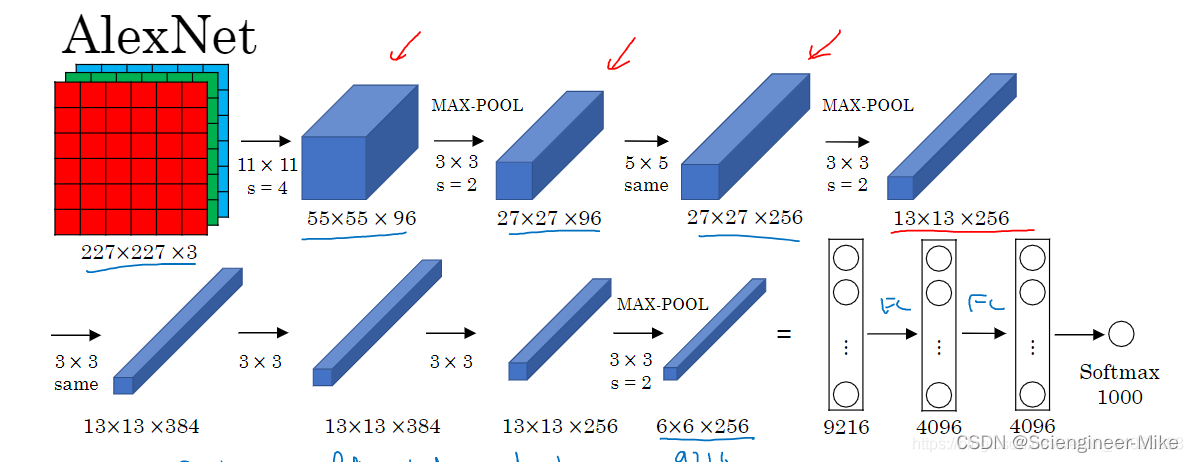
2012年,Hinton课题组构建的CNN网络模型AlexNet横空出世,一举夺得冠军,且碾压第二名(传统的SVM方法)的分类性能(top5错误率为15.3%,第二名为26.2%),也正是由于该模型的突然出现,使得众多研究者对CNN有了很大的兴趣,带来了深度学习的大爆发。
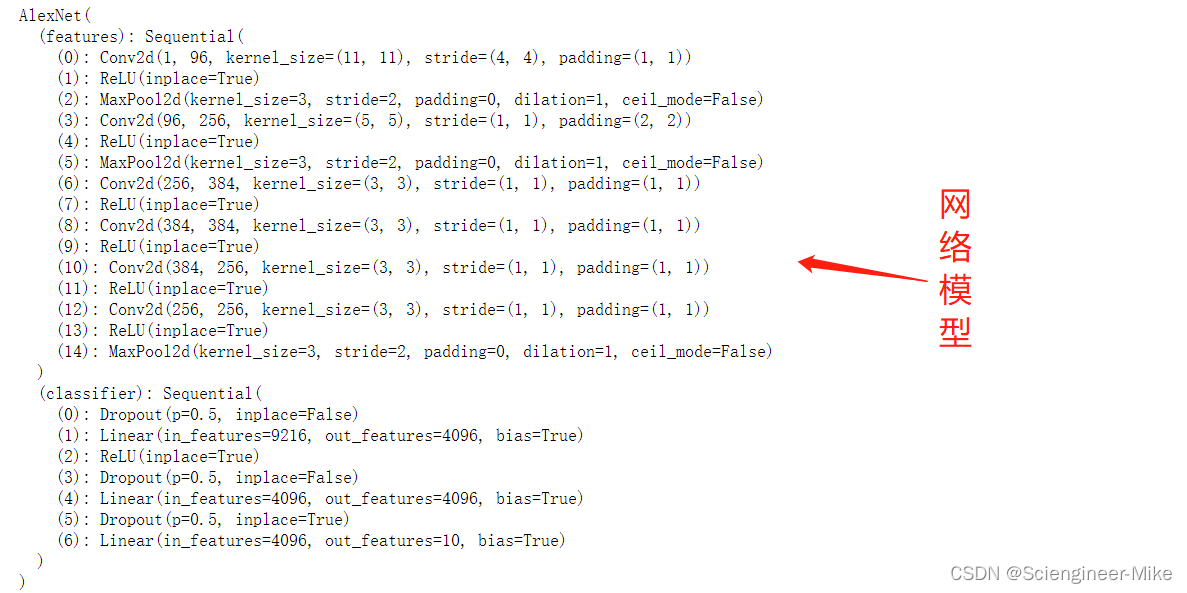
AlexNet这个名字源于模型的作者叫Alex Krizhevsky,其使用了八层卷积神经网络,包括五层卷积和两层全连接隐藏层以及一个全连接输出层,第一层的卷积核形状为11×11,第二层中的卷积核为5×5,其余的卷积核为3×3,所有的池化层窗口大小为3×3,步伐为3。并将sigmoid激活函数改成了ReLU激活函数,是计算更加简单,同时采用了dropout来控制全连接层的模型复杂度。首次证明了学习到的特征可以远超手工设计的特征,模型架构如下:
2.2.代码复现
模型代码(Pytorch实现):
# 导入相应的包
import numpy as np
import torchvision
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
from torchvision import datasets,transforms
# 搭建模型
class AlexNet(nn.Module):
def __init__(self,n_classes=10):
super(AlexNet,self).__init__()
self.features = nn.Sequential(
#227*227*1-27*27*96
nn.Conv2d(1,96,kernel_size=11,stride=4,padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3,stride=2),
# 27*27*96-13*13*256
nn.Conv2d(96,256,kernel_size=5,stride=1,padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3,stride=2),
# 13*13*256-13*13*384
nn.Conv2d(256,384,kernel_size=3,stride=1,padding=1),
nn.ReLU(inplace=True),
# 13*13*384-13*13*384
nn.Conv2d(384,384,kernel_size=3,stride=1,padding=1),
nn.ReLU(inplace=True),
# # 13*13*384-13*13*256
nn.Conv2d(384,256,kernel_size=3,stride=1,padding=1),
nn.ReLU(inplace=True),
# 13*13*256-6*6*256
nn.Conv2d(256,256,kernel_size=3,stride=1,padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2)
)
self.classifier = nn.Sequential(
nn.Dropout(0.5),
nn.Linear(256*6*6,4096),
nn.ReLU(inplace=True),
nn.Dropout(0.5),
nn.Linear(4096,4096),
nn.Dropout(inplace=True),
nn.Linear(4096,n_classes)
)
def forward(self,x):
batch_size = x.shape[0]
x = self.features(x)
x = x.view(batch_size,-1)
x = self.classifier(x)
return x
Alex_model = AlexNet()
print(Alex_model)
# 损失+优化器
Alex_model_loss = torch.nn.CrossEntropyLoss()
Alex_optimizer = torch.optim.Adam(Alex_model.parameters(),lr=0.0005)
导入mnist手写数字数据,并进行打包。由于数据量大,笔记本性能有限,我将只训练极少数的数据进行演示。
# 导入数据
data_tf = torchvision.transforms.Compose([transforms.Resize([227,227]),transforms.ToTensor(),transforms.Normalize([0.5],[0.5])])
train_dataset = datasets.MNIST(root="./data",train=True,transform=data_tf)
test_dataset = datasets.MNIST(root="./data",train=False,transform=data_tf)
train_loader = DataLoader(train_dataset,batch_size=64,shuffle=True)
test_loader = DataLoader(test_dataset,batch_size=64,shuffle=True)
#训练模型,由于数据量大,笔记本性能有限,我将只训练极少量数据进行演示
for epoch in range(5):
loss_sum,cort_num_sum,acc = 0,0,0
i = 0 #控制数据量
for img,label in train_loader:
if i >= 4:
break
i = i + 1
img = torch.autograd.Variable(img)
label = torch.autograd.Variable(label)
# print(img.shape)
output = Alex_model(img)
loss = Alex_model_loss(output,label)
Alex_optimizer.zero_grad()
loss.backward()
Alex_optimizer.step()
loss_sum += loss.data
_,pred = torch.max(output.data,1)
cort_num = torch.eq(pred,label).sum()
cort_num_sum += cort_num
acc = cort_num_sum.float()/(4*64)
print("Epoch is %d, loss_sum is %.3f, cort_num_sum is %d, acc is %.3f"
%(epoch,loss_sum,cort_num_sum,acc))

验证模型代码:
# test 验证
Alex_model.eval()
test_loss = 0
test_acc = 0
j = 0
for img_test,label_test in test_loader:
if j >=4:
break
j = j + 1
output = Alex_model(img_test)
loss = Alex_model_loss(output,label_test)
test_loss += loss.data.numpy()
_,pred = torch.max(output.data,1)
num_correct = torch.eq(pred,label_test).sum()
test_acc += num_correct.data
test_acc = test_acc.numpy()/(4*64)
print(test_acc,test_loss)

3.VGG
3.1.网络模型
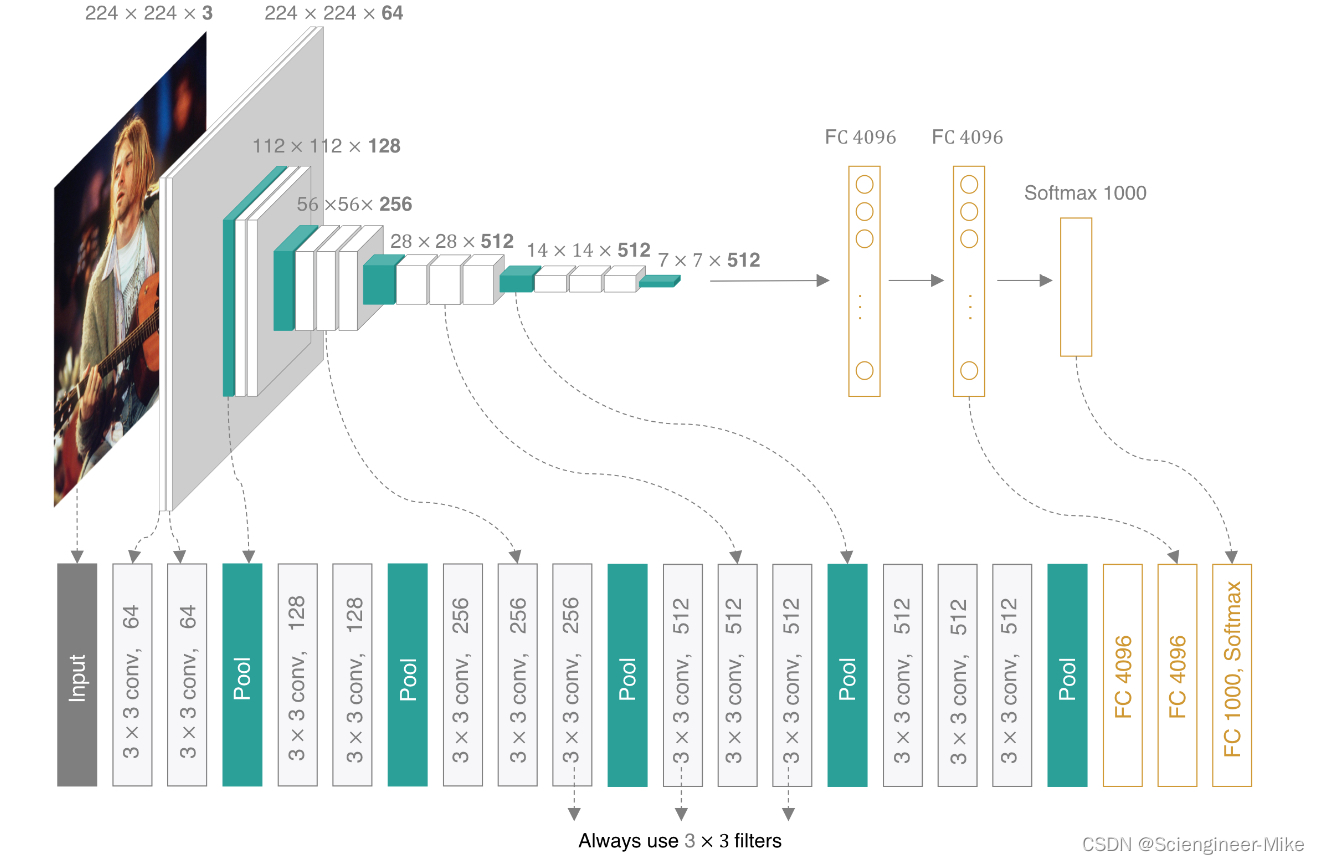
2014年,牛津大学计算机视觉组和Google DeepMind公司的研究员一起研发出了新的卷积神经网络:VGGNet,并取得了ILSVRC2014比赛分类项目的第二名,主要贡献是使用较小的卷积核构建神经网络结构,能够取得较好的识别精度。VGG可以看成是加深版的AlexNet,整个网络由卷积层和全连接层叠加而成,和AlexNet不同的是,VGGNet使用的全部都是3x3的小卷积核和2x2的池化核,通过不断加深网络来提升性能,其网络架构如下图所示:
3.2.代码介绍
模型代码(tensorflow实现):
# 导入相应的包
import tensorflow as tf
import numpy as np
import cv2
from tensorflow.keras.datasets import mnist
# 定义卷积块,池化块
def vgg_block(num_convs,num_filters):
net = tf.keras.models.Sequential()
for i in range(num_convs):
net.add(tf.keras.layers.Conv2D(num_filters,kernel_size=3,padding='same',activation='relu'))
net.add(tf.keras.layers.MaxPool2D(pool_size=2,strides=2))
return net
# VGG16网络有5个卷积块,前2块使用两个卷积层,而后3块使用三个卷积层。第一块的输出通道是64,之后每次对输出通道数翻倍,直到变为512
conv_arch = ((2,128),(3,256),(3,512),(3,512))
# 定义VGG网络
def vgg(conv_arch):
vgg_net = tf.keras.models.Sequential()
vgg_net.add(tf.keras.layers.Conv2D(64,(3,3),strides=(1,1),input_shape=(224,224,1),padding='same',activation='relu',kernel_initializer='uniform'))
vgg_net.add(tf.keras.layers.Conv2D(64,(3,3),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
vgg_net.add(tf.keras.layers.MaxPooling2D(pool_size=(2,2)))
for (num_convs,num_filters) in conv_arch:
vgg_net.add(vgg_block(num_convs,num_filters))
vgg_net.add(tf.keras.models.Sequential(
[
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(4096,activation="relu"),
tf.keras.layers.Dropout(0.5),
tf.keras.layers.Dense(4096,activation="relu"),
tf.keras.layers.Dropout(0.5),
tf.keras.layers.Dense(10,activation="softmax")
]
))
return vgg_net
vgg_net = vgg(conv_arch)
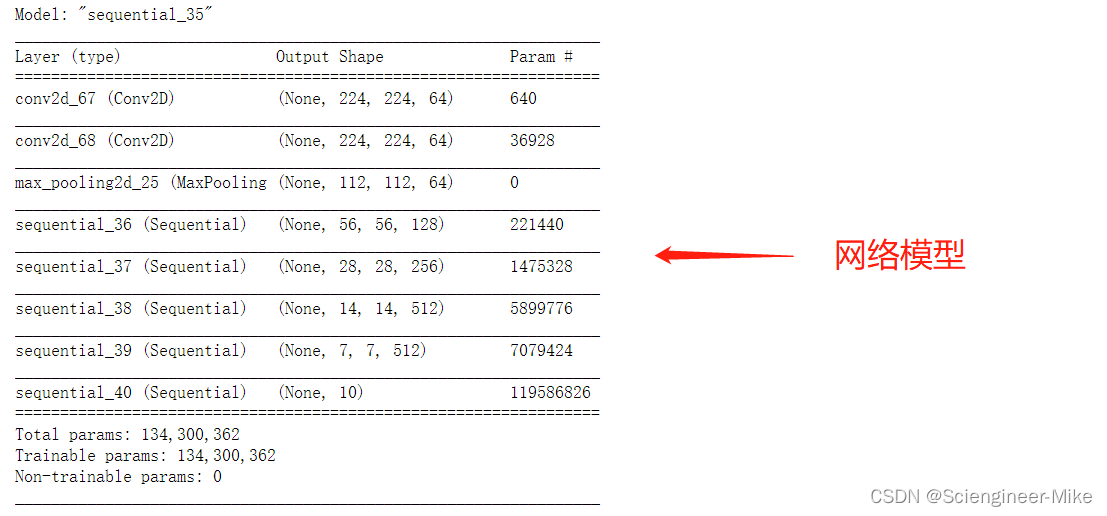
vgg_net.summary()
# 指定优化器,损失函数和评价指标
optimizer = tf.keras.optimizers.SGD(learning_rate=0.01, momentum=0.0)
vgg_net.compile(optimizer=optimizer,
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
数据预处理:将mnist数据转换为VGG需要的数据,由于笔记本电脑性能有限,挑选部分数据进行训练展示。代码如下:
# 获取手写数字数据集
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
train_images_224 = []
test_images_224 = []
for i in train_images[:1000]:
train_images = cv2.resize(i,(224,224))
train_images_224.append(train_images)
new_train_image = np.expand_dims(np.array(train_images_224),axis=3)
for i in test_images[:200]:
test_images = cv2.resize(i,(224,224))
test_images_224.append(test_images)
new_test_image = np.expand_dims(np.array(test_images_224),axis=3)
print(new_train_image.shape,new_test_image.shape)

模型训练代码:
# 模型训练:指定训练数据,batchsize,epoch,验证集
vgg_net.fit(new_train_image,train_labels[:1000],batch_size=128,epochs=3,verbose=1,validation_split=0.1)

模型验证代码:
vgg_net.evaluate(new_test_image,test_labels[:200],verbose=1)
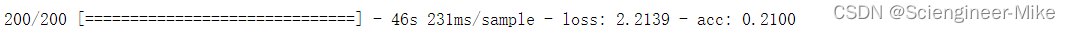
到这里,为大家解读了经典深度学习算法模型AlexNet和VGG,另外两个算法见下篇。
链接: 【深度学习】经典算法解读及代码复现AlexNet-VGG-GoogLeNet-ResNet(二)