一、引言:
2006年Hinton他们的Science Paper再次引起人工神经网络的热潮,当时提到,2006年虽然Deep Learning的概念被提出来了,但是学术界的大家还是表示不服。当时有流传的段子是Hinton的学生在台上讲paper时,台下的机器学习大牛们不屑一顾,质问你们的东西有理论推导吗?有数学基础吗?搞得过SVM之类吗?回头来看,就算是真的,大牛们也确实不算无理取闹,是骡子是马拉出来遛遛,不要光提个概念。
时间终于到了2012年,Hinton的学生Alex Krizhevsky在寝室用GPU死磕了一个Deep Learning模型,一举摘下了视觉领域竞赛ILSVRC 2012的桂冠,在百万量级的ImageNet数据集合上,效果大幅度超过传统的方法,从传统的70%多提升到80%多。个人觉得,当时最符合Hinton他们心境的歌非《我不做大哥好多年》莫属。
这个Deep Learning模型就是后来大名鼎鼎的AlexNet模型。这从天而降的AlexNet为何能耐如此之大?有三个很重要的原因:
1. 大量数据,Deep Learning领域应该感谢李飞飞团队搞出来如此大的标注数据集合ImageNet;
2. GPU,这种高度并行的计算神器确实助了洪荒之力,没有神器在手,Alex估计不敢搞太复杂的模型;
3. 算法的改进,包括网络变深、数据增强、ReLU、Dropout等,这个后面后详细介绍。
4. 数据扩展:裁剪,镜像,平移,旋转,颜色,光照等。
从此,Deep Learning一发不可收拾,ILSVRC每年都不断被Deep Learning刷榜,如图1所示,随着模型变得越来越深,Top-5的错误率也越来越低,目前降到了3.5%附近,而在同样的ImageNet数据集合上,人眼的辨识错误率大概在5.1%,也就是目前的Deep Learning模型的识别能力已经超过了人眼。而图1中的这些模型,也是Deep Learning视觉发展的里程碑式代表。

图1. ILSVRC历年的Top-5错误率
在仔细分析图1中各模型结构之前我们先需要了解一下深度学习三驾马车之一————LeCun的LeNet网络结构。为何要提LeCun和LeNet,因为现在视觉上这些神器都是基于卷积神经网络(CNN)的,而LeCun是CNN的祖师爷,LeNet是LeCun打造的CNN经典之作。
LeNet以其作者名字LeCun命名,这种命名方式类似的还有AlexNet,后来又出现了以机构命名的网络结构GoogLeNet、VGG,以核心算法命名的ResNet。LeNet有时也被称作LeNet5或者LeNet-5,其中的5代表五层模型。不过别急,LeNet之前其实还有一个更古老的CNN模型。
2.各种网络介绍
2.1 最古老的CNN模型
1985年,Rumelhart和Hinton等人提出了后向传播(Back Propagation,BP)算法[1](也有说1986年的,指的是他们另一篇paper:Learning representations by back-propagating errors),使得神经网络的训练变得简单可行,这篇文章在Google Scholar上的引用次数达到了19000多次,目前还是比Cortes和Vapnic的Support-Vector Networks稍落后一点,不过以Deep Learning最近的发展劲头来看,超越指日可待。
几年后,LeCun利用BP算法来训练多层神经网络用于识别手写邮政编码[2],这个工作就是CNN的开山之作,如图2所示,多处用到了5*5的卷积核,但在这篇文章中LeCun只是说把5*5的相邻区域作为感受野,并未提及卷积或卷积神经网络。关于CNN最原始的雏形感兴趣的读者也可以关注一下文献[10]。
2.2 LeNet
1998年的LeNet5[4]标注着CNN的真正面世,但是这个模型在后来的一段时间并未能火起来,主要原因是费机器(当时苦逼的没有GPU啊),而且其他的算法(SVM,老实说是你干的吧?)也能达到类似的效果甚至超过。
图3. LeNet网络结构
初学者也可以参考一下Caffe中的配置文件:
https://github.com/BVLC/caffe/blob/master/examples/mnist/lenet.prototxt
2.3 AlexNet、VGG、GoogLeNet、ResNet对比
LeNet主要是用于识别10个手写数字的,当然,只要稍加改造也能用在ImageNet数据集上,但效果较差。而本文要介绍的后续模型都是ILSVRC竞赛历年的佼佼者,这里具体比较AlexNet、VGG、GoogLeNet、ResNet四个模型。如表1所示。

表1 AlexNet、VGG、GoogLeNet、ResNet对比
2.4 AlexNet
(1) Data Augmentation
数据增强,这个参考李飞飞老师的cs231课程是最好了。常用的数据增强方法有:
水平翻转
随机裁剪、平移变换
颜色、光照变换
(2) Dropout
Dropout方法和数据增强一样,都是防止过拟合的。Dropout应该算是AlexNet中一个很大的创新,以至于Hinton在后来很长一段时间里的Talk都拿Dropout说事,后来还出来了一些变种,比如DropConnect等。
(3) ReLU激活函数
用ReLU代替了传统的Tanh或者Logistic。好处有:
ReLU本质上是分段线性模型,前向计算非常简单,无需指数之类操作;
ReLU的偏导也很简单,反向传播梯度,无需指数或者除法之类操作;
ReLU不容易发生梯度发散问题,Tanh和Logistic激活函数在两端的时候导数容易趋近于零,多级连乘后梯度更加约等于0;
ReLU关闭了右边,从而会使得很多的隐层输出为0,即网络变得稀疏,起到了类似L1的正则化作用,可以在一定程度上缓解过拟合。
当然,ReLU也是有缺点的,比如左边全部关了很容易导致某些隐藏节点永无翻身之日,所以后来又出现pReLU、random ReLU等改进,而且ReLU会很容易改变数据的分布,因此ReLU后加Batch Normalization也是常用的改进的方法。
(4) Local Response Normalization
Local Response Normalization要硬翻译的话是局部响应归一化,简称LRN,实际就是利用临近的数据做归一化。这个策略贡献了1.2%的Top-5错误率。
(5) Overlapping Pooling
Overlapping的意思是有重叠,即Pooling的步长比Pooling Kernel的对应边要小。这个策略贡献了0.3%的Top-5错误率。
(6) 多GPU并行
这个不多说,比一臂之力还大的洪荒之力。
2.5 VGG
VGG 16 与VGG 19
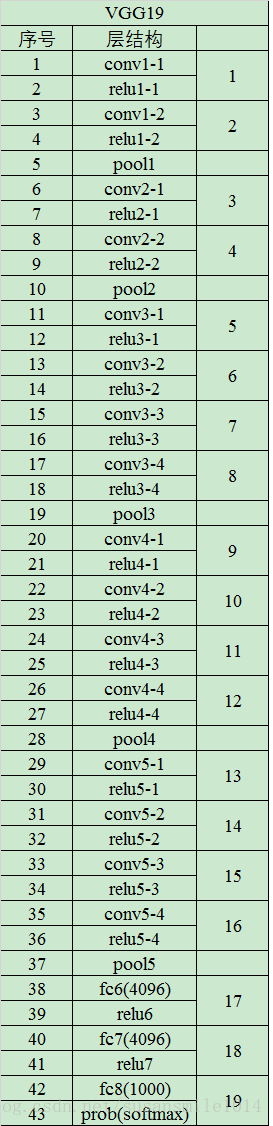
VGG很好地继承了AlexNet的衣钵,一个字:深,两个字:更深。
2. 6 GoogLeNet
主要的创新在于他的Inception,这是一种网中网(Network In Network)的结构,即原来的结点也是一个网络。Inception一直在不断发展,目前已经V2、V3、V4了,感兴趣的同学可以查阅相关资料。Inception的结构如图9所示,其中1*1卷积主要用来降维,用了Inception之后整个网络结构的宽度和深度都可扩大,能够带来2-3倍的性能提升。
2.7 ResNet
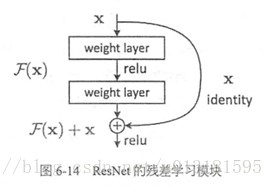
ResNet(Residual Neural Network)由微软研究院的Kaiming He等四名华人提出,通过使用ResNet Unit成功训练出了152层的神经网络,并在ILSVRC2015比赛中取得冠军,在top5上的错误率为3.57%,同时参数量比VGGNet低,效果非常突出。ResNet的结构可以极快的加速神经网络的训练,模型的准确率也有比较大的提升。同时ResNet的推广性非常好,甚至可以直接用到InceptionNet网络中。
ResNet的主要思想是在网络中增加了直连通道,即Highway Network的思想。此前的网络结构是性能输入做一个非线性变换,而Highway Network则允许保留之前网络层的一定比例的输出。ResNet的思想和Highway Network的思想也非常类似,允许原始输入信息直接传到后面的层中,
3.参考:
https://blog.csdn.net/u013181595/article/details/80990930
https://blog.csdn.net/u014114990/article/details/53905649/
