1. 背景知识
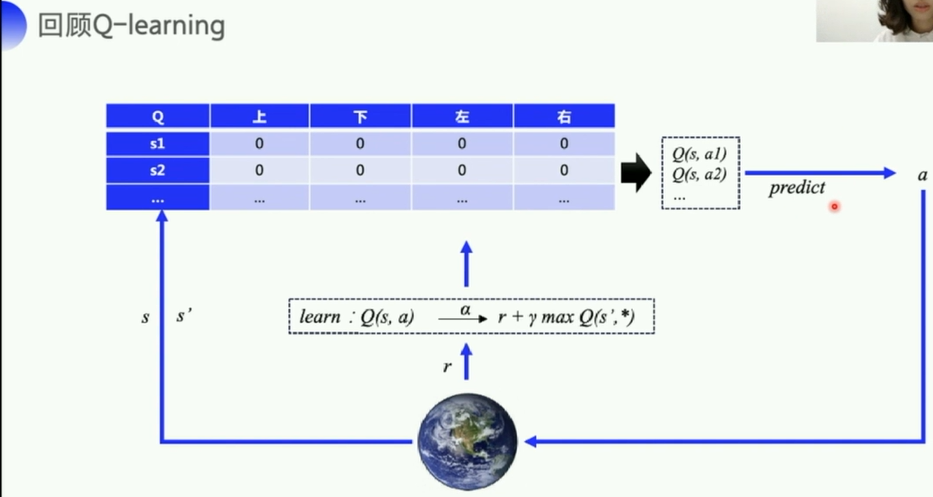
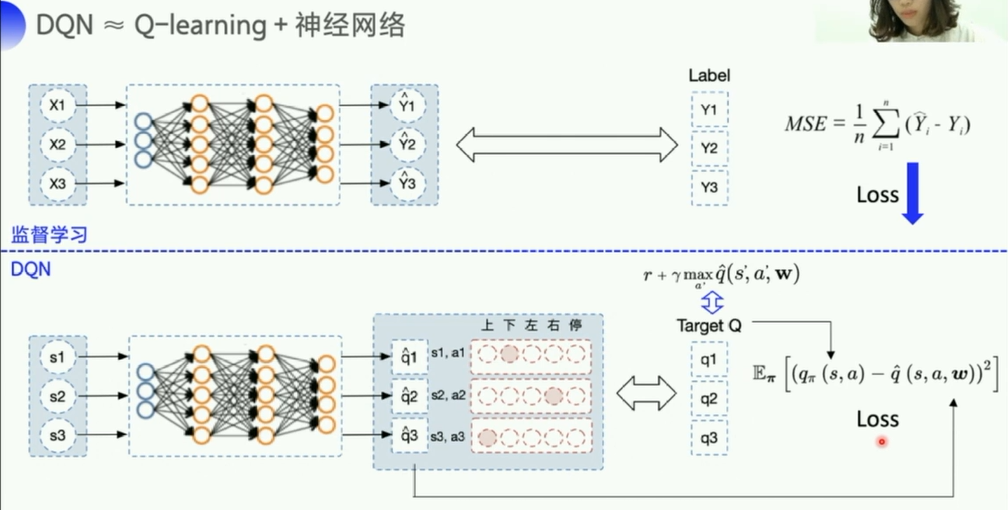
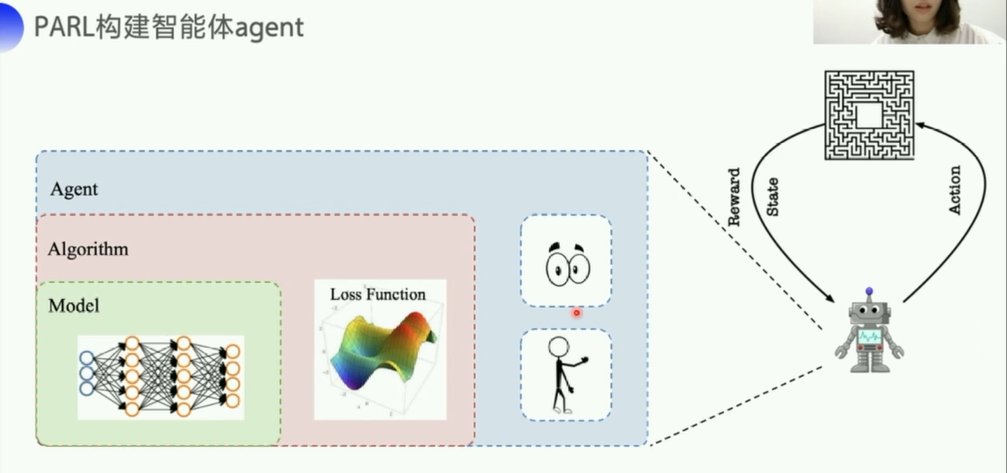
由于Q表格无法应对状态过多的问题,所以这里提出值函数近似这一方式

DQN两大创新点:
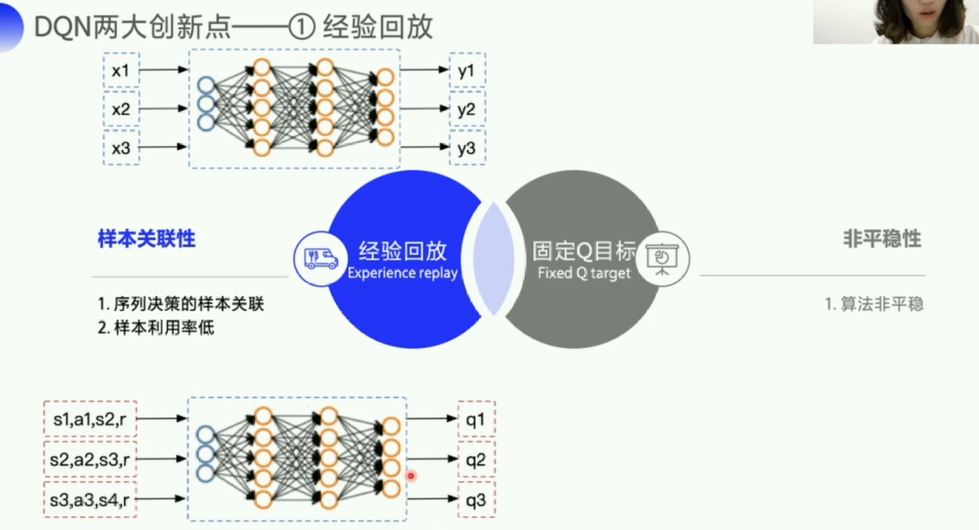
经验回放:充分列用off-policy(样本所带来的经验不是立马更新到Q表格的,而是经过一个策略,所以像离线更新一样,)
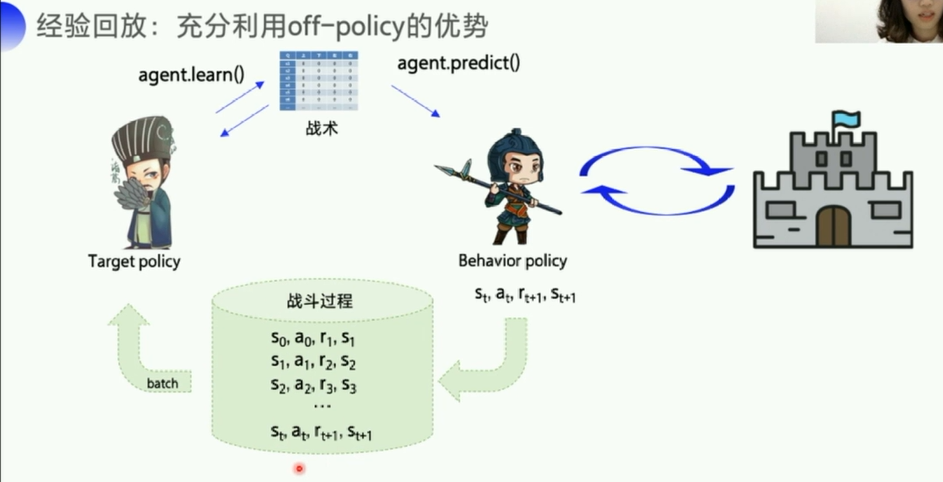
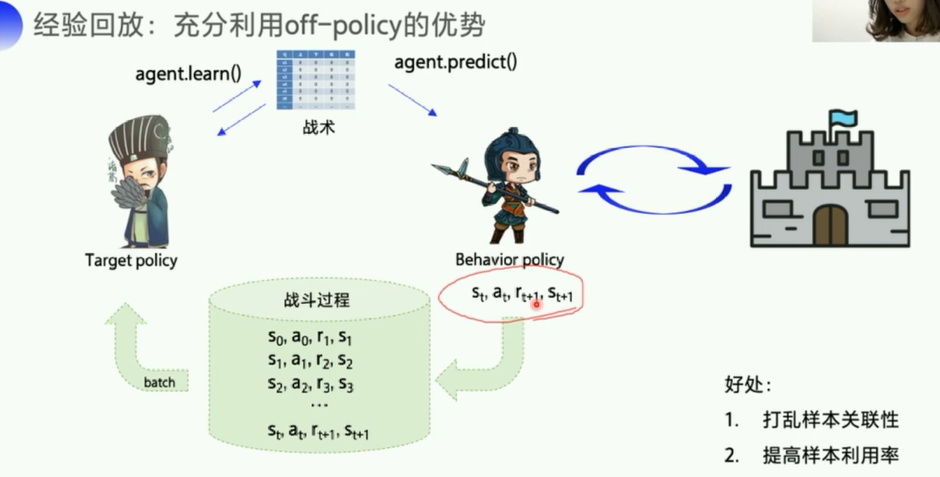
每隔一段时间,更新一下
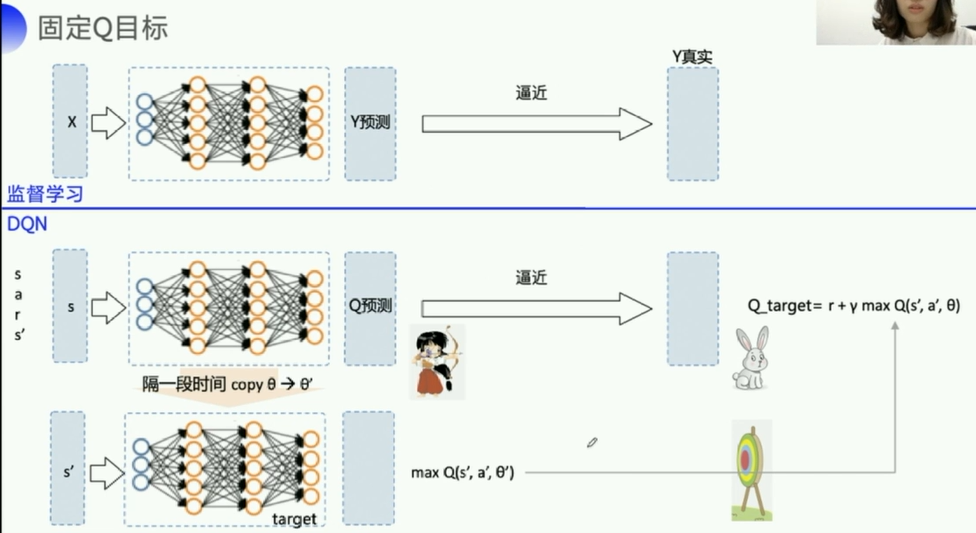
2. DQN算法
DQN的算法其实很简单,引入神经网络来得到Q

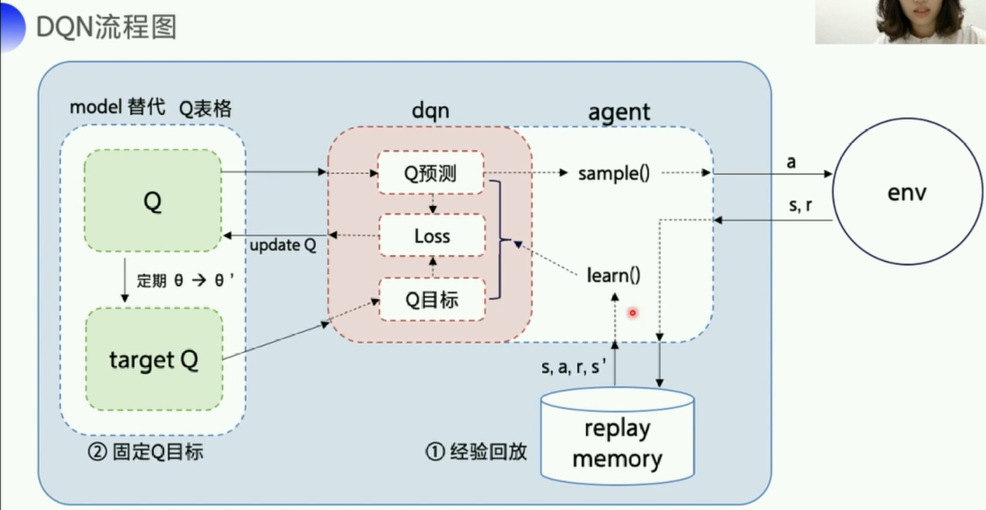
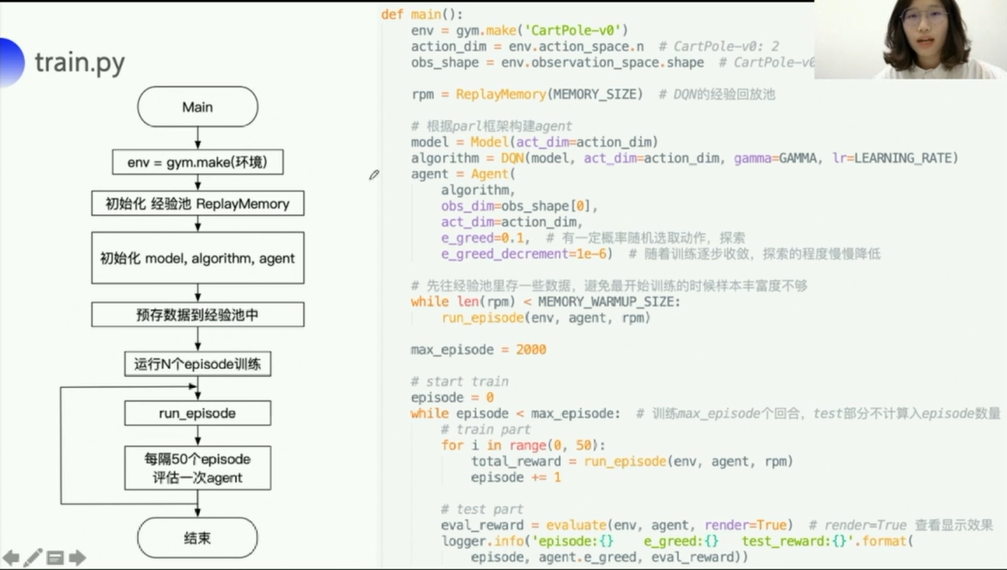
3. DQN代码Parl实现
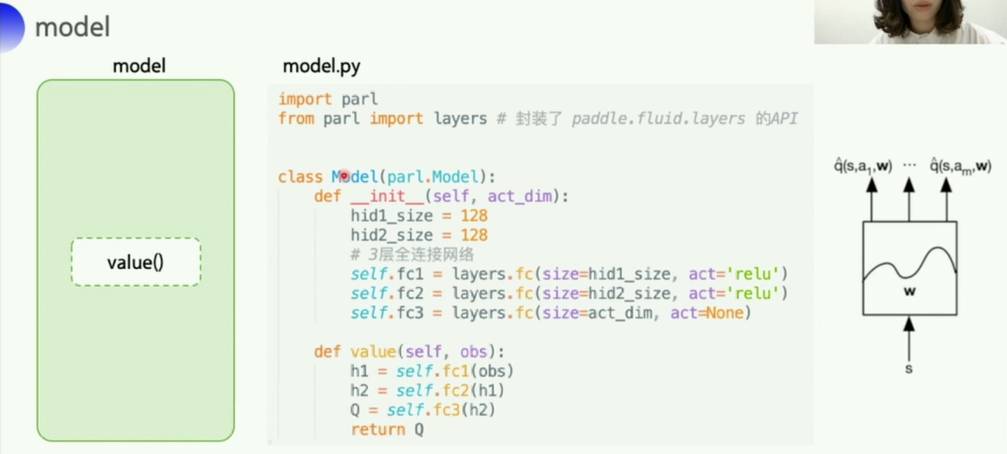
可以看到,这里
- 输入一个
obs(状态/观测值) - 经过一个简单的3层全连接网络
- 输出
act_dim个向量(每个向量应该是128维的。。。) - 也就是说:把这个状态下所有动作的一个Q都输出了
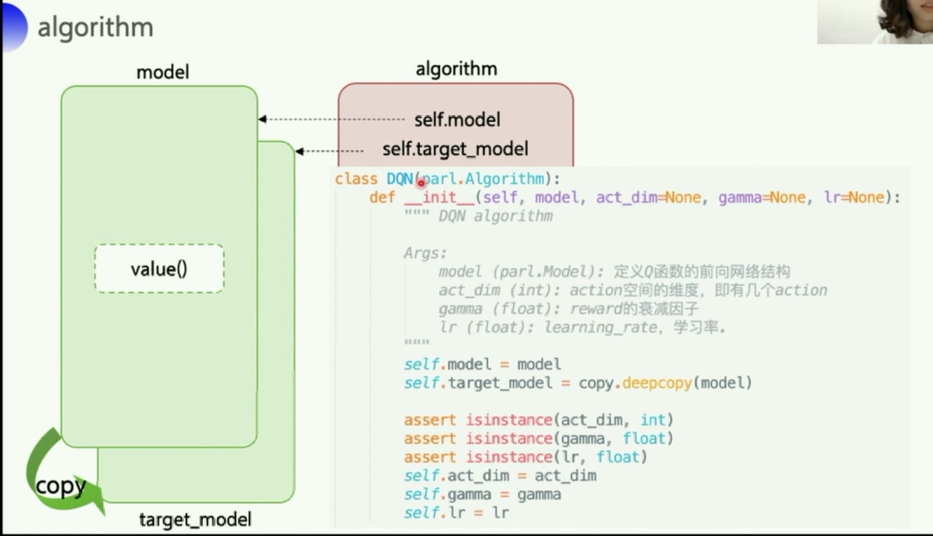
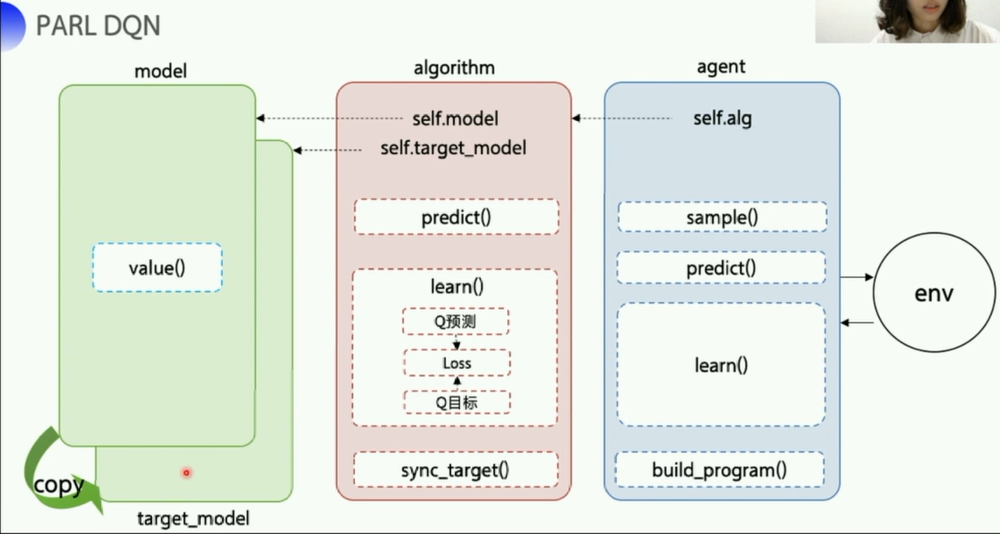
- 这里的DQN算法部分负责和agent部分以及model部分的交互
- 初始化的时候就包括了model
- 关于
copy.deepcopy()复制模型结构到target_model- 关于深复制和浅复制,参考csdn博客:Python—copy()、deepcopy()与赋值的区别
- 反正就是复制出一个完全独立的副本,原来的版本不会受到副本改变的影响
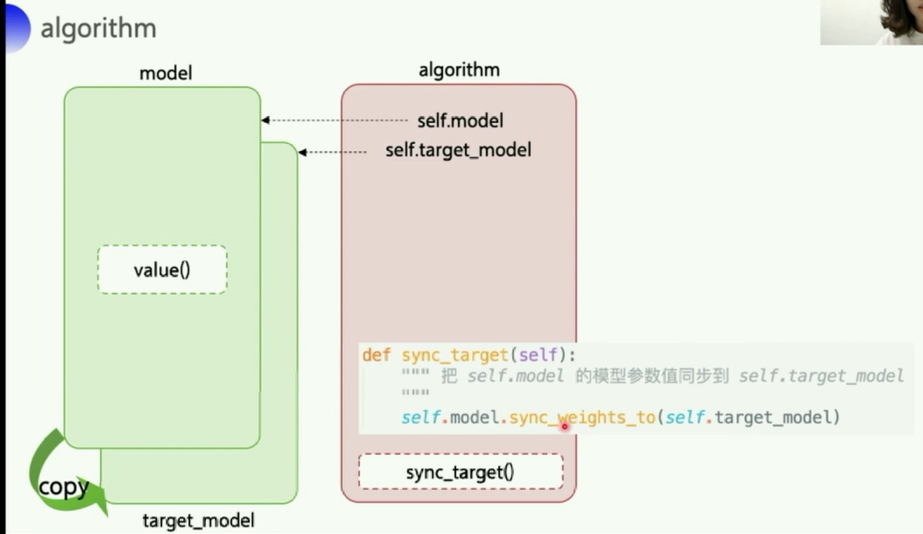
- 这里使用
sync_target()函数包了一个模型权重 复制的函数,sync_weights_to把model的权重复制到target_model中 实现model和target_model之间的同步
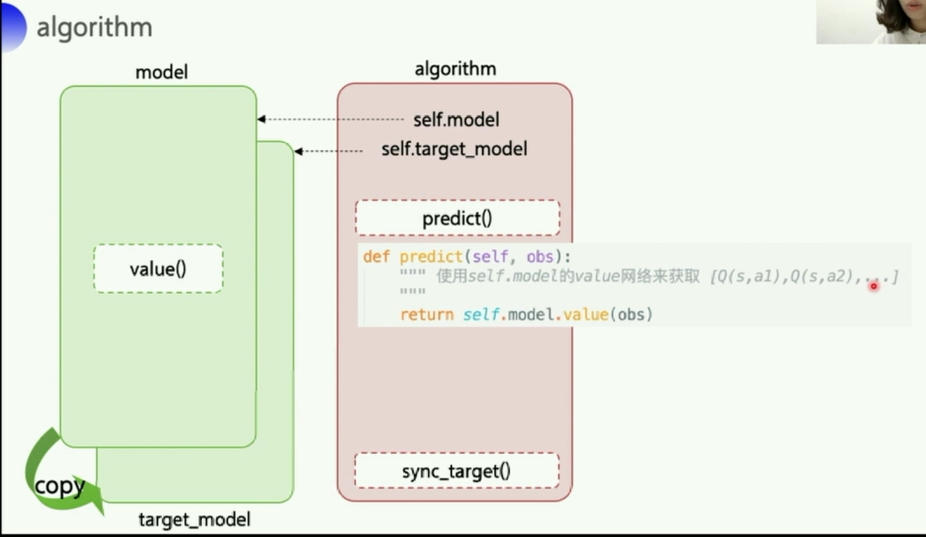
- 关于预测,输入一个
obs观测值,调用model的value()函数,返回的就是一个Q列表,s就是输入的obs,state。Q列表长度等于act_dim,动作长度。

learn()是一个比较关键的部分,其实就做了三个事情- 获取
max_Q'的值用于计算target_Q列表- 这里阻止梯度传播,是因为
target_model的参数要保持固定(从model那里每隔一段时间复制过来的),如果不阻止,在optimizer优化器中,计算cost时会计算出所有相关变量的梯度并进行更新
- 这里阻止梯度传播,是因为
- 拿到
Q列表,然后找到最大的Q(s,a)作为下一个动作- 这里的
elementwise_mul逐元素相乘,然后reduce_sum相加,就是要获取那个one-hot中为1的地方对应的值。
- 这里的
- 计算损失,优化
- 拿到了
target和pred_action_value,一个是目标值,一个是预测值,丢到优化器里进行优化。
- 拿到了
- 获取
- 先往经验池
replay memory里存一些数据,避免最开始训练的时候样本丰富度不够。然后从这个replay memory里sample一个batch的经验出来,给learn()方法,learn()方法的参数刚好就是存储的一个经验的样子obs,action,reward,next_obs,terminal(teminal就是done) - 关于
best_y的计算,对应于上面那个Sety i y_i yi的计算,代码中用了一种比较巧妙的方式,就是先把terminal从bool变成一个浮点数(True→1,False→0)- 如果
terminal是true,则对应就是上面只有reward这一种取值的情况 - 如果是
false,就对应下面那个计算的公式
- 如果

- 这里的
build_program(self)是构建计算图相关的一个函数,参考百度PaddlePaddle的API说明:class paddle.fluid.Programwith fluid.program_guard(self.learn_program)这里的学习计算图,在learn()函数中计算cost的时候使用self.fluid_executor.run(self.learn_program,feed=feed,fetch_list=XXX)这个来执行运行- 这个方法
fluid_executor.run的说明参考百度PaddlePaddle的API说明:fluid.executor - feed提供待学习数据,fetch_list得到相应的结果(即向网络输入
feed,输出fetch_list)
- 此外,专门使用了
self.pred_program来专门计算获取预测的Q值with fluid.program_guard(self.pred_program): obs=layers.data(name="obs",shape=[self.obs_dim],dtype="float32")) self.value=self.alg.predict(obs) self.pred_program在下面的predict()中run的


CartPole这个游戏在强化学习中的地位,相当于其他编程语言的Hello World,一个入门的程序。
可以看到:
- 状态 state 包括:
小车的位置,小车的速度,杆子的角度,杆子顶端摆动的速度 - Episode终止的条件(小车上的杆子倒了)
- 小车可以采取的动作只有两个:
向左推一下或者向右退一下