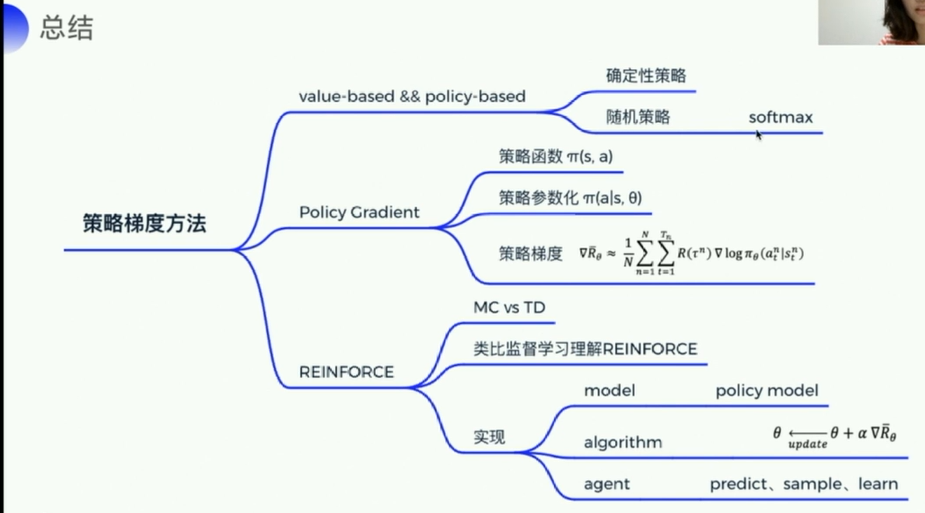
1. 内容讲解
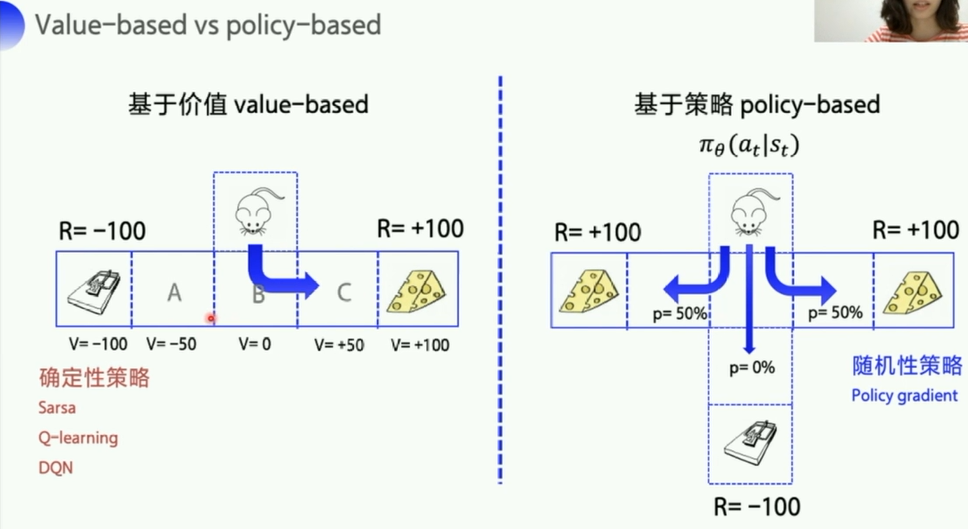
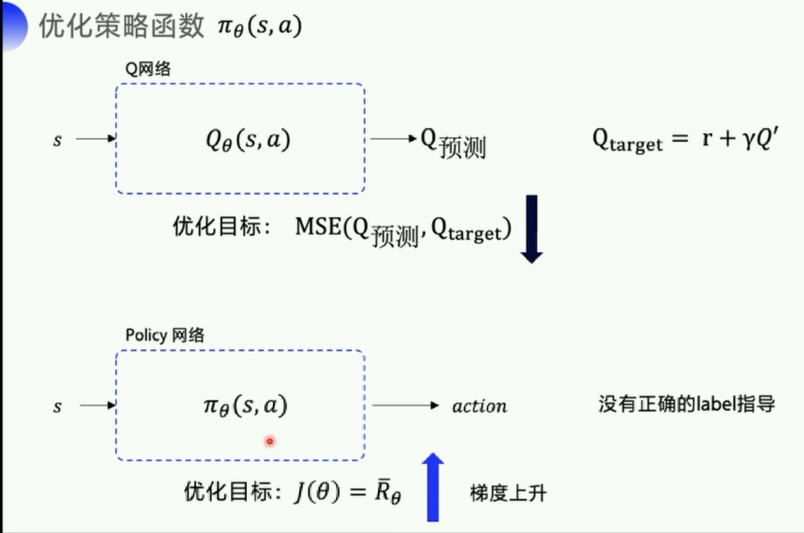
- 基于价值的策略是一般是先计算出价值(比如Q 状态动作价值),根据价值去决定策略
- Value-based的算法的典型代表为Q-learning和SARSA,将Q函数优化到最优,再根据Q函数取最优策略。
- 基于策略的则不再计算价值,直接输出动作概率,动作的选择不再依赖于价值函数,而是先根据一个策略走到底,最后根据最终的收益决定这个策略的好坏
- Policy-based的算法的典型代表为Policy Gradient,直接优化策略函数。
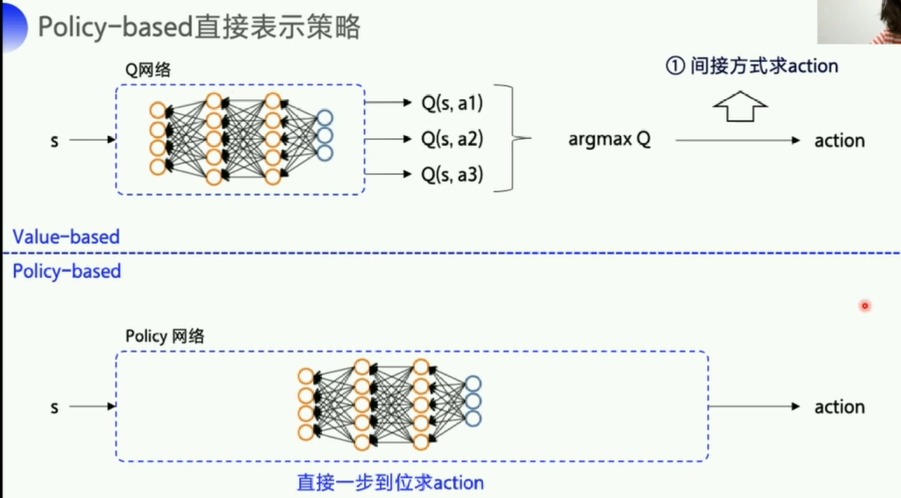
第一个区别:基于价值的,是先求出最优的Q,然后去间接得到action。而基于policy的则是直接输出action的概率。
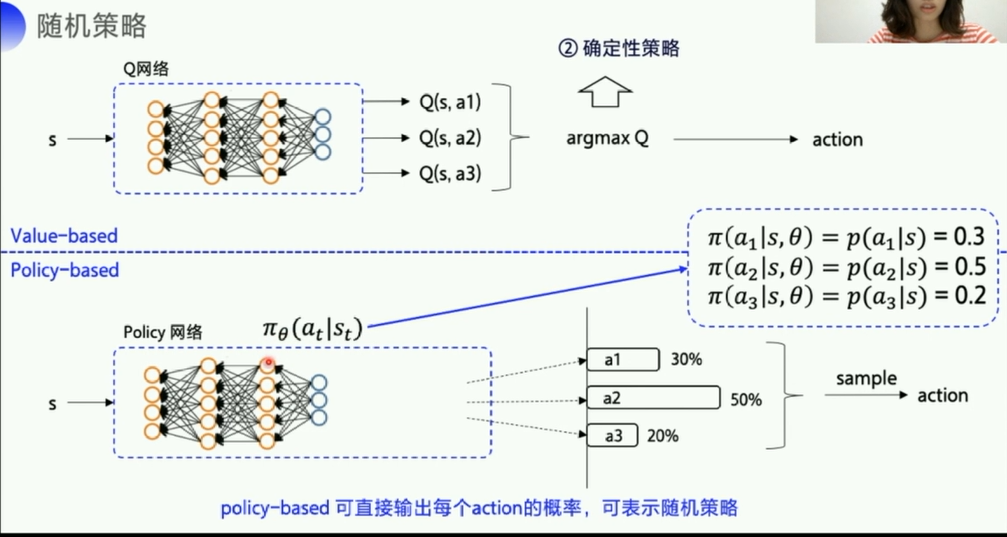
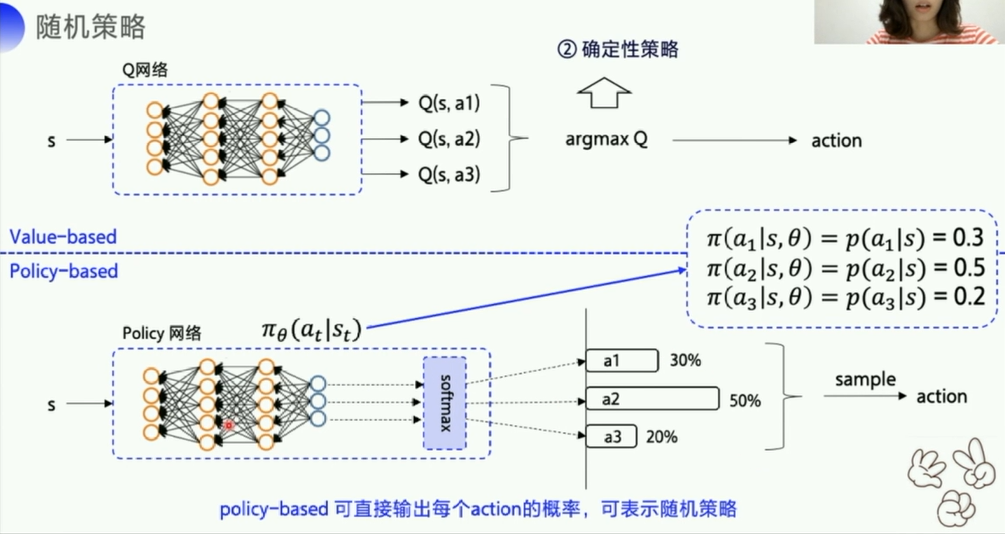
第二个区别:
- value_based会先优化Q网络,把Q的各项优化到最好, 然后再
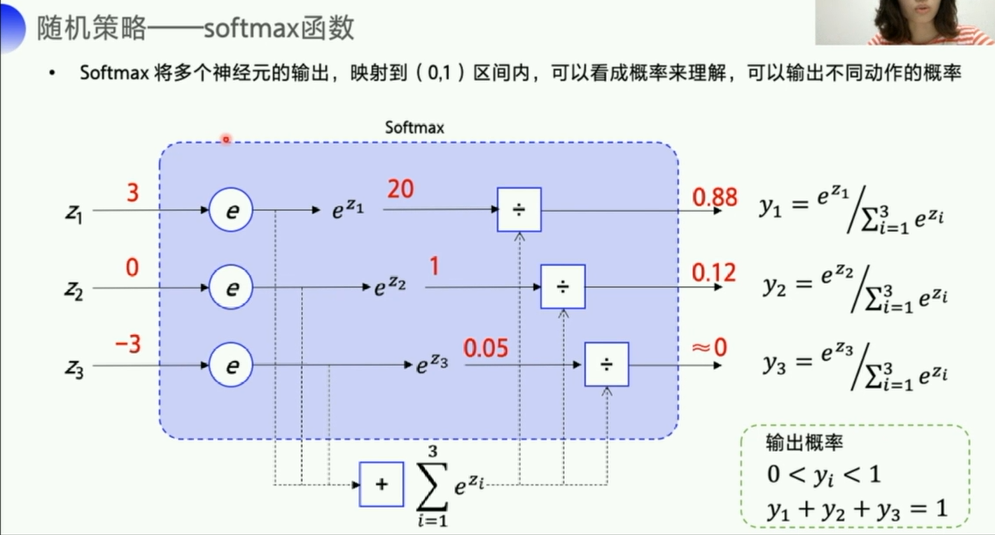
argmax Q来得到一个action,但是这样其实是一个确定性策略(因为Q的各项参数固定了),也就是输入一个s,得到的action就是确定的。 - policy_based输出的是动作的概率,也就是一个随机性的动作,可以表示随机策略。
- 比如石头剪刀布这个游戏,使用value_based就很难模拟出随机性,而使用policy_based就可以比较好的模拟。
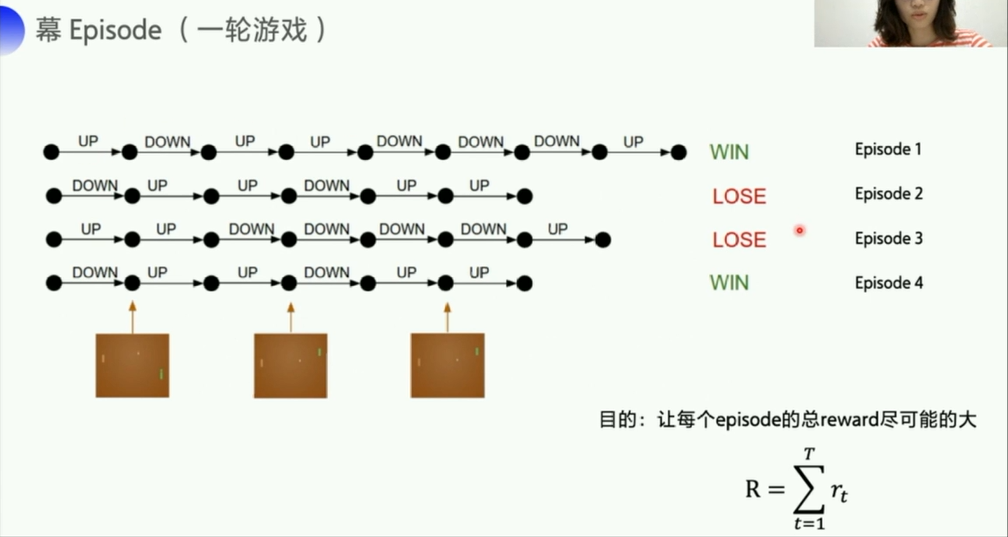
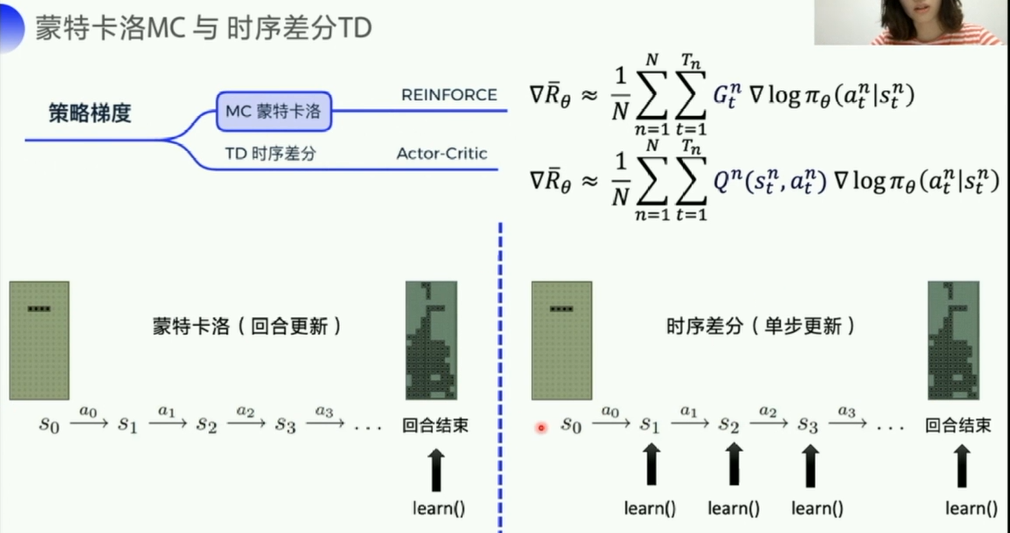
这里求得一个东西(优化目标)和基于值的不一样的,这里的目标是:让每个episode的总reward尽可能的大
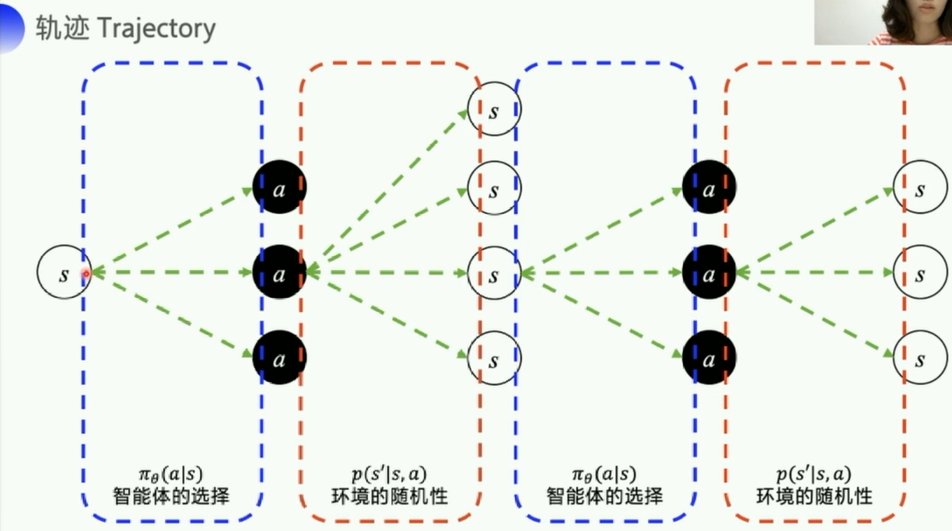

由于实际上,
- 针对model_free的模型,我们基本无法得知: p ( s 2 ∣ s 1 , a 1 ) p(s_2|s_1,a_1) p(s2∣s1,a1)状态转移概率
- 几乎没有可能遍历完所有的轨迹(从开始到结束一条完整的action链),所以这里直接走一部分轨迹,取平均值来代替所有轨迹的期望
- 当N足够大的时候,也是有一定的代表性的


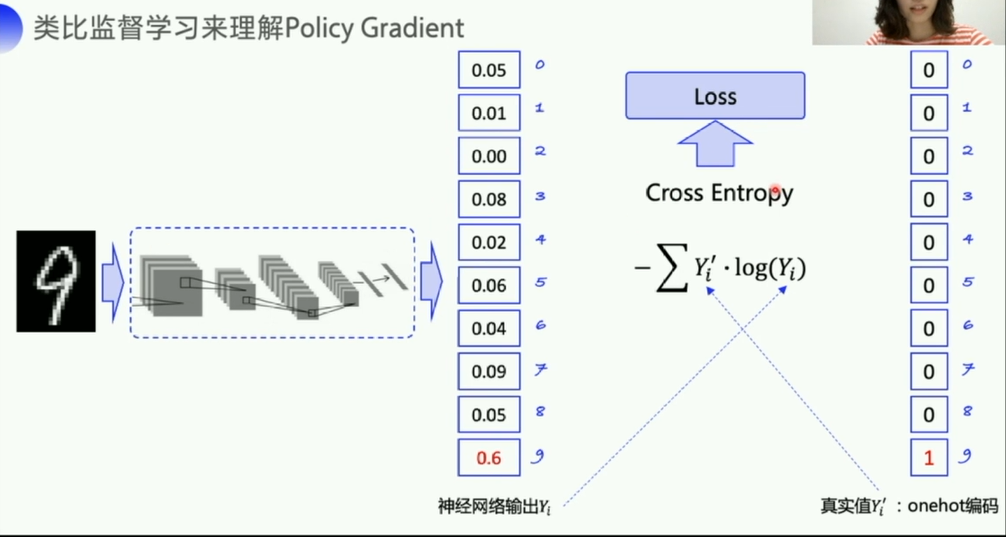 交叉熵可以计算两个概率分布之间的差值,
交叉熵可以计算两个概率分布之间的差值,
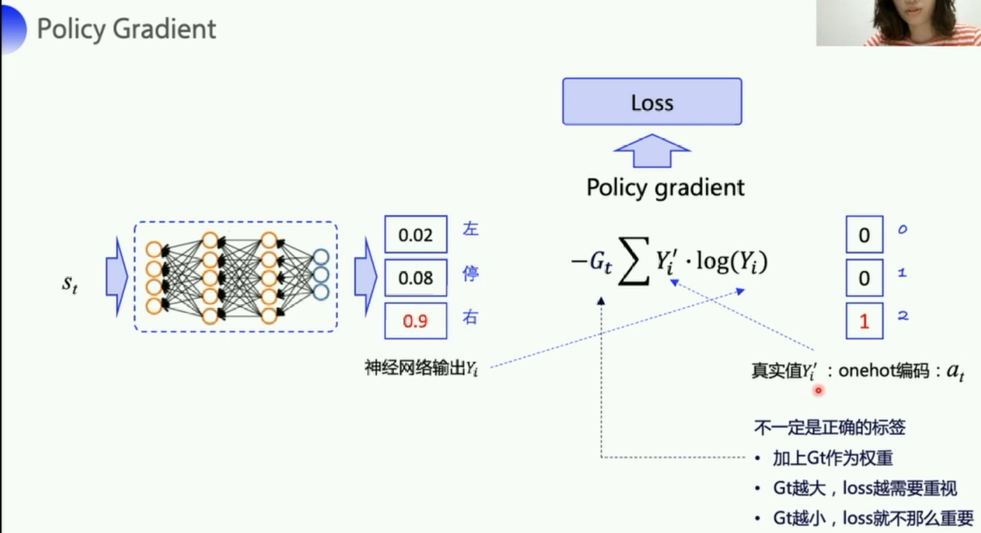
- 正常在计算损失的时候,是没有 G t G_t Gt的,
- 但是由于RL不同于监督学习,真实值不是那个可以用来反馈指导网络的
正确值, - 所以要加一个 G t G_t Gt来评价这个loss的价值,是好还是不好

这里Loss的-R左边多补充一个括号(老师说了,她ppt弄错了,改正一下)
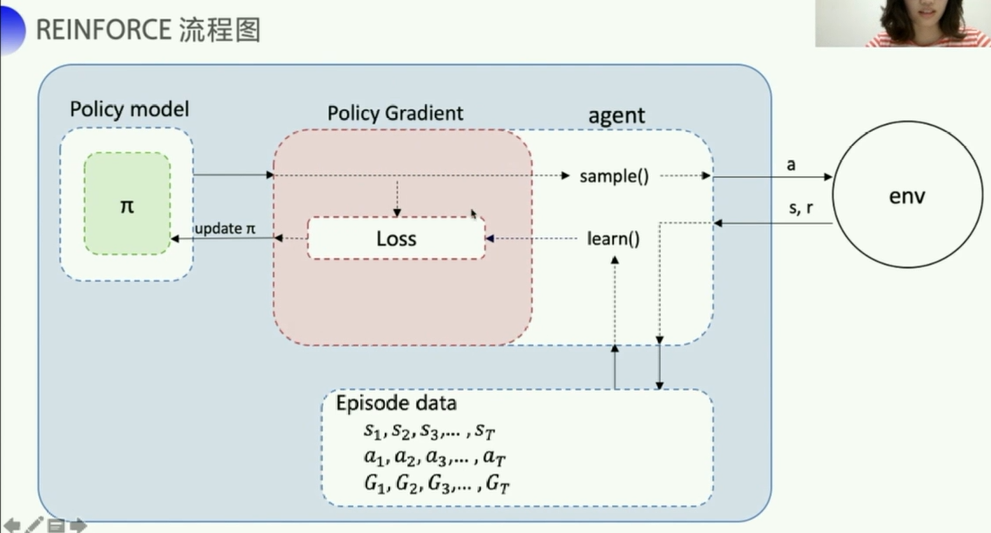
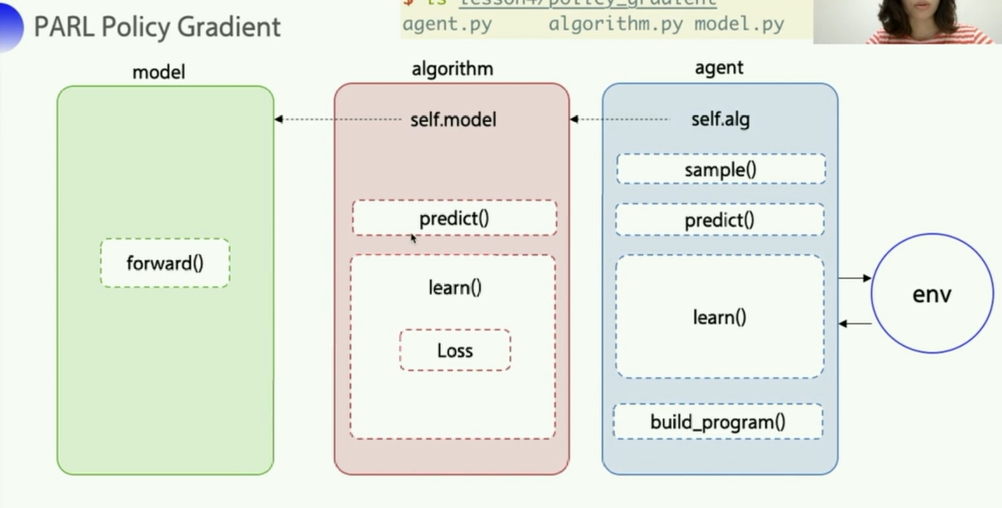

- 这里在
sample函数中先是expand_dims,然后又squeeze是因为,送入网络执行fluid_executor.run的时候,是以batch为单位进行的,所以需要对进入的单条obs包一层,弄好了之后再去一层。

2. 作业(用Policy Gradient解决Pong问题)

注意,这里安装atari-py的时候可能会遇到问题
参考CSDN博客:windows10安装gym环境后运行atari-py失败,但是atari-py已经安装,运行env=gym.make(‘MsPacman-v0’)失败
分三步:
第一步:先卸载atari-py。pip uninstall atari-py
第二步:再重新安装这个。
pip install --no-index -f https://github.com/Kojoley/atari-py/releases atari_py
第三步:pip install gym


