提出了基于mask注意力(实例级别和字符级别)引导的单阶段文本识别框架,不需要使用RoI操作。
AAAI-2021
论文地址:https://arxiv.org/abs/2012.04350
1. 总述
目前大多数方法使用RoI操作,将检测和识别部分连接在一起形成一个端到端的文本识别框架。但是这种两阶段框架识别部分严重依赖于检测结果,这就需要检测部分获得精确的文本区域,而这样则:
- 需要精确的标注,尤其对于不规则文本(多边形)需要更多的时间和精力;
- 很难保证检测部分获得了文本区域是后继识别任务的最佳形式(不紧密会有背景影响,过于紧密会丢失字符信息);
- RoI操作之前需要进行NMS,比较耗时。
传统RoI与本文方法比较:
而已有的一阶段方法很难扩展到字符类别较多的情况(例如中文汉字),因为它会缺失字符间的重要的上下文信息。
为了解决这一问题,本文提出了基于mask注意力(实例级别和字符级别)引导的单阶段文本识别框架,不需要使用RoI操作。具体来说:开发了一个位置感知mask注意模块(PMA-Position-aware Mask Attention,该模块同时包含实例级mask注意力(IMA-Instance-level Mask Attention)和字符级mask注意力(CMA-Character-level Mask Attention)部分。IMA和CMA分别负责感知文本和字符在图像中的位置。文本实例的特征可以直接由位置感知的注意力图来提取,而不是显式的裁剪操作,这样可以最大限度地保留全局空间信息),对每个文本实例及其特征生成注意力权重。它允许将图像中的不同文本实例分配到不同的特征映射通道上,这些通道被进一步分组为一批实例特征。最后,使用一个轻量级的序列解码器来生成字符序列。值得注意的是,MANGO本身就适应任意形状的文本定位(受益于PMA,能够自适应地发现各种不规则文本,不需要任何纠错机制,并且能够学习任意形状文本的阅读顺序),并且只需粗略的位置信息(例如矩形边框)和文本注释就可以进行端到端的训练。
2. 总体结构

提取的图像特征被输入到位置感知mask注意力模块中,以将实例/字符的不同特征映射到不同的通道中。识别器最终一次批量输出字符序列。中心线分割分支用于生成所有文本实例的粗略位置。(前缀“R-”和“C-”分别表示网格行和列。网格数量以6*6为示例(S=6))
对于IMA:
“WELCOME”一词占据了(第2行,第3列)和(第2行,第4列)网格。因此,第9个网格((2−1)×6+3)和第10个网格((2−1)×6+4)将预测相同的注意力mask。如果有两个实例占用同一个网格,只需选择占用率较大的实例。
对于CMA:
还是以“WELCOME”为例,如果L=25(L是预定义的最大字符串长度),则第151个((2−1)×6×25+(3−1)×25+1)通道预测字符“W”的注意力mask,而第152个通道预测“E”,依此类推。
3. PMA
作者发现不同文本实例可以映射到不同的特定的通道中,从而实现实例到特征的映射。将输入图片分为S×S个网格,PMA模块将网格周围的信息映射到特征图的特定通道中。PMA主要包括两部分IMA和CMA。
3.1 IMA
IMA生成实例级别的注意力mask,并将不同实例的特征分配到不同的特征映射通道中。具体来说是通过在切分的网格 G S × S × C G^{S×S×C} GS×S×C上操作一组动态卷积核(参考的是Wang, X.; Zhang, R.; Kong, T.; Li, L.; and Shen, C. 2020c. SOLOv2: Dynamic, Faster and Stronger.arXiv:2003.10152 .)(核大小为1×1)来实现的,IMA可以通过将这些核用于原始特征映射来生成:

x i n s ∈ R S 2 × H × W x_{i n s} \in \mathbb{R}^{S^{2} \times H \times W} xins∈RS2×H×W,生成的特征通道与网格的编号相对应。
为了学习动态卷积核G,需要在文本实例和网格之间进行网格匹配。与一般的目标检测或实例分割任务不同,文本实例通常出现较大的宽高比甚至严重弯曲。直接使用文本边框的中心进行网格匹配是不合理的。因此,本文定义术语-占用率 o i , j o_{i,j} oi,j来表示文本实例 t i t_i ti与网格 g j g_j gj的匹配程度:

其中 A ( . ) A(.) A(.)是区域面积, I n t e r ( , . ) Inter(,.) Inter(,.)是两个区域的相交区域。如果 o i , j o_{i,j} oi,j大于预设的阈值 µ µ µ,则认为文本实例 t i t_i ti占据网格 g j g_j gj。然后 x i n s x_{ins} xins的特征通道 j j j负责学习文本 t i t_i ti的注意力mask。(本文实验中µ设置为0.3)。需要注意的是,在训练阶段,占用率是根据收缩检测到的GT计算的,例如文本中心线区域。
3.2 CMA
许多研究证明字符级位置信息有助于提高文本识别性能。这启发了作者设计全局字符级注意力子模块,为后续的识别任务提供细粒度的特征。如#2中的图所示,CMA首先将原始特征映射 x x x和实例级注意力mask x i n x_{in} xin串联起来,然后通过两个卷积层(核大小=3×3)来预测字符级注意力mask:

x c h a r ∈ R ( S 2 × L ) × H × W x_{char} \in \mathbb{R}^{(S^{2}×L) \times H \times W} xchar∈R(S2×L)×H×W, ⊕ \oplus ⊕是拼接操作。L是预定义的最大字符串长度。采用与IMA相同的网格匹配策略,如果文本实例 t i t_i ti在(row-h,col-w)占据网格 g j g_j gj,则 x c h a r x_{char} xchar的((h−1)×S×L+(w−1)×L+k)通道负责预测文本的第k个字符的注意力mask。
3.3 Sequence Decoding Module
由于不同文本实例的注意力mask被分配到不同的特征通道中,因此需要将文本实例特征打包成一个batch。一个简单的想法是按照[Wang, T.; Zhu, Y.; Jin, L.; Luo, C.; Chen, X.; Wu, Y.; Wang, Q.; and Cai, M. 2020b. Decoupled Attention Network for Text Recognition. In AAAI, 12216–12224]中使用的注意力融合操作来生成批量序列特征 x s e q x_{seq} xseq,即:

x s e q ∈ R S 2 × L × C x_{seq} \in \mathbb{R}^{S^{2}×L \times C} xseq∈RS2×L×C, ⊗ \otimes ⊗是矩阵乘操作, x c h a r ′ ∈ R ( S 2 × L ) × ( H × W ) x_{c h a r}^{\prime} \in \mathbb{R}^{\left(S^{2} \times L\right) \times(H \times W)} xchar′∈R(S2×L)×(H×W)和 x ′ ∈ R C × ( H × W ) x^{\prime} \in \mathbb{R}^{C \times(H \times W)} x′∈RC×(H×W)分别是 x c h a r x_{char} xchar和 x x x的reshaped的矩阵。
然后将文本识别问题转化为纯序列分类问题。后续的序列解码网络负责生成一批( S 2 S^2 S2)字符序列。具体来说,在 x s e q x_{seq} xseq上添加两层双向LSTM(BiLSTM)来捕获序列关系,最后通过一个全连接层输出字符序列。
因为 x i n s x_{ins} xins矩阵大部分情况下是比较稀疏的,所以只关注 x i n s x_{ins} xins中的正样本 ( o i , j > μ ) \left(o_{i, j}>\mu\right) (oi,j>μ)以降低计算成本。
3.3 Text Centerline Segmentation
当图像中有两个以上的文本实例时则需要指出哪些网格对应于这些识别结果,所以需要知道文本实例的粗略位置。本文使用基于分割的文本检测方法来学习单个文本实例的全局文本中心线区域分割(或收缩GT)。
4. 训练推理
训练:
因为本文的主体是在识别部分作用,而如果没有位置信息识别结果也会受到影响,所以本文框架采取两步训练:
- 第一步:将IMA和CMA的学习视为分割任务,与中心线区域分割任务一起学习;
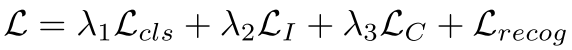
- 第二步:得到的预训练模型后再结合其他的一些部分就可以进行端到端的文本识别。
推理:
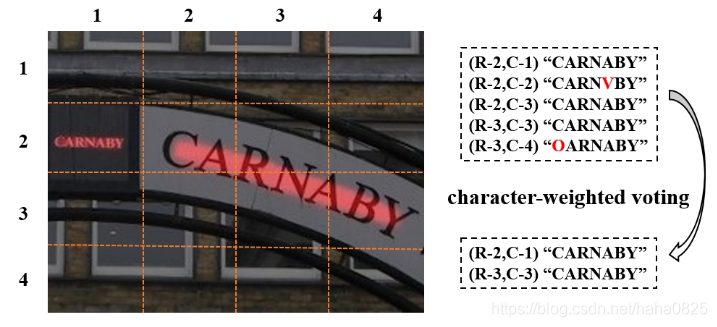
推理时通过特征加权投票策略将所有占用网格的结果合并生成最终的预测结果。
5. 实验
(1)IC13和IC15上的结果
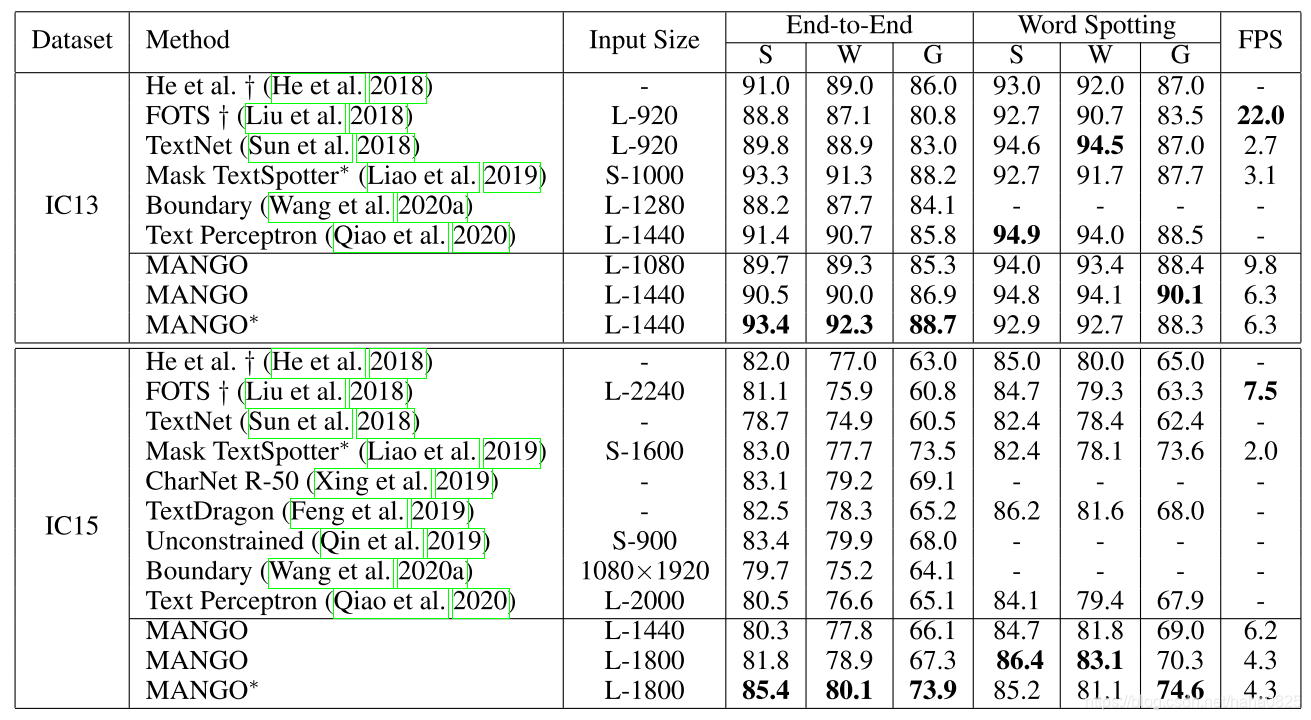
‘S’、‘W’和‘G’分别表示具有强、弱和通用词汇的识别。上标“*”表示该方法使用特定词汇。带†标记的方法不支持不规则文本。前缀“L-”和“S-”分别表示按长边和短边调整输入图像的大小。
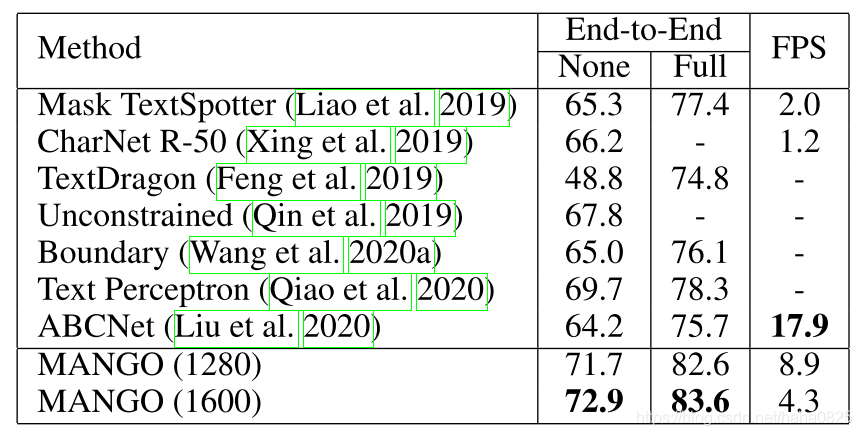
(2)Total-Text上的结果
(3)CTW1500上的结果

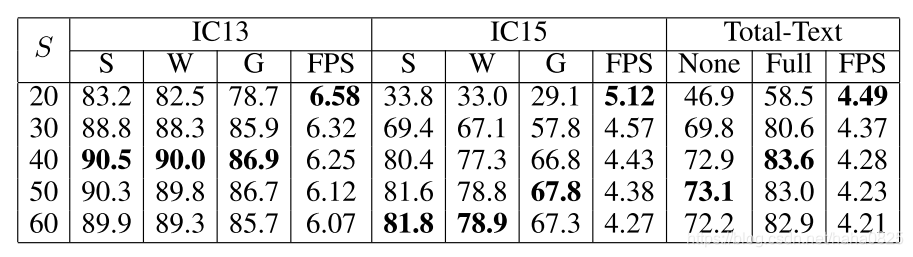
(4)使用不同的网格数量的对比结果
(5)End-to-End recognition precision results on CCPD
