为什么ReLu要好过于tanh和sigmoid?
解析: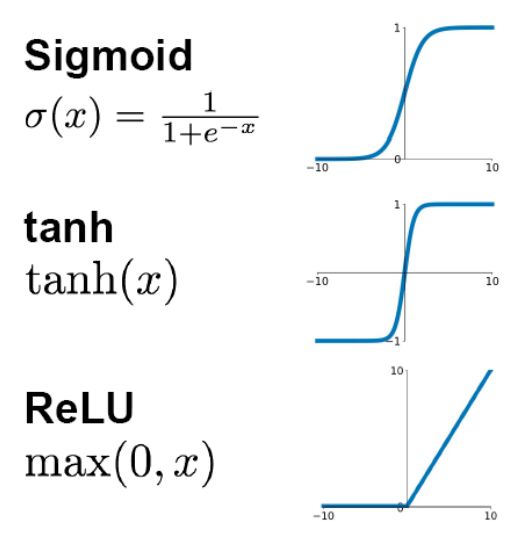 先看sigmoid、tanh和RelU的函数图:
先看sigmoid、tanh和RelU的函数图:
第一,采用sigmoid等函数,算激活函数时(指数运算),计算量大。
反向传播求误差梯度时,求导涉及除法和指数运算,计算量相对大,而采用Relu激活函数,整个过程的计算量节省很多。
第二,对于深层网络,sigmoid函数反向传播时,很容易就会出现梯度消失的情况(在sigmoid接近饱和区时,变换太缓慢,导数趋于0,这种情况会造成信息丢失。),这种现象称为饱和,从而无法完成深层网络的训练。
而ReLU就不会有饱和倾向,不会有特别小的梯度出现。
第三,Relu会使一部分神经元的输出为0,这样就造成了网络的稀疏性,并且减少了参数的相互依存关系,缓解了过拟合问题的发生(以及一些人的生物解释balabala)。
当然现在也有一些对relu的改进,比如prelu,random relu等,在不同的数据集上会有一些训练速度上或者准确率上的改进,具体的大家可以找相关的paper看。
多加一句,现在主流的做法,会多做一步batch normalization,尽可能保证每一层网络的输入具有相同的分布[1]。
而最新的paper[2],他们在加入bypass connection之后,发现改变batch normalization的位置会有更好的效果。大家有兴趣可以看下。
[1] Ioffe S, Szegedy C. Batch normalization: Accelerating deep network training by reducing internal covariate shift[J]. arXiv preprint arXiv:1502.03167, 2015.
[2] He, Kaiming, et al. "Identity Mappings in Deep Residual Networks." arXiv preprint arXiv:1603.05027 (2016).
本题解析来源:@Begin Again,链接:https://www.zhihu.com/question/29021768