激活函数
实际中的很多事情并不能简单的用线性关系的组合来描述。在神经网络中,如果没有激活函数,那么就相当于很多线性分类器的组合,当我们要求解的关系中存在非线性关系时,无论多么复杂的网络都会产生欠拟合。激活函数就是给其加入一些非线性因素,使其能够处理复杂关系。
1.Sigmoid函数:把输入值映射到[0,1],其中0表示完全不激活,1表示完全激活
其图像为:
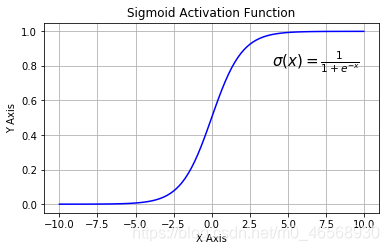
sigmoid函数的导数为:
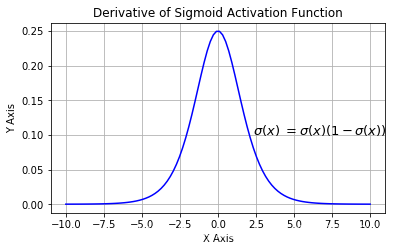
缺点:①sigmoid函数的导数取值范围在[0,0.25]之间,在深度网络中,需要用链式法则多次求导,导数为多个在[0,0.25]之间的数相乘,结果趋于0,导致梯度消失,使参数无法进行更新
②我们希望输入每层神经网络的特征是以0为均值的小数值,但经过sigmoid函数后的数据都是正数,使收敛变慢
③ Sigmoid函数存在幂运算,计算复杂度大,训练时间长
2.tanh函数:tanh函数和sigmoid函数长相很相近,都是一条S型曲线,但tanh函数把输入值映射到【-1,1】。其函数图像为:
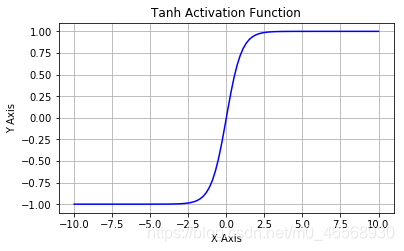
对比sigmoid和tanh函数图像可发现,sigmoid函数在|x|>4之后曲线非常平缓,无限趋近于0或1,而tanh函数在sigmoid函数在|x|>2之后曲线非常平缓,无限趋近于-1或1,这就导致了两者收敛速度的差异。
tanh函数的导数为:
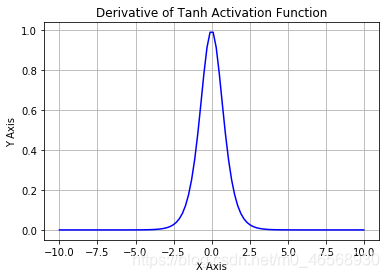
特点: ①经过tanh函数的输出为0均值,使得其收敛比sigmoid加快
②由于其导数依旧是在[0,1]区间上,因此梯度消失问题依然存在
③需要幂运算,计算慢
3.Relu函数:分段函数 y=max(0,x)
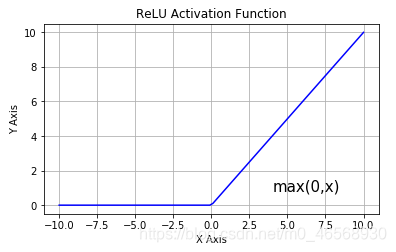
优点:在正区间上解决了梯度消失问题
只需判断输入是否大于0,计算速度快
收敛速度快
缺点: ①输出非0均值,收敛变慢
②当送入激活函数的特征是负数时,激活函数输出为0,反向传播的梯度为0 ,导致参数无法更新,造成神经元死亡。可通过改进初始化和设置更小学习率,避免产生过多负数特征进入激活函数,导致过多神经元死亡
4.leaky relu函数:为了避免神经元死亡产生的,它具备relu激活函数的所有优点,且弥补了relu的缺陷
其函数表达式为:
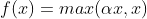
其图像为:
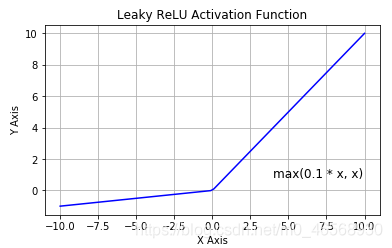
通过给在小于0的区间上一定的函数值,避免了神经元死亡。