为了保证神经元的计算包含简洁性和功能性,神经元的计算包括线性计算和非线性计算。
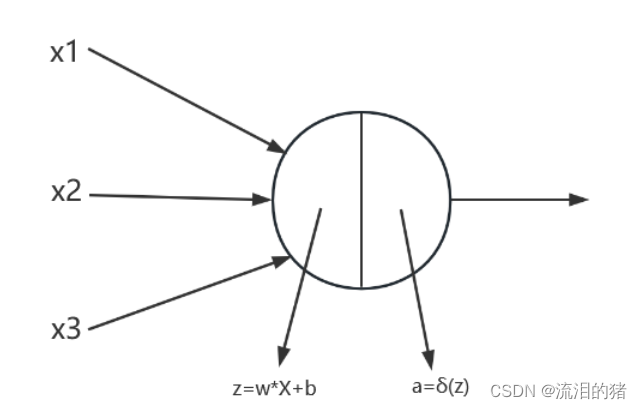
今天主要讲集中非线性计算(即激活函数),包括:
sigmoid
tanh
ReLU
leaky ReLU
1、sigmoid函数
sigmoid函数可以将输出映射到(0,1)的区间,适合做二分类任务。
sigmoid函数公式:
其导数为:
sigmoid函数图形为:
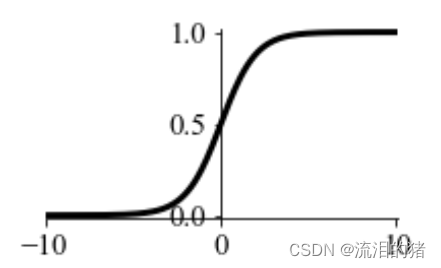
sigmoid函数具有平滑易于求导的优点,但是它的计算量大,反向传播时,容易出现梯度消失的情况,从未无法完成深层网络训练。
2、tanh函数
tanh函数和sigmoid函数十分相似,不同的是tanh会将输出映射到(-1,1)。
tanh函数公式:
tanh函数导数:
tanh函数图形为:
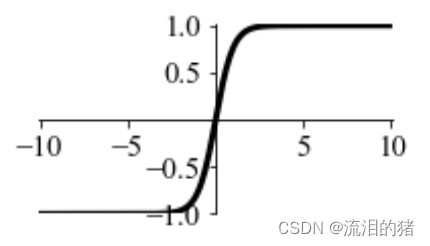
sigmoid函数和tanh函数是最早被研究的激活函数,tanh是sigmoid函数的改进版,改进了sigmoid函数不是以零为中心的问题,加快了收敛速度。因此在实际使用中,更多地是采用tanh函数。
梯度消失问题:
虽然tanh在一定程度上改进了sigmoid函数,但是观察这两种函数的图像会发现,当自变量很大或很小时,图形的斜率是接近0的。也就是说,当输入绝对值非常大的值时,输出值的变化不明显,这就是梯度消失问题。
3、ReLU
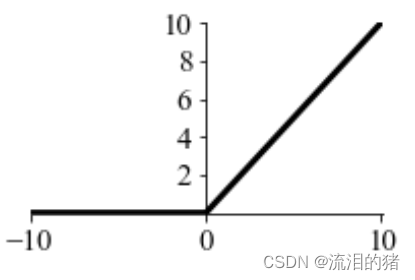
为了解决梯度消失问题,通常采用ReLU(Linear rectification function 修正线性单元)。
ReLU公式:
ReLU导数:
ReLU图形形状:
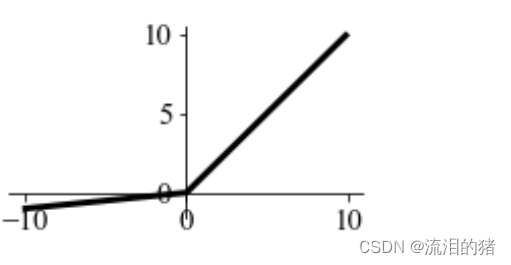
4、leaky ReLU
leaky ReLU是ReLU的一个变种,当x<0时,函数的梯度不为0,而是一个很小的常数 ,如0.01。
leaky ReLU公式:
leaky ReLU导数:
leaky ReLU图形:
在神经网络中,不同层可以有不同的激活函数,在二元分类任务时,我们可以在最后一层(即输出层)采用sigmoid函数,其它层采用ReLU或leaky ReLU。