Spring Batch
背景
项目需要将一部分老数据进行迁移,谷歌百度一番,自己决定就用spring batch了.资料是真滴挺少的,反正就是很多坑,一步步踩完了.记录下,顺便也给网友们提供下帮助.
主要应用大概就是我需要读一部分数据,然后对他进行一部分操作,然后写入某个地方.对应于流程于reader->processor->writer
引用下wiki上的介绍
Spring Batch是批处理的开源框架。它是一种轻量级,全面的解决方案,旨在实现强大的批处理应用程序的开发,这些应用程序常见于现代企业系统中。 Spring Batch构建于Spring Framework的基于POJO的开发方法之上。
使用
简单讲下 spring batch.这里我写的 demo 是根据性别 gender 的传参将 person 中的数据读出,然后把 person 的 name, id 写入 task ,并将 person 的 updateDate 更新.
spring batch的配置与结构
spring batch 的最基本单位是 job,而 job 下是使用 step 作为他更小的节点,step 中还有 tasklet,是更小的任务 tasklet,然后就是 chunk,可以指定 chunk 大小,chunk 中是 reader processor writer 一直循环处理,以 chunk 的 size 作为一次循环.
配置 spring batch 其实主要是为了自定义一些属性,因为 spring boot 已经讲最基本的配置配置好了,我们可以直接继承 DefaultBatchConfigurer 进行一些配置的修改,首先这里如果是用 web 去启动服务,我们肯定需要将任务异步进行,所以需要重写一下运行 job 的 jobLauncher,让他使用异步的线程池.需要注意的是 JobRegistryBeanPostProcessor 这个类,要将 JobRegistry 注入进去,否则就会出现任务停不了的问题. 还有使用 @EnableBatchProcessing 才可以使用 @StepScope,不是用 @StepScope 将无法传参. 由于 JobParameter 只存在于每个 job 中,所以如果想要获取 JobParameter 中的参数,需要在需要使用 JobParameter 的地方使用 @StepScope 标识他在 job 的时候才实例化.否则 启动应用就会报错.
import lombok.extern.slf4j.Slf4j;
import org.springframework.batch.core.configuration.JobRegistry;
import org.springframework.batch.core.configuration.annotation.DefaultBatchConfigurer;
import org.springframework.batch.core.configuration.support.JobRegistryBeanPostProcessor;
import org.springframework.batch.core.launch.JobLauncher;
import org.springframework.batch.core.launch.support.SimpleJobLauncher;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.scheduling.concurrent.ThreadPoolTaskExecutor;
import javax.annotation.Resource;
import java.util.concurrent.ThreadPoolExecutor;
/**
* @author Relic
*/
@Slf4j
@Configuration
public class SpringBatchConfiguration extends DefaultBatchConfigurer {
@Resource
private JobRegistry jobRegistry;
@Bean
public JobRegistryBeanPostProcessor getJobRegistryBeanPostProcessor() {
JobRegistryBeanPostProcessor processor = new JobRegistryBeanPostProcessor();
processor.setJobRegistry(jobRegistry);
return processor;
}
@Bean
public ThreadPoolTaskExecutor taskExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(10);
executor.setMaxPoolSize(15);
executor.setKeepAliveSeconds(300);
executor.setRejectedExecutionHandler(new ThreadPoolExecutor.DiscardOldestPolicy());
executor.setQueueCapacity(10000);
executor.setThreadGroupName("spring_batch");
return executor;
}
@Override
protected JobLauncher createJobLauncher() throws Exception {
SimpleJobLauncher jobLauncher = new SimpleJobLauncher();
jobLauncher.setJobRepository(getJobRepository());
jobLauncher.setTaskExecutor(taskExecutor());
jobLauncher.afterPropertiesSet();
return jobLauncher;
}
}
Job
job 作为 spring batch 中最基本的单位,我们要为他配置监听器,step.
Listener
import com.relic.utils.DateFormatUtils;
import lombok.extern.slf4j.Slf4j;
import org.springframework.batch.core.JobExecution;
import org.springframework.batch.core.listener.JobExecutionListenerSupport;
import org.springframework.stereotype.Component;
import java.util.Date;
/**
* @author Relic
*/
@Slf4j
@Component
public class CommonJobListener extends JobExecutionListenerSupport {
private static final String DATE_TIME_FORMAT = "yyyy-MM-dd HH:mm:ss";
@Override
public void beforeJob(JobExecution jobExecution) {
log.info("Job [" + jobExecution.getJobId() + "] start " + DateFormatUtils.format(jobExecution.getStartTime(), DATE_TIME_FORMAT));
}
@Override
public void afterJob(JobExecution jobExecution) {
log.info("Job [" + jobExecution.getJobId() + "] finish " + DateFormatUtils.format(jobExecution.getEndTime(), DATE_TIME_FORMAT));
Date start = jobExecution.getJobParameters().getDate("timestamp");
log.info("Job [" + jobExecution.getJobId() + "] spend {} ms", jobExecution.getEndTime().getTime() - start.getTime());
log.info("Job [" + jobExecution.getJobId() + "] status " + jobExecution.getStatus().name());
}
}
Job
import com.relic.batch.listener.CommonJobListener;
import org.springframework.batch.core.Job;
import org.springframework.batch.core.Step;
import org.springframework.batch.core.configuration.annotation.JobBuilderFactory;
import org.springframework.batch.core.launch.support.RunIdIncrementer;
import org.springframework.context.annotation.Bean;
import org.springframework.stereotype.Component;
import javax.annotation.Resource;
/**
* @author Relic
* @desc
* @date 2019-11-20 10:29
*/
@Component
public class BatchJob {
@Resource
private JobBuilderFactory jobBuilderFactory;
@Resource
private Step batchStep;
@Bean(name = "jobWithParams")
public Job jobWithParams(CommonJobListener commonJobListener) {
return jobBuilderFactory.get("jobWithParams")
.incrementer(new RunIdIncrementer())
.listener(commonJobListener)
.flow(batchStep)
.end()
.build();
}
}
Step
配置 step 需要指定 chunk 的大小,chunk 中 的 reader,processor,writer.
import com.relic.entity.Person;
import com.relic.entity.TaskEntity;
import org.springframework.batch.core.Step;
import org.springframework.batch.core.configuration.annotation.StepBuilderFactory;
import org.springframework.batch.item.ItemProcessor;
import org.springframework.batch.item.ItemReader;
import org.springframework.batch.item.ItemWriter;
import org.springframework.context.annotation.Bean;
import org.springframework.stereotype.Component;
import javax.annotation.Resource;
/**
* @author Relic
* @desc
* @date 2019-11-20 10:31
*/
@Component
public class StepDefinition {
@Resource
private StepBuilderFactory stepBuilderFactory;
@Resource
private ItemReader<Person> personCursorReader;
@Resource
private ItemWriter<TaskEntity> compositeWriter;
@Resource
private ItemProcessor<Person,TaskEntity> personTaskProcessor;
@Bean
public Step batchStep() {
return stepBuilderFactory.get("batchStep").<Person,TaskEntity>chunk(50).reader(personCursorReader)
.processor(personTaskProcessor).writer(compositeWriter).build();
}
}
Reader
reader我需要取出 JobParameter 中的传参,需要用到 @Value("#{jobParameters[xxxxx]}") , xxxxx 参数名称.这里我用的是mybatis的游标reader方法.需要指定 sqlSessionFactory, queryId, 如果有参数就还要指定 parameterValues 其实就是一个 map ,其中 sqlSessionFactory 直接依赖注入, 然后 queryId 就是 mapper 接口中方法的全路径.
import com.relic.entity.Person;
import org.apache.ibatis.session.SqlSessionFactory;
import org.mybatis.spring.batch.MyBatisCursorItemReader;
import org.springframework.batch.core.configuration.annotation.StepScope;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.stereotype.Component;
import javax.annotation.Resource;
import java.util.HashMap;
import java.util.Map;
/**
* @author Relic
* @desc
* @date 2019-11-20 10:43
*/
@Component
public class ReaderDefinition {
@Resource
private SqlSessionFactory sqlSessionFactory;
@Bean
@StepScope
public MyBatisCursorItemReader<Person> personCursorReader(@Value("#{jobParameters[gender]}") String gender) {
MyBatisCursorItemReader<Person> personReader = new MyBatisCursorItemReader<Person>();
personReader.setSqlSessionFactory(sqlSessionFactory);
personReader.setQueryId("com.relic.mapper.PersonMapper.selectByGender");
Map<String, Object> map = new HashMap<String, Object>(4);
map.put("gender", Integer.valueOf(gender));
personReader.setParameterValues(map);
return personReader;
}
}
Processor
processor 需要实现 ItemProcessor<I,O> 接口,I 就是 reader 返回的类型, O 即为经过 processor 处理之后输出的类型, 实现 process 方法,自己进行处理逻辑.
import com.relic.entity.Person;
import com.relic.entity.TaskEntity;
import com.relic.utils.SnowFlake;
import org.springframework.batch.item.ItemProcessor;
import org.springframework.stereotype.Component;
import java.util.Date;
/**
* @author Relic
* @desc
* @date 2019-11-20 13:37
*/
@Component
public class PersonTaskProcessor implements ItemProcessor<Person, TaskEntity> {
@Override
public TaskEntity process(Person person) {
TaskEntity task = new TaskEntity();
task.setId(SnowFlake.newId());
task.setTaskName(person.getName());
task.setTaskStatus(1);
task.setTaskDescription(person.getId().toString());
task.setUpdateDate(new Date());
return task;
}
}
Writer
这里的 writer 我应用的场景需要写两个表, 所以使用的是复合 writer. sqlSessionFactory 还是直接依赖注入, statementId 就将 Mapper 中的更新/插入方法的全路径设置进去, 注意的是, 复合 writer 中的 writer 集合顺序是有影响的!!!
import com.relic.entity.TaskEntity;
import org.apache.ibatis.session.SqlSessionFactory;
import org.mybatis.spring.batch.MyBatisBatchItemWriter;
import org.springframework.batch.item.ItemWriter;
import org.springframework.batch.item.support.CompositeItemWriter;
import org.springframework.context.annotation.Bean;
import org.springframework.stereotype.Component;
import javax.annotation.Resource;
import java.util.ArrayList;
import java.util.List;
/**
* @author Relic
* @desc
* @date 2019-11-20 11:03
*/
@Component
public class WriterDefinition {
@Resource
private SqlSessionFactory sqlSessionFactory;
@Bean
public MyBatisBatchItemWriter<TaskEntity> taskWriter() {
MyBatisBatchItemWriter<TaskEntity> writer = new MyBatisBatchItemWriter<TaskEntity>();
writer.setSqlSessionFactory(sqlSessionFactory);
writer.setStatementId("com.relic.mapper.TaskMapper.insert");
return writer;
}
@Bean
public MyBatisBatchItemWriter<TaskEntity> personWriter() {
MyBatisBatchItemWriter<TaskEntity> writer = new MyBatisBatchItemWriter<TaskEntity>();
writer.setSqlSessionFactory(sqlSessionFactory);
writer.setStatementId("com.relic.mapper.PersonMapper.update");
return writer;
}
@Bean
public CompositeItemWriter<TaskEntity> compositeWriter(ItemWriter<TaskEntity> taskWriter,ItemWriter<TaskEntity> personWriter) {
List<ItemWriter<? super TaskEntity>> writerList = new ArrayList<ItemWriter<? super TaskEntity>>();
writerList.add(taskWriter);
writerList.add(personWriter);
CompositeItemWriter<TaskEntity> writer = new CompositeItemWriter<TaskEntity>();
writer.setDelegates(writerList);
return writer;
}
}
其余非 spring batch 的代码就不放了, 直接放上项目 github 的地址,有需要的同学自己 clone 下来自己运行测试吧.
https://github.com/Lesible/transfer_helper
测试结果
给大家看下结果.
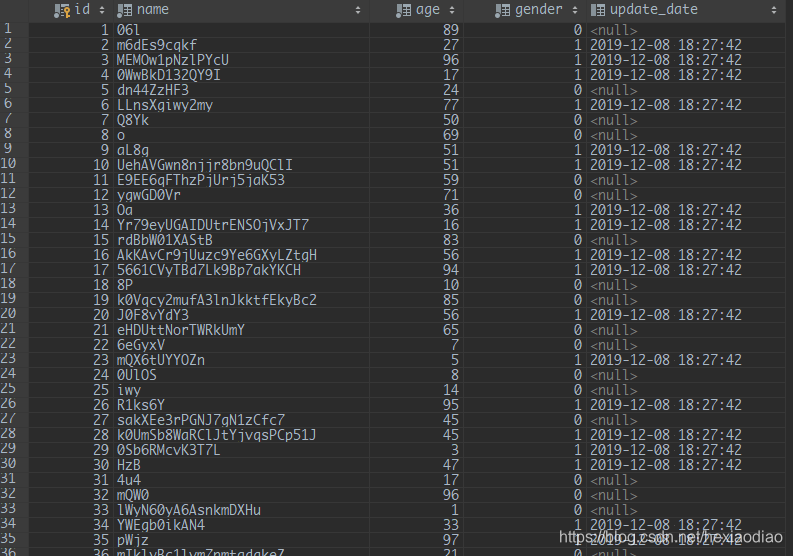
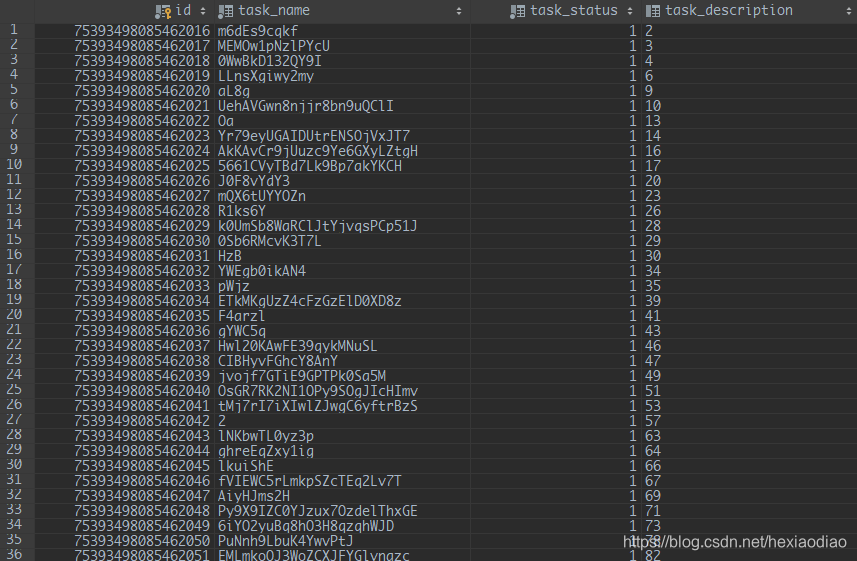
在本地处理5000左右数据大概5秒不到,当然受到带宽的影响肯定会不止这个数值的,但是效果 还是很明显的.
