目录
1 HBase 简介
1.1 HBase 定义
Google的三大马车 Google fs + Map Reduce + Big Table
开源Java实现 HDFS Hadoop Hbase
HBase 是一种分布式、可扩展、支持海量数据存储的 NoSQL 数据库。这东西数据量大就体现出优势了,因为数据量小非常吃内存,他要不断拆分并且和数据也是十分消耗资源的,但是数据量非常大的时候比如几十亿条数据这时候可以做到秒级查询定位到某一条数据,同时也可以增删改查非常快,但是这是资源换时间的一种方式。
1.2 HBase 数据模型
逻辑上,HBase 的数据模型同关系型数据库很类似,数据存储在一张表中,有行有列。
但从 HBase 的底层物理存储结构(K-V)来看,键唯一,重复是更新覆盖操作,HBase 更像是一个 multi-dimensional map。
顺序读写:文件指针只能从头移动到尾。
随机读写:文件指针可以随意移动,根据需要。
1.2.1 HBase 逻辑结构
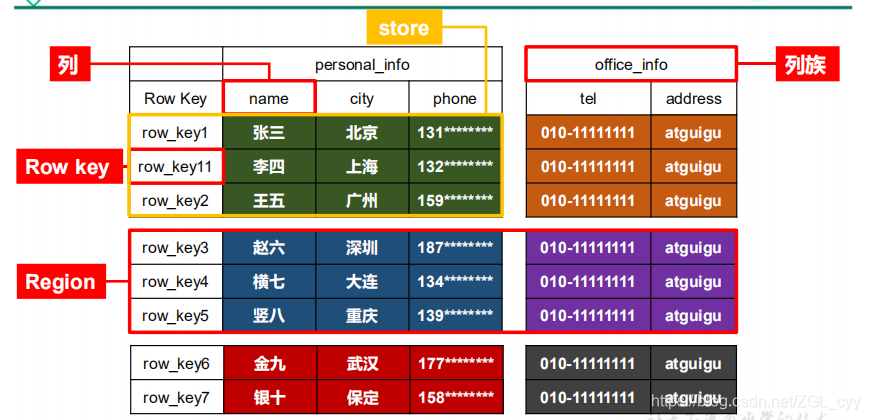
字典序的键名排序,到时候切开是分区进行索引方便查询,必须要有主键
1.2.2 HBase 物理存储结构

时间戳非常重要,因为随机写也是时间戳为关键,所以linux和windows要配套。下面的两个只是修改的不同版本。到时候需要cell才能确定唯一标识
先读行rowkey,然后找到列族,然后再找列Column Qualifier(列限定符),最后读取时间戳,这样才能确定一个值.
1.2.3 数据模型
1)Name Space
命名空间,类似于关系型数据库的 DatabBase 概念,每个命名空间下有多个表。HBase
有两个自带的命名空间,分别是 hbase 和 default,hbase 中存放的是 HBase 内置的表,
default 表是用户默认使用的命名空间。
2)Region
类似于关系型数据库的表概念。不同的是,HBase 定义表时只需要声明列族即可,不需
要声明具体的列。这意味着,往 HBase 写入数据时,字段可以动态、按需指定。因此,和关
系型数据库相比,HBase 能够轻松应对字段变更的场景。
3)Row HBase 表中的每行数据都由一个 RowKey 和多个 Column(列)组成,数据是按照 RowKey
的字典顺序存储的,并且查询数据时只能根据 RowKey 进行检索,所以 RowKey 的设计十分重
要。
4)Column HBase 中的每个列都由 Column Family(列族)和 Column Qualifier(列限定符)进行限
定,例如 info:name,info:age。建表时,只需指明列族,而列限定符无需预先定义。
5)Time Stamp
用于标识数据的不同版本(version),每条数据写入时,如果不指定时间戳,系统会
自动为其加上该字段,其值为写入 HBase 的时间。
6)Cell 由{rowkey, column Family:column Qualifier, time Stamp} 唯一确定的单元。cell 中的数
据是没有类型的,全部是字节码形式存贮。
1.3 HBase 基本架构
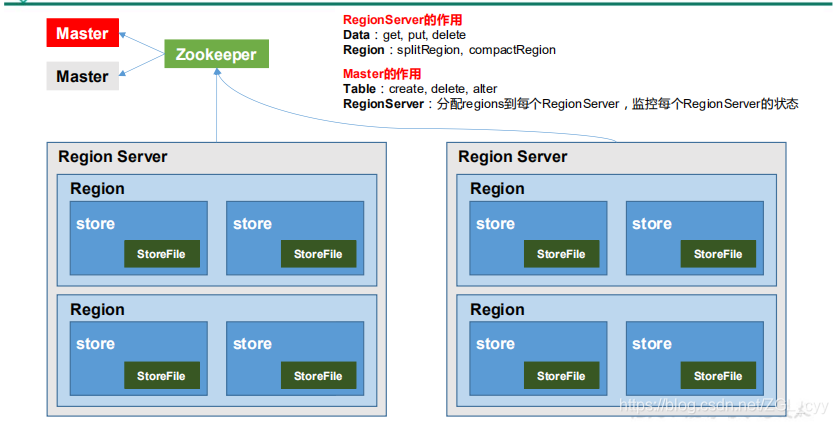
1.3 HBase 基本架构
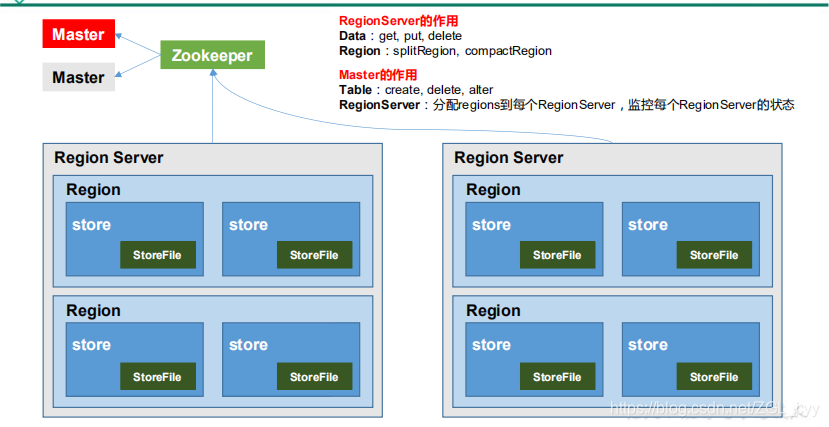
架构角色:
1)Region Server
Region Server 为 Region 的管理者,其实现类为 HRegionServer,主要作用如下:
对于数据的操作:get, put, delete;
对于 Region 的操作:splitRegion、compactRegion。
2)Master
Master 是所有 Region Server 的管理者,其实现类为 HMaster,主要作用如下:
对于表的操作:create, delete, alter
对于 RegionServer的操作:分配 regions到每个RegionServer,监控每个 RegionServer
的状态,负载均衡和故障转移。
3)Zookeeper
HBase 通过 Zookeeper 来做 Master 的高可用、RegionServer 的监控、元数据的入口以及
集群配置的维护等工作不用考虑谁是master,谁抢到zookeeper谁就是。
4)HDFS
HDFS 为 HBase 提供最终的底层数据存储服务,同时为 HBase 提供高可用的支持。