大数据之–Hadoop概述
Hadoop是Google集群系统的开源实现
(1)Google集群系统包括:GFS(Google File System),MapReduce,BigTable
(2)Hadoop主要由HDFS(Hadoop Distributed File System Hadoop分布式文件系统),MapReduce和HBase组成。
(3)其中HDFS来源于Google的论文GFS,通过Java实现GFS的功能,MapReduce来源于Google的MapReduceHadoop的两大核心
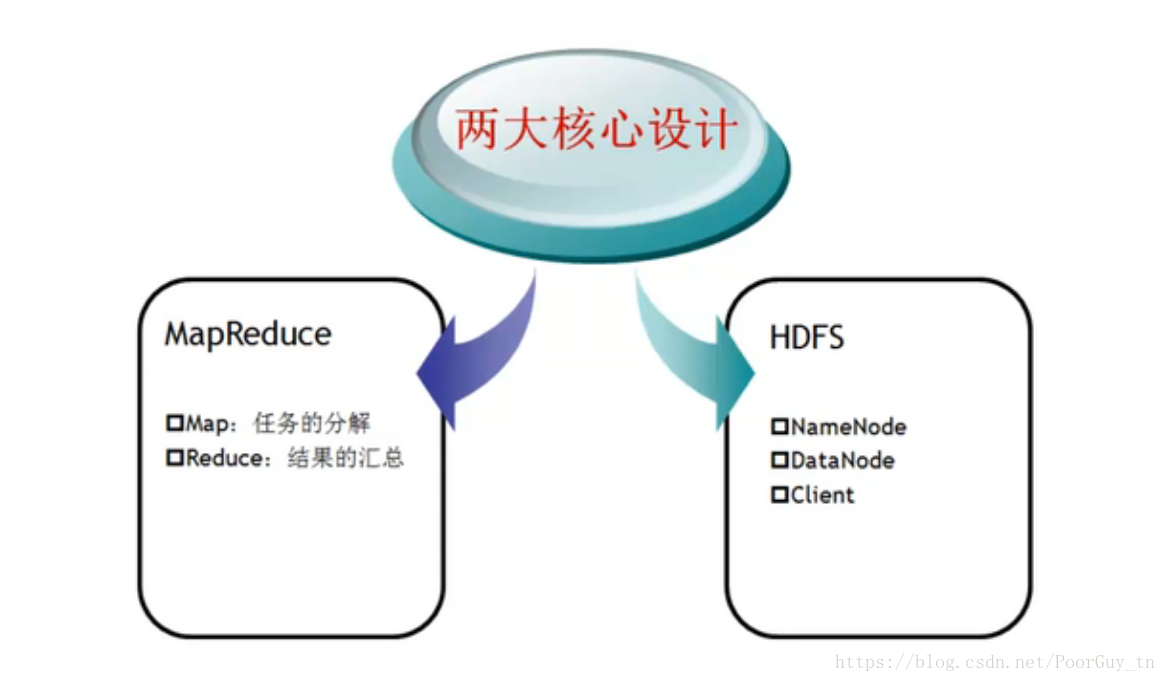
Hadoop–> 大数据 VS 传统数据
为什么要使用Hadoop处理大数据:
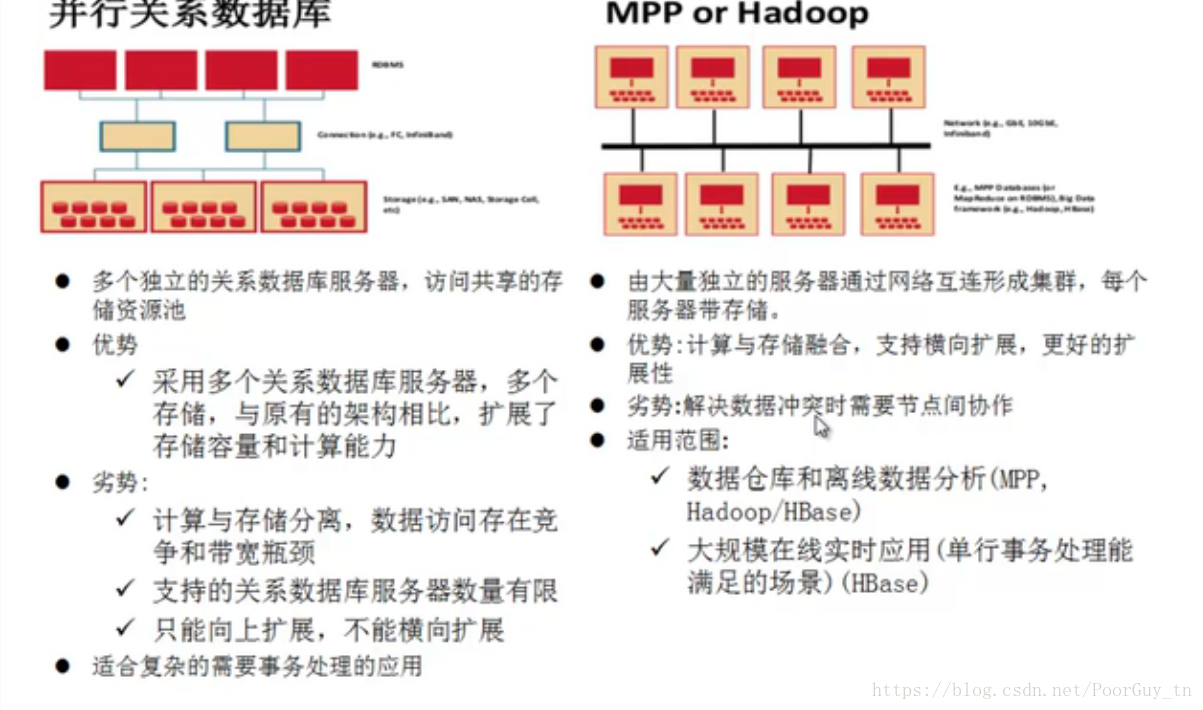
由于当今是数据的时代,数据量的极具增大,使得数据的储存查询成为了重要的问题:(1)首先对于传统数据库最多可以处理的是GB等级的数据,当数据量达到TB等级的时候,处理起来的速度和能力将会远远下降,并且数据的安全问题是很重要的,对于传统数据库,更多的是一台高性能服务器来存储,所以备份等,就会出现数据安全问题,并且由于要求单台数据库服务器的配置要高,所以相应的价格也将会非常大,相比同等价格的Hadoop集群,对数据的处理和储存能力将远不如Hadoop。
(2)Hadoop是分布式存储,使得数据的备份将会更加容易,也更加安全,维护起来的价格也相比较低。
下面是关系型数据库与Hadoop的比较图:
(3)什么是大数据呢?
“大数据”是指现有数据集大小超过了典型数据库软件和工具的处理能力,与此同时,及时捕获,储存,聚合,管理这些大数据已经数据的深入分析等。当今数据量的极具增大。(4)下面是大数据与传统数据的比较图:
附:当今国内数据量最大的公司是什么?
答案是:百度(百度需要将所有的数据爬回来储存起来,包括一些交互),而我们所熟悉的大公司,阿里华为储存的都是他们自己公司的数据注: 在数据存储的单位中最大的是PB,1PB = 1024TB,1TB = 1024G,1G = 1024M,1M = 1024Kb
当数据量超过PB时,只需要更改PB前面的数字即可那么Hadoop有哪些需要学的呢?功能是什么?
注:其中Pig公司已经很少使用了,不需要去学习了,下面的三个黑色字的,Flume,Mahout和Sqoop不属于Hadoop家族。
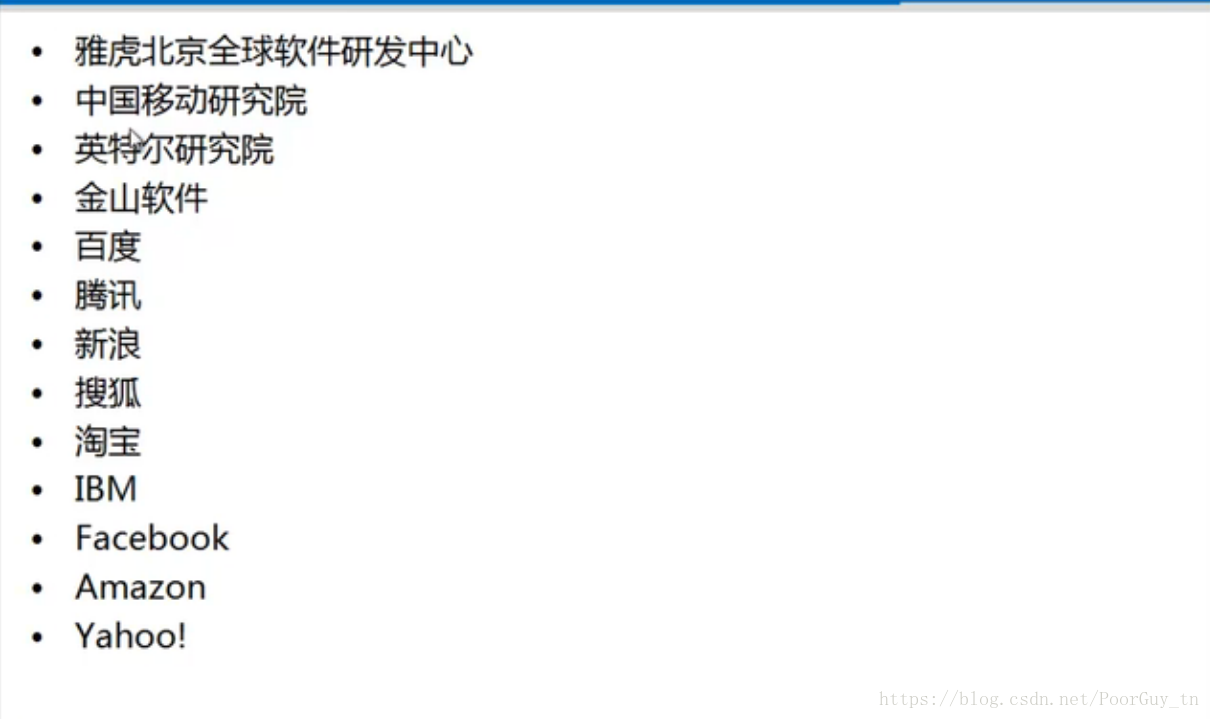
现在那些大公司在使用Hadoop呢?
注:上面的图片只是写了一点点,像华为,阿里等也都是使用Hadoop的


看到了这些相信大家已经开始想要学习Hadoop了把,将会更新更多Hadoop的知识,欢迎大家支持交流。
小白创作,大佬勿喷,谢谢合作