1、统计-尾部置信度检验
正态分布在统计尾部置信度检验等领域有着广泛的应用。在统计尾置信检验中,根据正态分布确定一组数据值的极值。正态分布的假设在实际领域中相当普遍。这不仅适用于表示为随机样本总和的变量(如前面部分所讨论的) ,而且适用于由不同随机过程产生的许多变量。具有平均 μ 和标准差 σ 的正态分布的密度函数 f x (x)定义如下:

在某些情况下,可以假设模型分布的平均 μ 和标准差 σ 是已知的。当有大量的数据样本可用于精确估计 μ 和 σ 时,就是这种情况。在其他情况下,μ 和 σ 可以从领域知识中获得。然后,观测值 x i 的 z 值 z i 可以计算如下:
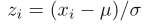
由于正态分布可以直接表示为 z 值的函数(没有其他参数) ,因此点 xi 的尾概率也可以表示为 z i 的函数。实际上,z 值对应于一个标度平移的正态随机变量,也就是平均值为0,方差为1的标准正态分布。因此,可以直接使用累积标准正态分布来确定尾概率在 z i 值处的精确值。从实际的角度来看,由于这种分布不是以封闭形式存在的,因此使用正态分布表来映射不同的 z i 值和概率。这提供了显著性的统计级别,可以直接解释为数据点是异常值的概率。基本的假设是,数据是由正态分布产生的。
1.1 t检验
前面提到的讨论假设模型分布的平均值和标准差可以从大量的样本中非常准确地估计出来。然而,在实践中,可用的数据集可能很小。例如,对于一个有20个数据点的样本,准确地建立均值和标准偏差的模型要困难得多。在这种情况下,我们如何准确地进行统计显著性检验?
Student 的 t- 分布提供了一种有效的方法来对这种情况下的异常进行建模。这种分布是由一个参数所定义的自由度数 ν,这是密切定义的现有样本规模。当自由度大于1000时,t 分布极好地逼近正态分布,当 t 分布趋于∞时,t 分布收敛于正态分布。对于较少的自由度(或样本容量) ,t 分布具有与正态分布相似的钟形曲线,但尾部较重。这是相当直观的,因为较重的尾部解释了由于无法从较少的样本精确估计模型(正态)分布的平均值和标准差而造成的统计显著性损失。
t分布表示为几个独立的同分布标准正态分布的函数。它有一个参数 ν,对应自由度数。这规定了这种正态分布的数量,以及它所表示的数量。参数 ν 设置为 n-1,其中 n 是有效样本的总数。设 u 0… u ν 为 ν + 1,具有零均值和单位标准差的独立同分布正态分布。这种正态分布也称为标准正态分布。然后,t 分布的定义如下:
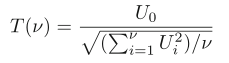
用少量样本 x 1… x n 进行极值检测的过程如下。首先,估计样本的平均值和标准差。然后使用平均值和标准差直接从样本计算每个数据点的 t 值。t 值的计算方法与 z 值的计算方法相同。根据(n-1)-自由度 t 分布的累积密度函数计算每个数据点的尾概率。同正常分布情况一样,为此目的也有标准化的表格。从实用的角度来看,如果有1000多个样本,那么 t 分布(至少有1000个自由度)是如此接近正态分布,因此可以使用正态分布作为一个非常好的近似。
1.2 用箱形图可视化极值
可视化单变量极值的一种有趣的方法是使用盒子图或盒子和触须图。这种方法在可视化离群值得分的情况下特别有用。在一个盒子图中,一个单变量分布的统计被归纳为五个量。这五个量分别是“最小/最大”(晶须)、上下四分位数(盒子)和中位数(盒子中间的线)。我们附上其中两个数量的报价,因为它们是以非标准的方式定义的。上下四分位数之间的距离称为四分位数间距(IQR)。“最小”和“最大”的定义在一个(非标准)修剪方式,以定义胡须的位置。如果在顶部四分位数值(盒子的上端)上没有超过1.5 IQR 的点,那么上面的晶须是真正的最大值。否则,上面的晶须设置为1.5倍的 IQR 从盒子的上端。一个完全类似的规则也适用于较低的晶须,从盒子的下端设置为1.5 IQR。在正态分布数据的特殊情况下,1.5 IQR 值大于顶部四分位数对应的距离是标准差的2.7倍。因此,晶须的位置大致与正态分布的3个 σ 截止点相似。
2、基于直方图的技术
直方图使用空间划分方法来进行基于密度的摘要。在单变量数据的最简单情况下,数据被离散到最小值和最大值之间等宽度的箱子中,并估计每个箱子的频率。位于非常低频率的箱子中的数据点被报告为异常值。在多变量数据的背景下,这种方法可以用两种不同的方式加以推广:
- 离群值分别计算每个维度的得分,然后可以聚合得分。
- 同时生成各维的离散化,构造网格结构。网格结构中点的分布可以用来建立稀疏区域的模型。这些稀疏区域中的数据点是离群值。
在某些情况下,直方图仅仅建立在点的样本上(出于效率的考虑) ,但是所有的点都是基于点所在的位置的频率得分的。设 f 1… f b 是 b 单变量或多变量箱的(原始)频率。这些频率代表这些箱子内点的离群值得分。较小的值更能显示出异常。在某些情况下,通过将数据点的频率计数(分数)减少1来调整它。这是因为在计数中包含数据点本身可能掩盖其在极值分析期间的透明性。如果使用数据样本构造直方图,但是使用构造直方图中相关单元的频率对样本外点进行评分,那么这种调整就特别重要。在这种情况下,只有样本内点的得分减少了1。因此,调整频率的 j 点(属于与频率 f i 的第三箱)的频率 f j 是由以下给出的:
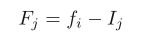
这里,i j ∈{0,1}是一个指示变量,取决于 jth 点是否是样本点。注意,fj 总是非负值,因为包含采样点的容器的频率总是至少为1。
值得注意的是,调整后频率 f j 的对数表示一个对数似然得分,这使得得分的极值分析能够更好地标记转换。为了正则化的目的,我们使用 log 2(f j + α)作为 jth 点的离群值得分,其中 α > 0是正则化参数。要将分数转换为二进制标签,可以使用 Student 的 t- 分布或正态分布通过极值分析确定异常低的分数。这些点被标记为离群值。直方图与聚类方法非常相似,因为它们总结数据的稠密和稀疏区域以计算离群值; 主要的区别是聚类方法划分数据点,而直方图方法倾向于将数据空间划分为大小相同的区域。
基于直方图的技术的主要挑战是通常很难确定最佳的直方图宽度。过宽或过窄的直方图不能按照最佳检测异常值所需的粒度级别建立频率分布模型。当这些箱子太窄时,落入这些箱子中的正常数据点将被标识为离群值。另一方面,当箱子太宽时,异常数据点可能落在高频箱中,因此不会被识别为异常值。在这种情况下,改变直方图的宽度并为同一个数据点获得多个得分是有意义的。这些(对数似然)分数然后在不同的基础检测器上取平均值得到最终结果。与聚类一样,基于直方图的方法由于参数选择的不同,在预测方面具有很高的可变性,这使得它们成为集成方法的理想候选者。例如,RS-Hash 方法改变网格区域的维数和大小,根据得分确定离群值。类似地,最近的一些集合方法,如isolation forests,可以看作是随机直方图,其中不同大小和形状的网格区域是以层次化和随机化的方式创建的。不是测量固定大小的网格区域中的点数,而是将隔离单个点所需的网格区域预期大小的间接测量作为离群值得分报告。这种方法可以避免预先选择固定网格大小的问题。
使用基于直方图的技术面临的第二个挑战是,它们的空间分割方法使它们对集群异常的存在视而不见。基于多元网格的方法可能无法将一组孤立的数据点分类为离群值,除非网格结构的分辨率被仔细校准。这是因为网格的密度只取决于其中的数据点,而且当表示的粒度很高时,一组孤立的点可能会创建一个人工密集的网格单元。这个问题也可以通过改变网格宽度和平均分数来部分解决。
由于网格结构的稀疏性和维数的增加,直方图方法在高维情况下不能很好地工作,除非离群值是根据精心选择的低维投影计算的。例如,一个 d 维空间将包含至少2的d次方网格单元,因此,预期填充每个单元的数据点数量随着维度的增加呈指数级减少。使用一些技术,如 rotated bagging和子空间直方图可以部分地解决这个问题。尽管基于直方图的技术有着巨大的潜力,但是为了得到最好的结果,它们应该与高维子空间集成结合使用。
3、HBOS
HBOS全名为:Histogram-based Outlier Score。它是⼀种单变量⽅法的组合,不能对特征之间的依赖关系进⾏建模,但是计算速度较快,对⼤数据集友好。其基本假设是数据集的每个维度相互独⽴。然后对每个维度进⾏区间(bin)划分,区间的密度越⾼,异常评分越低。
HBOS算法流程:
1.为每个数据维度做出数据直⽅图。对分类数据统计每个值的频数并计算相对频率。对数值数据根据分布的不同采⽤以下两种⽅法:
(1)静态宽度直⽅图:标准的直⽅图构建⽅法,在值范围内使⽤k个等宽箱。样本落⼊每个桶的频率(相对数量)作为密度(箱⼦⾼度)的估计。
时间复杂度:O(n)
(2)动态宽度直⽅图:⾸先对所有值进⾏排序,然后固定数量的N/k个连续值装进⼀个箱⾥,其 中N是总实例数,k是箱个数;直⽅图中的箱⾯积表⽰实例数。因为箱的宽度是由箱中第⼀个值和最后⼀个值决定的,所有箱的⾯积都⼀样,因此每⼀个箱的⾼度都是可计算的。这意味着跨度⼤的箱的⾼度低,即密度小,只有⼀种情况例外,超过N/k个数相等,此时允许在同⼀个箱⾥超过N/k个值。
时间复杂度:O(n×log(n))
2.对每个维度都计算了⼀个独⽴的直⽅图,其中每个箱⼦的⾼度表⽰密度的估计。然后为了使得最⼤⾼度为1(确保了每个特征与异常值得分的权重相等),对直⽅图进⾏归⼀化处理。最后,每⼀个实例的
HBOS值由以下公式计算:
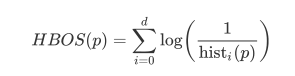
推导过程:

4、总结
1.异常检测的统计学⽅法由数据学习模型,以区别正常的数据对象和异常点。使⽤统计学⽅法的⼀个优点是,异常检测可以是统计上⽆可⾮议的。当然,仅当对数据所做的统计假定满⾜实际约束时才为真。
2.HBOS在全局异常检测问题上表现良好,但不能检测局部异常值。但是HBOS⽐标准算法快得多,尤其是在⼤数据集上。
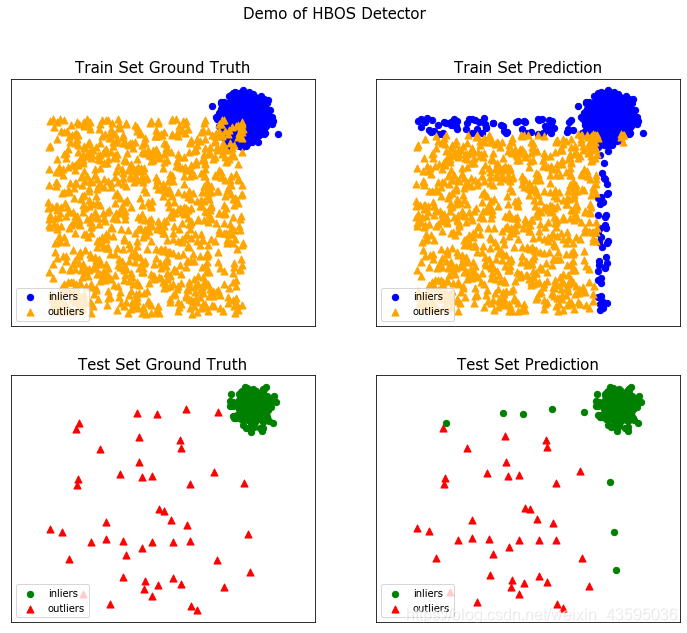
5、使⽤PyOD库⽣成toy example并调⽤HBOS
from pyod.models.hbos import HBOS
import numpy as np
import pandas as pd
import matplotlib as plt
from pyod.utils.data import generate_data, evaluate_print
from pyod.utils.example import visualize
‘基本参数’
contamination = 0.1
n_train = 10000
n_test = 500
‘生成toy example数据集’
X_train, y_train, X_test, y_test = generate_data(n_train=n_train, n_test=n_test, contamination=contamination)
clf_name = ‘HBOS’
clf = HBOS()
clf.fit(X_train)
‘获取X_train的score & label’
y_train_pred = clf.labels_
y_train_scores = clf.decision_scores_
‘获取X_test的scor & label’
y_test_pred = clf.predict(X_test)
y_test_scores = clf.decision_function(X_test)
‘输出结果’
print(“训练结果:”)
evaluate_print(clf_name, y_train, y_train_scores)
print(“测试结果:”)
evaluate_print(clf_name, y_test, y_test_scores)
训练结果:
HBOS ROC:0.9892, precision @ rank n:0.9752
测试结果:
HBOS ROC:0.9957, precision @ rank n:0.913
visualize(clf_name, X_train, y_train, X_test, y_test, y_train_pred, y_test_pred, show_figure=True, save_figure=False)