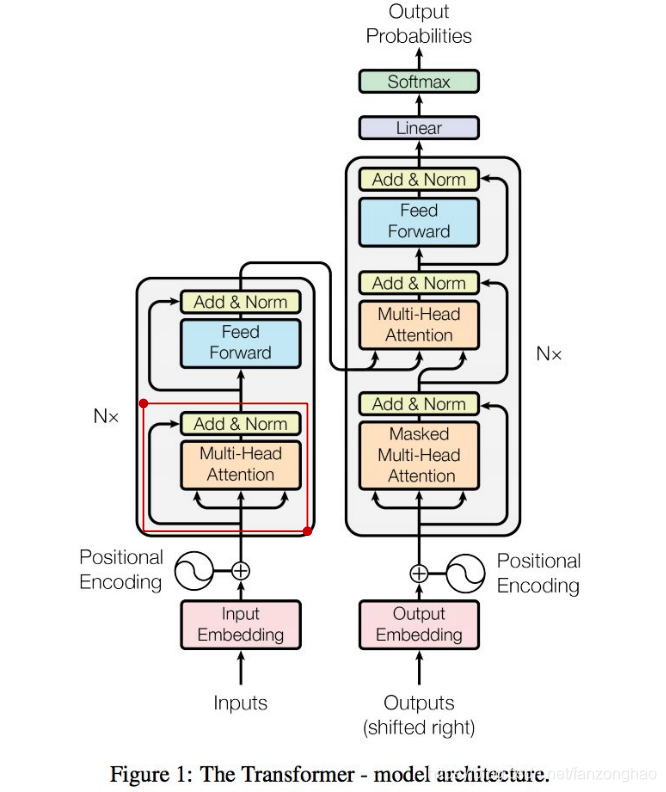
一.总体结构
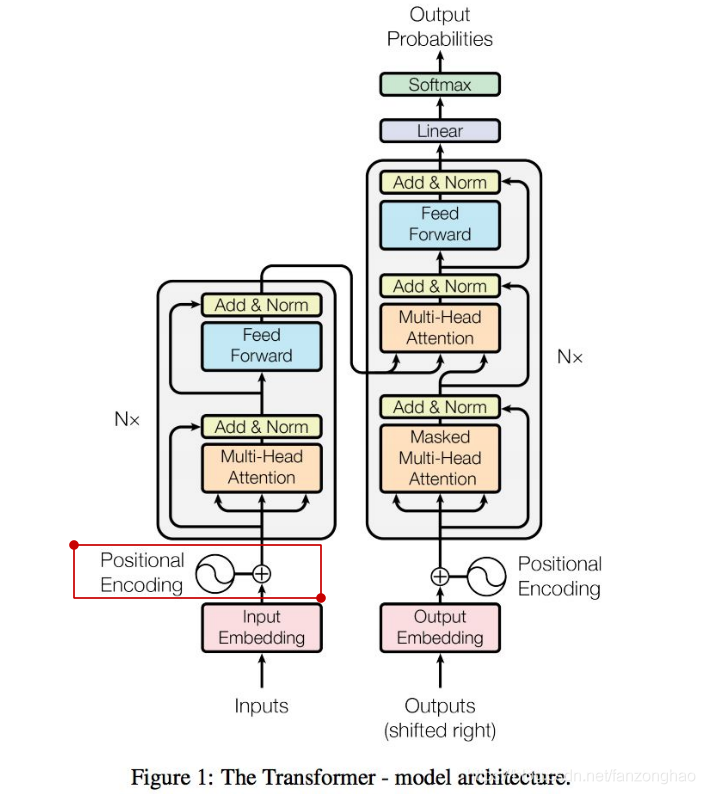
由于rnn等循环神经网络有时序依赖,导致无法并行计算,而Transformer主体框架是一个encoder-decoder结构,去掉了RNN序列结构,完全基于attention和全连接。同时为了弥补词与词之间时序信息,将词位置embedding成向量输入模型.
二.每一步拆分
1.padding mask
对于输入序列一般我们都要进行padding补齐,也就是说设定一个统一长度N,在较短的序列后面填充0到长度为N。对于那些补零的数据来说,我们的attention机制不应该把注意力放在这些位置上,所以我们需要进行一些处理。具体的做法是,把这些位置的值加上一个非常大的负数(负无穷),这样经过softmax后,这些位置的权重就会接近0。Transformer的padding mask实际上是一个张量,每个值都是一个Boolean,值为false的地方就是要进行处理的地方。
def padding_mask(seq_k, seq_q):
len_q = seq_q.size(1)
print('=len_q:', len_q)
# `PAD` is 0
pad_mask_ = seq_k.eq(0)#每句话的pad mask
print('==pad_mask_:', pad_mask_)
pad_mask = pad_mask_.unsqueeze(1).expand(-1, len_q, -1) # shape [B, L_q, L_k]#作用于attention的mask
print('==pad_mask', pad_mask)
return pad_mask
def debug_padding_mask():
Bs = 2
inputs_len = np.random.randint(1, 5, Bs).reshape(Bs, 1)
print('==inputs_len:', inputs_len)
vocab_size = 6000 # 词汇数
max_seq_len = int(max(inputs_len))
# vocab_size = int(max(inputs_len))
x = np.zeros((Bs, max_seq_len), dtype=np.int)
for s in range(Bs):
for j in range(inputs_len[s][0]):
x[s][j] = j + 1
x = torch.LongTensor(torch.from_numpy(x))
print('x.shape', x.shape)
mask = padding_mask(seq_k=x, seq_q=x)
print('==mask:', mask.shape)
if __name__ == '__main__':
debug_padding_mask()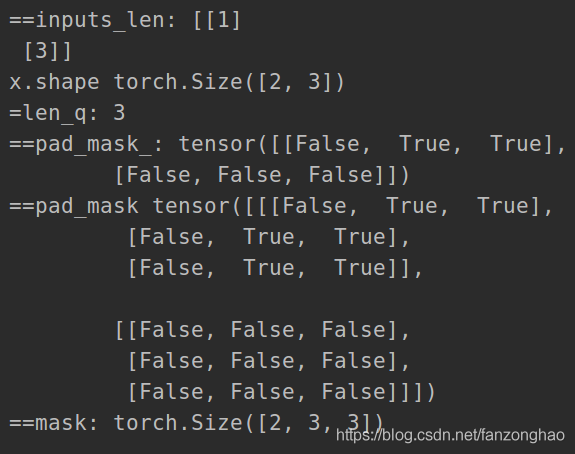
2.Position encoding
其也叫做Position embedding,由于Transformer模型没有使用RNN,故Position encoding(PE)的目的就是实现文本序列的顺序(或者说位置)信息而出现的。
代码实现如下:输入batch内的词位置,输出是batch内的每个词的位置embedding向量.
class PositionalEncoding(nn.Module):
def __init__(self, d_model, max_seq_len):
"""初始化
Args:
d_model: 一个标量。模型的维度,论文默认是512
max_seq_len: 一个标量。文本序列的最大长度
"""
super(PositionalEncoding, self).__init__()
# 根据论文给的公式,构造出PE矩阵
position_encoding = np.array([
[pos / np.power(10000, 2.0 * (j // 2) / d_model) for j in range(d_model)]
for pos in range(max_seq_len)]).astype(np.float32)
# 偶数列使用sin,奇数列使用cos
position_encoding[:, 0::2] = np.sin(position_encoding[:, 0::2])
position_encoding[:, 1::2] = np.cos(position_encoding[:, 1::2])
# 在PE矩阵的第一行,加上一行全是0的向量,代表这`PAD`的positional encoding
# 在word embedding中也经常会加上`UNK`,代表位置单词的word embedding,两者十分类似
# 那么为什么需要这个额外的PAD的编码呢?很简单,因为文本序列的长度不一,我们需要对齐,
# 短的序列我们使用0在结尾补全,我们也需要这些补全位置的编码,也就是`PAD`对应的位置编码
position_encoding = torch.from_numpy(position_encoding) # [max_seq_len, model_dim]
# print('==position_encoding.shape:', position_encoding.shape)
pad_row = torch.zeros([1, d_model])
position_encoding = torch.cat((pad_row, position_encoding)) # [max_seq_len+1, model_dim]
# print('==position_encoding.shape:', position_encoding.shape)
# 嵌入操作,+1是因为增加了`PAD`这个补全位置的编码,
# Word embedding中如果词典增加`UNK`,我们也需要+1。看吧,两者十分相似
self.position_encoding = nn.Embedding(max_seq_len + 1, d_model)
self.position_encoding.weight = nn.Parameter(position_encoding,
requires_grad=False)
def forward(self, input_len):
"""神经网络的前向传播。
Args:
input_len: 一个张量,形状为[BATCH_SIZE, 1]。每一个张量的值代表这一批文本序列中对应的长度。
Returns:
返回这一批序列的位置编码,进行了对齐。
"""
# 找出这一批序列的最大长度
max_len = torch.max(input_len)
tensor = torch.cuda.LongTensor if input_len.is_cuda else torch.LongTensor
# 对每一个序列的位置进行对齐,在原序列位置的后面补上0
# 这里range从1开始也是因为要避开PAD(0)的位置
input_pos = tensor(
[list(range(1, len + 1)) + [0] * (max_len - len) for len in input_len])
# print('==input_pos:', input_pos)#pad补齐
# print('==input_pos.shape:', input_pos.shape)#[bs, max_len]
return self.position_encoding(input_pos)
def debug_posion():
"""d_model:模型的维度"""
bs = 16
x_sclar = np.random.randint(1, 30, bs).reshape(bs, 1)
model = PositionalEncoding(d_model=512, max_seq_len=int(max(x_sclar)))
x = torch.from_numpy(x_sclar)#[bs, 1]
print('===x:', x)
print('====x.shape', x.shape)
out = model(x)
print('==out.shape:', out.shape)#[bs, max_seq_len, model_dim]
if __name__ == '__main__':
debug_posion()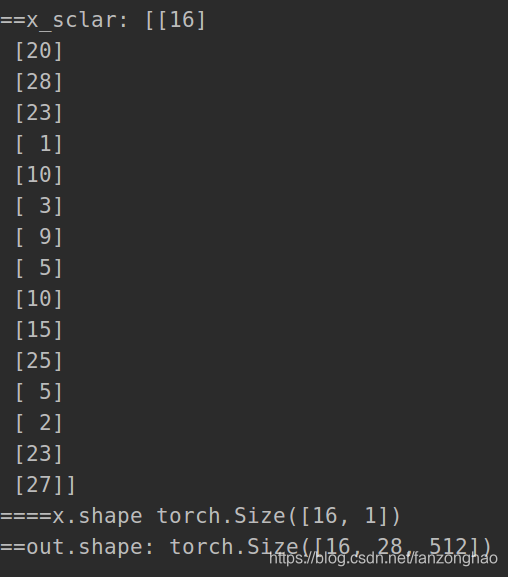
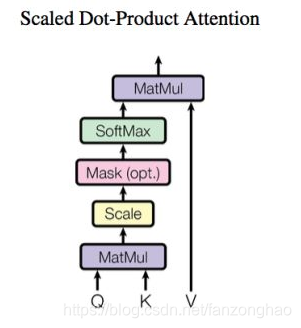
3.Scaled dot-product attention实现
Q,K,V:可看成一个batch内词的三个embedding向量和矩阵相乘得到的,而这个矩阵就是需要学习的,通过Q,K获取attention score作用于V上获取加权的V.这样一句话的不同词就获取了不同关注度.注意,Q,K,V这 3 个向量一般比原来的词向量的长度更小。假设这 3 个向量的长度是64 ,而原始的词向量或者最终输出的向量的长度是 512(Q,K,V这 3 个向量的长度,和最终输出的向量长度,是有倍数关系的)
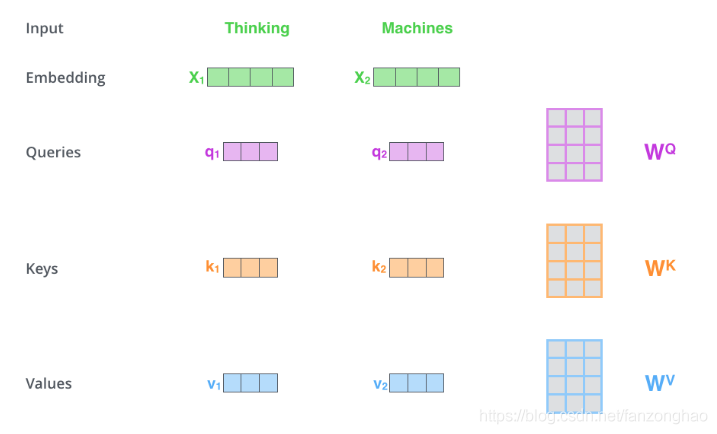
上图中,有两个词向量:Thinking 的词向量 x1 和 Machines 的词向量 x2。以 x1 为例,X1 乘以 WQ 得到 q1,q1 就是 X1 对应的 Query 向量。同理,X1 乘以 WK 得到 k1,k1 是 X1 对应的 Key 向量;X1 乘以 WV 得到 v1,v1 是 X1 对应的 Value 向量。
![]()
对应代码实现:
class ScaledDotProductAttention(nn.Module):
"""Scaled dot-product attention mechanism."""
def __init__(self, attention_dropout=0.5):
super(ScaledDotProductAttention, self).__init__()
self.dropout = nn.Dropout(attention_dropout)
self.softmax = nn.Softmax(dim=2)
def forward(self, q, k, v, scale=None, attn_mask=None):
"""前向传播.
Args:
q: Queries张量,形状为[B, L_q, D_q]
k: Keys张量,形状为[B, L_k, D_k]
v: Values张量,形状为[B, L_v, D_v],一般来说就是k
scale: 缩放因子,一个浮点标量
attn_mask: Masking张量,形状为[B, L_q, L_k]
Returns:
上下文张量和attetention张量
"""
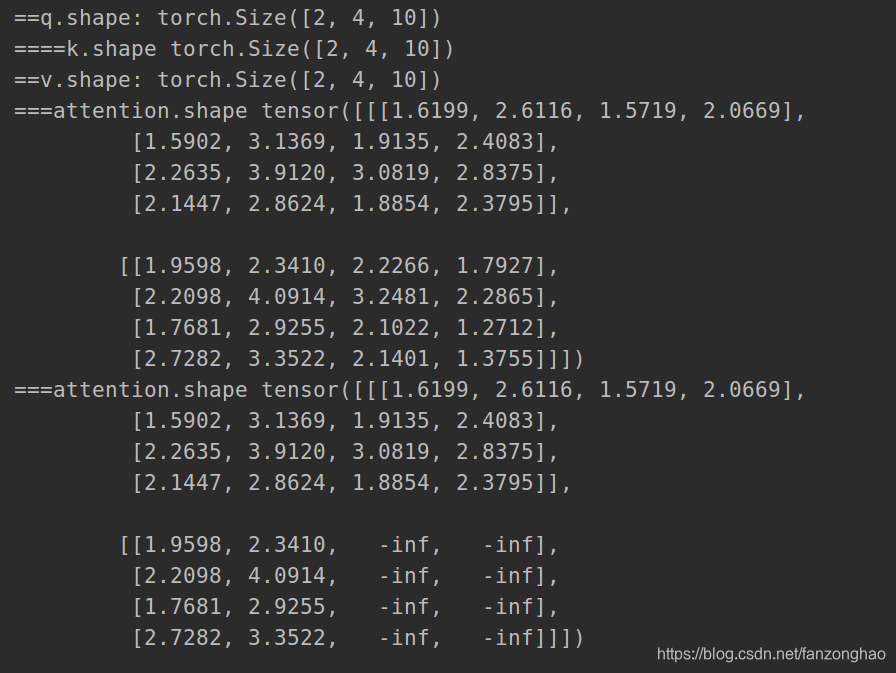
attention = torch.bmm(q, k.transpose(1, 2)) # [B, sequence, sequence]
print('===attention.shape', attention)
if scale:
attention = attention * scale
if attn_mask is not None:
# 给需要mask的地方设置一个负无穷
attention = attention.masked_fill_(attn_mask, -np.inf)
print('===attention.shape', attention)
attention = self.softmax(attention) # [B, sequence, sequence]
# print('===attention.shape', attention.shape)
attention = self.dropout(attention) # [B, sequence, sequence]
# print('===attention.shape', attention.shape)
context = torch.bmm(attention, v) # [B, sequence, dim]
return context, attention
def debug_scale_attention():
model = ScaledDotProductAttention()
# B, L_q, D_q = 32, 100, 128
B, L_q, D_q = 2, 4, 10
pading_mask = torch.tensor([[[False, False, False, False],
[False, False, False, False],
[False, False, False, False],
[False, False, False, False]],
[[False, False, True, True],
[False, False, True, True],
[False, False, True, True],
[False, False, True, True]]])
q, k, v = torch.rand(B, L_q, D_q), torch.rand(B, L_q, D_q), torch.rand(B, L_q, D_q)
print('==q.shape:', q.shape)
print('====k.shape', k.shape)
print('==v.shape:', v.shape)
out = model(q, k, v, attn_mask=pading_mask)
if __name__ == '__main__':
debug_scale_attention()
4.Multi-Head Attention
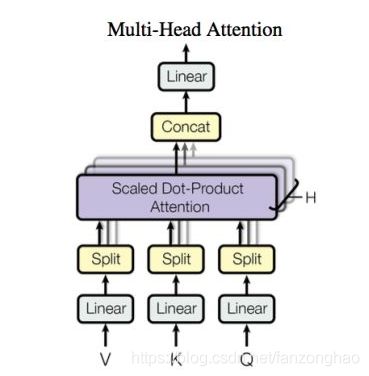
其中H就是Multi-Head,可看出首先对Q,K,V进行一次线性变换,然后进行切分,对每一个切分的部分进行attention(Scaled dot-product attention),然后最后将结果进行合并.有一种类似通道加权的感觉.
对应代码实现:
class MultiHeadAttention(nn.Module):
def __init__(self, model_dim=512, num_heads=8, dropout=0.0):
"""model_dim:词向量维度
num_heads:头个数
"""
super(MultiHeadAttention, self).__init__()
self.dim_per_head = model_dim // num_heads#split个数也就是每个head要处理维度
self.num_heads = num_heads
self.linear_k = nn.Linear(model_dim, self.dim_per_head * num_heads)
self.linear_v = nn.Linear(model_dim, self.dim_per_head * num_heads)
self.linear_q = nn.Linear(model_dim, self.dim_per_head * num_heads)
self.dot_product_attention = ScaledDotProductAttention(dropout)
self.linear_final = nn.Linear(model_dim, model_dim)
self.dropout = nn.Dropout(dropout)
self.layer_norm = nn.LayerNorm(model_dim)
def forward(self, key, value, query, attn_mask=None):
residual = query# [B, sequence, model_dim]
dim_per_head = self.dim_per_head
num_heads = self.num_heads
batch_size = key.size(0)
# linear projection
key = self.linear_k(key)# [B, sequence, model_dim]
value = self.linear_v(value)# [B, sequence, model_dim]
query = self.linear_q(query)# [B, sequence, model_dim]
# print('===key.shape:', key.shape)
# print('===value.shape:', value.shape)
# print('==query.shape:', query.shape)
# split by heads
key = key.view(batch_size * num_heads, -1, dim_per_head)# [B* num_heads, sequence, model_dim//*num_heads]
value = value.view(batch_size * num_heads, -1, dim_per_head)# [B* num_heads, sequence, model_dim//*num_heads]
query = query.view(batch_size * num_heads, -1, dim_per_head)# [B* num_heads, sequence, model_dim//*num_heads]
# print('===key.shape:', key.shape)
# print('===value.shape:', value.shape)
# print('==query.shape:', query.shape)
if attn_mask:
attn_mask = attn_mask.repeat(num_heads, 1, 1)
# scaled dot product attention
scale = (key.size(-1) // num_heads) ** -0.5
context, attention = self.dot_product_attention(
query, key, value, scale, attn_mask)
# print('===context.shape', context.shape)# [B* num_heads, sequence, model_dim//*num_heads]
# print('===attention.shape', attention.shape)# [B* num_heads, sequence, sequence]
# concat heads
context = context.view(batch_size, -1, dim_per_head * num_heads)# [B, sequence, model_dim]
# print('===context.shape', context.shape)
# final linear projection
output = self.linear_final(context)# [B, sequence, model_dim]
# print('===context.shape', context.shape)
# dropout
output = self.dropout(output)
# add residual and norm layer
output = self.layer_norm(residual + output)# [B, sequence, model_dim]
# print('==output.shape:', output.shape)
return output, attention
def debug_mutil_head_attention():
model = MultiHeadAttention()
B, L_q, D_q = 32, 100, 512
q, k, v = torch.rand(B, L_q, D_q), torch.rand(B, L_q, D_q), torch.rand(B, L_q, D_q)
# print('==q.shape:', q.shape)# [B, sequence, model_dim]
# print('====k.shape', k.shape)# [B, sequence, model_dim]
# print('==v.shape:', v.shape)# [B, sequence, model_dim]
out, _ = model(q, k, v)# [B, sequence, model_dim]
print('==out.shape:', out.shape)
if __name__ == '__main__':
debug_mutil_head_attention()5.Positional-wise feed forward network(前馈神经网络层)
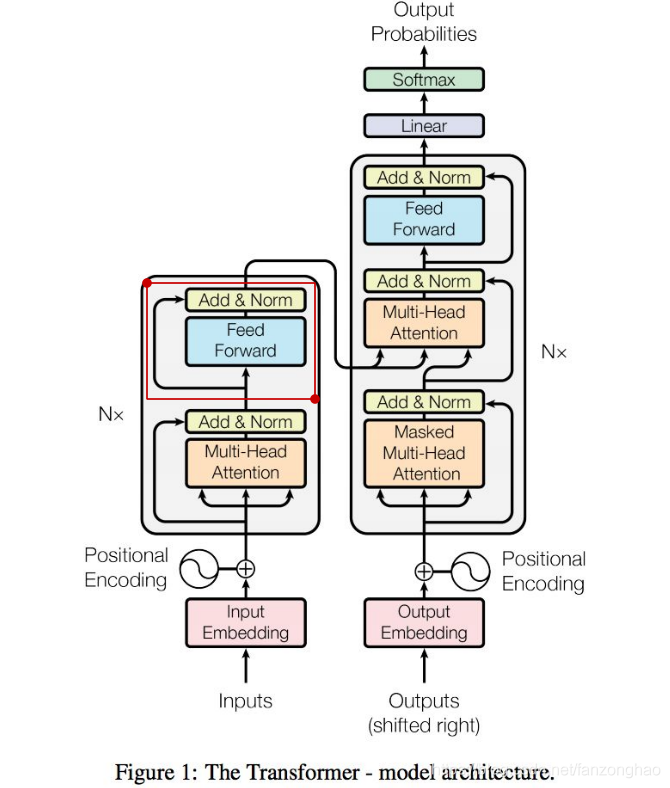
如上图中画框就是其所在,
代码:
#Position-wise Feed Forward Networks
class PositionalWiseFeedForward(nn.Module):
def __init__(self, model_dim=512, ffn_dim=2048, dropout=0.0):
"""model_dim:词向量的维度
ffn_dim:卷积输出的维度
"""
super(PositionalWiseFeedForward, self).__init__()
self.w1 = nn.Conv1d(model_dim, ffn_dim, 1)
self.w2 = nn.Conv1d(ffn_dim, model_dim, 1)
self.dropout = nn.Dropout(dropout)
self.layer_norm = nn.LayerNorm(model_dim)
def forward(self, x):#[B, sequence, model_dim]
output = x.transpose(1, 2)#[B, model_dim, sequence]
# print('===output.shape:', output.shape)
output = self.w2(F.relu(self.w1(output)))#[B, model_dim, sequence]
output = self.dropout(output.transpose(1, 2))#[B, sequence, model_dim]
# add residual and norm layer
output = self.layer_norm(x + output)
return output
def debug_PositionalWiseFeedForward():
B, L_q, D_q = 32, 100, 512
x = torch.rand(B, L_q, D_q)
model = PositionalWiseFeedForward()
out = model(x)
print('==out.shape:', out.shape)
if __name__ == '__main__':
debug_PositionalWiseFeedForward()6.encoder实现
其共有6层4,5的结构,可看出q k v 均来自同一文本.
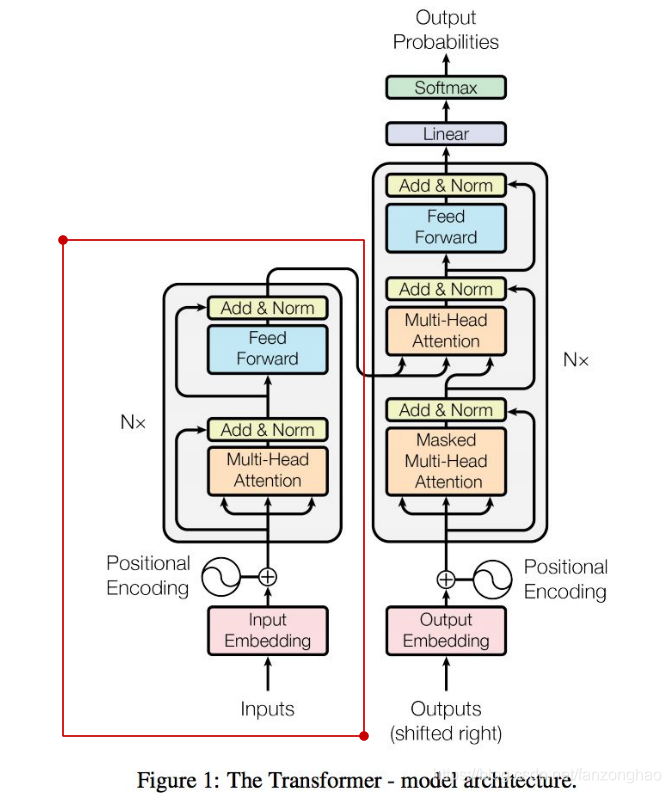
def sequence_mask(seq):
batch_size, seq_len = seq.size()
mask = torch.triu(torch.ones((seq_len, seq_len), dtype=torch.uint8),
diagonal=1)
mask = mask.unsqueeze(0).expand(batch_size, -1, -1) # [B, L, L]
return mask
def padding_mask(seq_k, seq_q):
len_q = seq_q.size(1)
# `PAD` is 0
pad_mask = seq_k.eq(0)
pad_mask = pad_mask.unsqueeze(1).expand(-1, len_q, -1) # shape [B, L_q, L_k]
return pad_mask
class EncoderLayer(nn.Module):
"""一个encode的layer实现"""
def __init__(self, model_dim=512, num_heads=8, ffn_dim=2018, dropout=0.0):
super(EncoderLayer, self).__init__()
self.attention = MultiHeadAttention(model_dim, num_heads, dropout)
self.feed_forward = PositionalWiseFeedForward(model_dim, ffn_dim, dropout)
def forward(self, inputs, attn_mask=None):
# self attention
# [B, sequence, model_dim] [B* num_heads, sequence, sequence]
context, attention = self.attention(inputs, inputs, inputs, attn_mask)
# feed forward network
output = self.feed_forward(context) # [B, sequence, model_dim]
return output, attention
class Encoder(nn.Module):
"""编码器实现 总共6层"""
def __init__(self,
vocab_size,
max_seq_len,
num_layers=6,
model_dim=512,
num_heads=8,
ffn_dim=2048,
dropout=0.0):
super(Encoder, self).__init__()
self.encoder_layers = nn.ModuleList(
[EncoderLayer(model_dim, num_heads, ffn_dim, dropout) for _ in range(num_layers)])
self.seq_embedding = nn.Embedding(vocab_size + 1, model_dim, padding_idx=0)
self.pos_embedding = PositionalEncoding(model_dim, max_seq_len)
# [bs, max_seq_len] [bs, 1]
def forward(self, inputs, inputs_len):
output = self.seq_embedding(inputs) # [bs, max_seq_len, model_dim]
print('========output.shape', output.shape)
# 加入位置信息embedding
output += self.pos_embedding(inputs_len) # [bs, max_seq_len, model_dim]
print('========output.shape', output.shape)
self_attention_mask = padding_mask(inputs, inputs)
attentions = []
for encoder in self.encoder_layers:
output, attention = encoder(output, attn_mask=None)
# output, attention = encoder(output, self_attention_mask)
attentions.append(attention)
return output, attentions
def debug_encoder():
Bs = 16
inputs_len = np.random.randint(1, 30, Bs).reshape(Bs, 1)
# print('==inputs_len:', inputs_len) # 模拟获取每个词的长度
vocab_size = 6000 # 词汇数
max_seq_len = int(max(inputs_len))
# vocab_size = int(max(inputs_len))
x = np.zeros((Bs, max_seq_len), dtype=np.int)
for s in range(Bs):
for j in range(inputs_len[s][0]):
x[s][j] = j+1
x = torch.LongTensor(torch.from_numpy(x))
inputs_len = torch.from_numpy(inputs_len)#[Bs, 1]
model = Encoder(vocab_size=vocab_size, max_seq_len=max_seq_len)
# x = torch.LongTensor([list(range(1, max_seq_len + 1)) for _ in range(Bs)])#模拟每个单词
print('==x.shape:', x.shape)
print(x)
model(x, inputs_len=inputs_len)
if __name__ == '__main__':
debug_encoder()

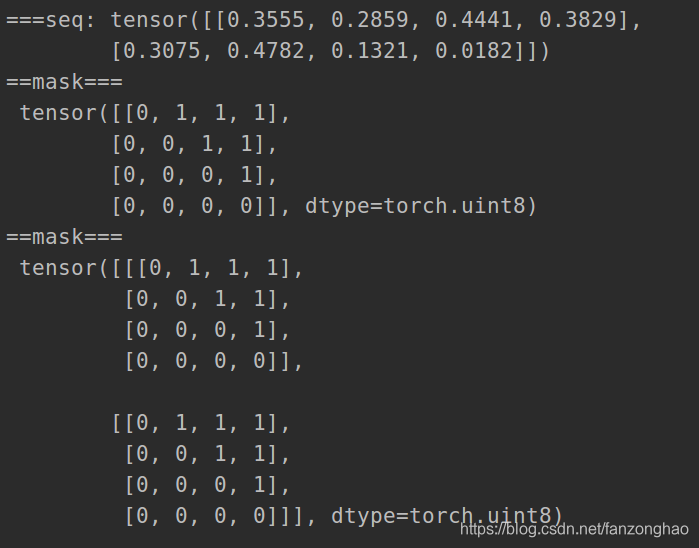
样本:“我/爱/机器/学习”和 "i/ love /machine/ learning"
训练:
7.1. 把“我/爱/机器/学习”embedding后输入到encoder里去,最后一层的encoder最终输出的outputs [10, 512](假设我们采用的embedding长度为512,而且batch size = 1),此outputs 乘以新的参数矩阵,可以作为decoder里每一层用到的K和V;
7.2. 将<bos>作为decoder的初始输入,将decoder的最大概率输出词 A1和‘i’做cross entropy计算error。
7.3. 将<bos>,"i" 作为decoder的输入,将decoder的最大概率输出词 A2 和‘love’做cross entropy计算error。
7.4. 将<bos>,"i","love" 作为decoder的输入,将decoder的最大概率输出词A3和'machine' 做cross entropy计算error。
7.5. 将<bos>,"i","love ","machine" 作为decoder的输入,将decoder最大概率输出词A4和‘learning’做cross entropy计算error。
7.6. 将<bos>,"i","love ","machine","learning" 作为decoder的输入,将decoder最大概率输出词A5和终止符</s>做cross entropy计算error。
可看出上述训练过程是挨个单词串行进行的,故引入sequence mask,用于并行训练.
 作用
作用 生成
生成
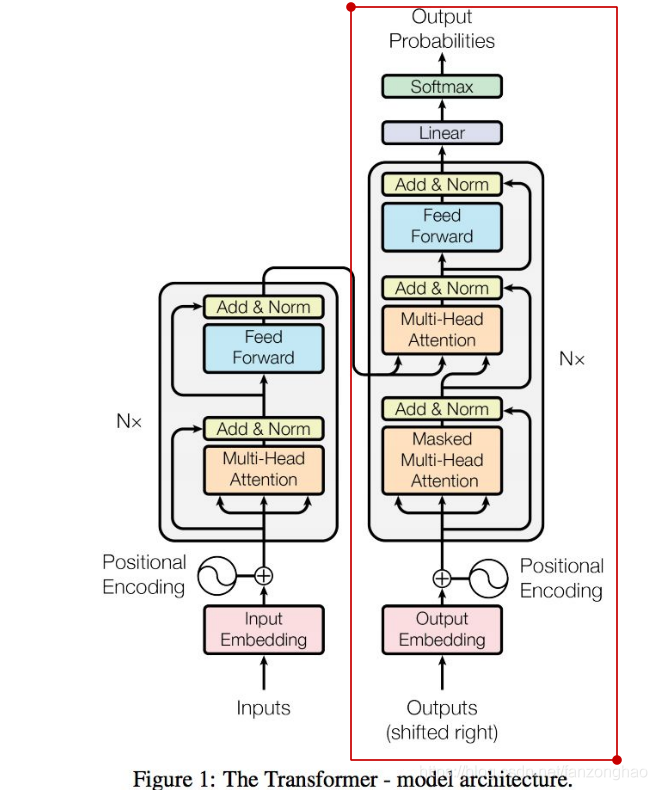
8.decoder实现
也是循环6层,可以看出decoder的soft-attention,q来自于decoder,k和v来自于encoder。它体现的是encoder对decoder的加权贡献。
class DecoderLayer(nn.Module):
"""解码器的layer实现"""
def __init__(self, model_dim, num_heads=8, ffn_dim=2048, dropout=0.0):
super(DecoderLayer, self).__init__()
self.attention = MultiHeadAttention(model_dim, num_heads, dropout)
self.feed_forward = PositionalWiseFeedForward(model_dim, ffn_dim, dropout)
# [B, sequence, model_dim] [B, sequence, model_dim]
def forward(self,
dec_inputs,
enc_outputs,
self_attn_mask=None,
context_attn_mask=None):
# self attention, all inputs are decoder inputs
# [B, sequence, model_dim] [B* num_heads, sequence, sequence]
dec_output, self_attention = self.attention(
key=dec_inputs, value=dec_inputs, query=dec_inputs, attn_mask=self_attn_mask)
# context attention
# query is decoder's outputs, key and value are encoder's inputs
# [B, sequence, model_dim] [B* num_heads, sequence, sequence]
dec_output, context_attention = self.attention(
key=enc_outputs, value=enc_outputs, query=dec_output, attn_mask=context_attn_mask)
# decoder's output, or context
dec_output = self.feed_forward(dec_output) # [B, sequence, model_dim]
return dec_output, self_attention, context_attention
class Decoder(nn.Module):
"""解码器"""
def __init__(self,
vocab_size,
max_seq_len,
num_layers=6,
model_dim=512,
num_heads=8,
ffn_dim=2048,
dropout=0.0):
super(Decoder, self).__init__()
self.num_layers = num_layers
self.decoder_layers = nn.ModuleList(
[DecoderLayer(model_dim, num_heads, ffn_dim, dropout) for _ in
range(num_layers)])
self.seq_embedding = nn.Embedding(vocab_size + 1, model_dim, padding_idx=0)
self.pos_embedding = PositionalEncoding(model_dim, max_seq_len)
def forward(self, inputs, inputs_len, enc_output, context_attn_mask=None):
output = self.seq_embedding(inputs)
output += self.pos_embedding(inputs_len)
print('==output.shape:', output.shape)
self_attention_padding_mask = padding_mask(inputs, inputs)
seq_mask = sequence_mask(inputs)
self_attn_mask = torch.gt((self_attention_padding_mask + seq_mask), 0)
self_attentions = []
context_attentions = []
for decoder in self.decoder_layers:
# [B, sequence, model_dim] [B* num_heads, sequence, sequence] [B* num_heads, sequence, sequence]
output, self_attn, context_attn = decoder(
output, enc_output, self_attn_mask=None, context_attn_mask=None)
self_attentions.append(self_attn)
context_attentions.append(context_attn)
return output, self_attentions, context_attentions
def debug_decoder():
Bs = 2
model_dim = 512
vocab_size = 6000 #词汇数
inputs_len = np.random.randint(1, 5, Bs).reshape(Bs, 1)#batch里每句话的单词个数
inputs_len = torch.from_numpy(inputs_len) # [Bs, 1]
max_seq_len = int(max(inputs_len))
x = np.zeros((Bs, max_seq_len), dtype=np.int)
for s in range(Bs):
for j in range(inputs_len[s][0]):
x[s][j] = j + 1
x = torch.LongTensor(torch.from_numpy(x))#模拟每个单词
# x = torch.LongTensor([list(range(1, max_seq_len + 1)) for _ in range(Bs)])
print('==x:', x)
print('==x.shape:', x.shape)
model = Decoder(vocab_size=vocab_size, max_seq_len=max_seq_len, model_dim=model_dim)
enc_output = torch.rand(Bs, max_seq_len, model_dim) #[B, sequence, model_dim]
print('==enc_output.shape:', enc_output.shape)
out, self_attentions, context_attentions = model(inputs=x, inputs_len=inputs_len, enc_output=enc_output)
print('==out.shape:', out.shape)#[B, sequence, model_dim]
print('==len(self_attentions):', len(self_attentions), self_attentions[0].shape)
print('==len(context_attentions):', len(context_attentions), context_attentions[0].shape)
if __name__ == '__main__':
debug_decoder()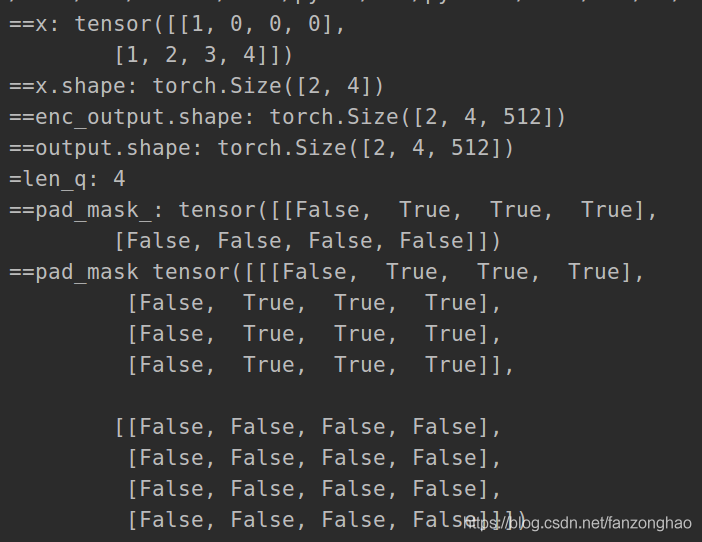

9.transformer
将encoder和decoder组合起来即可.
class Transformer(nn.Module):
def __init__(self,
src_vocab_size,
src_max_len,
tgt_vocab_size,
tgt_max_len,
num_layers=6,
model_dim=512,
num_heads=8,
ffn_dim=2048,
dropout=0.2):
super(Transformer, self).__init__()
self.encoder = Encoder(src_vocab_size, src_max_len, num_layers, model_dim,
num_heads, ffn_dim, dropout)
self.decoder = Decoder(tgt_vocab_size, tgt_max_len, num_layers, model_dim,
num_heads, ffn_dim, dropout)
self.linear = nn.Linear(model_dim, tgt_vocab_size, bias=False)
self.softmax = nn.Softmax(dim=2)
def forward(self, src_seq, src_len, tgt_seq, tgt_len):
context_attn_mask = padding_mask(tgt_seq, src_seq)
print('==context_attn_mask.shape', context_attn_mask.shape)
output, enc_self_attn = self.encoder(src_seq, src_len)
output, dec_self_attn, ctx_attn = self.decoder(
tgt_seq, tgt_len, output, context_attn_mask)
output = self.linear(output)
output = self.softmax(output)
return output, enc_self_attn, dec_self_attn, ctx_attn
def debug_transoform():
Bs = 4
#需要翻译的
encode_inputs_len = np.random.randint(1, 10, Bs).reshape(Bs, 1)
src_vocab_size = 6000 # 词汇数
encode_max_seq_len = int(max(encode_inputs_len))
encode_x = np.zeros((Bs, encode_max_seq_len), dtype=np.int)
for s in range(Bs):
for j in range(encode_inputs_len[s][0]):
encode_x[s][j] = j + 1
encode_x = torch.LongTensor(torch.from_numpy(encode_x))
#翻译的结果
decode_inputs_len = np.random.randint(1, 10, Bs).reshape(Bs, 1)
target_vocab_size = 5000 # 词汇数
decode_max_seq_len = int(max(decode_inputs_len))
decode_x = np.zeros((Bs, decode_max_seq_len), dtype=np.int)
for s in range(Bs):
for j in range(decode_inputs_len[s][0]):
decode_x[s][j] = j + 1
decode_x = torch.LongTensor(torch.from_numpy(decode_x))
encode_inputs_len = torch.from_numpy(encode_inputs_len) # [Bs, 1]
decode_inputs_len = torch.from_numpy(decode_inputs_len) # [Bs, 1]
model = Transformer(src_vocab_size=src_vocab_size, src_max_len=encode_max_seq_len, tgt_vocab_size=target_vocab_size, tgt_max_len=decode_max_seq_len)
# x = torch.LongTensor([list(range(1, max_seq_len + 1)) for _ in range(Bs)])#模拟每个单词
print('==encode_x.shape:', encode_x.shape)
print('==decode_x.shape:', decode_x.shape)
model(encode_x, encode_inputs_len, decode_x, decode_inputs_len)
if __name__ == '__main__':
debug_transoform()10.总结
(1):相比lstm而言,其能够实现并行,而lstm由于依赖上一时刻只能串行输出;
(2):利用self-attention将每个词之间距离缩短为1,大大缓解了长距离依赖问题,所以网络相比lstm能够堆叠得更深;
(3):Transformer可以同时融合前后位置的信息,而双向LSTM只是简单的将两个方向的结果相加,严格来说仍然是单向的;
(4):完全基于attention的Transformer,可以表达字与字之间的相关关系,可解释性更强;
(5):Transformer位置信息只能依靠position encoding,故当语句较短时效果不一定比lstm好;
(6):attention计算量为O(n^2), n为文本长度,计算量较大;
(7):相比CNN能够捕获全局的信息,而不是局部信息,所以CNN缺乏对数据的整体把握。
三.CV中的self-attention
介绍完了nlp的self-attention,现在介绍CV中的,如下图所示。
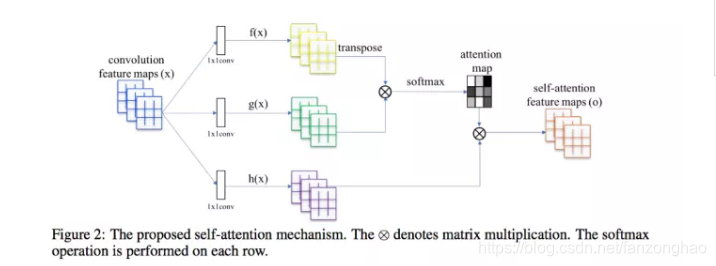
1.feature map通过1*1卷积获得,q,k,v三个向量,q与v转置相乘得到attention矩阵,进行softmax归一化到0到1,在作用于V,得到每个像素的加权.
![]()
2.softmax
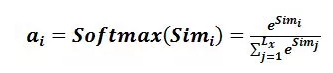
3,加权求和
![]()
import torch
import torch.nn as nn
import torch.nn.functional as F
class Self_Attn(nn.Module):
""" Self attention Layer"""
def __init__(self, in_dim):
super(Self_Attn, self).__init__()
self.chanel_in = in_dim
self.query_conv = nn.Conv2d(in_channels=in_dim, out_channels=in_dim // 8, kernel_size=1)
self.key_conv = nn.Conv2d(in_channels=in_dim, out_channels=in_dim // 8, kernel_size=1)
self.value_conv = nn.Conv2d(in_channels=in_dim, out_channels=in_dim, kernel_size=1)
self.gamma = nn.Parameter(torch.zeros(1))
self.softmax = nn.Softmax(dim=-1)
def forward(self, x):
"""
inputs :
x : input feature maps( B * C * W * H)
returns :
out : self attention value + input feature
attention: B * N * N (N is Width*Height)
"""
m_batchsize, C, width, height = x.size()
proj_query = self.query_conv(x).view(m_batchsize, -1, width * height).permute(0, 2, 1) # B*N*C
proj_key = self.key_conv(x).view(m_batchsize, -1, width * height) # B*C*N
energy = torch.bmm(proj_query, proj_key) # batch的matmul B*N*N
attention = self.softmax(energy) # B * (N) * (N)
proj_value = self.value_conv(x).view(m_batchsize, -1, width * height) # B * C * N
out = torch.bmm(proj_value, attention.permute(0, 2, 1)) # B*C*N
out = out.view(m_batchsize, C, width, height) # B*C*H*W
out = self.gamma * out + x
return out, attention
def debug_attention():
attention_module = Self_Attn(in_dim=128)
#B,C,H,W
x = torch.rand((2, 128, 100, 100))
attention_module(x)
if __name__ == '__main__':
debug_attention()参考:
https://zhuanlan.zhihu.com/p/166608727
https://jalammar.github.io/illustrated-transformer/
https://github.com/luozhouyang/machine-learning-notes/blob/master/transformer_pytorch.ipynb