大家:
好!Flume和SparkStream结合的两种方式--push
简单的介绍下: 就是flume把数据推送到SparkStream中。
----sparkstreaming的代码如下所示:
package SparkStream
import org.apache.spark.streaming.flume.FlumeUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.{SparkConf, SparkContext}
/**
* Created by Administrator on 2017/10/10.
* 功能:演示flume和sparkstreaming的结合 push的形式
*
*/
object FlumePushDemon {
def main(args: Array[String]): Unit = {
//设置日志的级别
LoggerLevels.setStreamingLogLevels()
val conf=new SparkConf().setAppName("FlumePushDemon").setMaster("local[2]")
val sc=new SparkContext(conf)
val ssc=new StreamingContext(sc,Seconds(5))
//以推送的方式: flume向ss发送数据(用flume给我们提供的工具)
// 192.168.17.10 是本地的虚拟机的地址 运行sparkstreaming,并接收flume的推送
val flumeStream=FlumeUtils.createStream(ssc,"192.168.17.10",8888)
//flume中的数据通过event.getBody才能拿到真正的内容(ip地址只能有一个)
val words=flumeStream.flatMap(x=>new String(x.event.getBody.array()).split(" ").map((_,1)))
val result=words.reduceByKey(_+_)
result.print()
//启动
ssc.start()
// 等待结束
ssc.awaitTermination()
}
}第一步: 本地运行ss程序
首先在本地的idea中运行sparkstream程序,正常运行程序之后,截图如下所示:
这张图的意思是, ss已经启动起来了,正在等待flume的输入
-----flume-push.conf 的配置文件如下所示:
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# source
a1.sources.r1.type = spooldir
a1.sources.r1.spoolDir = /root/flume
a1.sources.r1.fileHeader = true
# Describe the sink
a1.sinks.k1.type = avro
#这是接收方
a1.sinks.k1.hostname = 192.168.17.10
a1.sinks.k1.port = 8888
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1第二步: 虚拟机上启动flume,此处我是在flume的安装目录里启动的,具体情况具体分析
bin/flume-ng agent -n a1 -c conf/ -f conf/flume-push.conf -Dflume.root.logger=WARN,console切换到flume监控的目录中,并手工的造数据
cd /root/flume
echo "bejing huan ying ni1" >> test.log观察本机上的ss的运行结果: 结果如下所示:
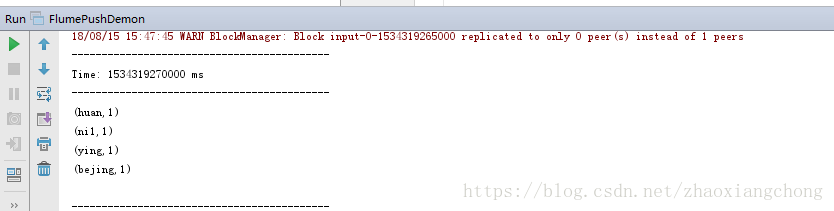
这就是刚才手工插入的数据,正确显示,验证完毕
说明: 1 ss和flume中的ip地址,指的是接收flume并运行sparkstream的地址,因为我的ss是运行在本地,就配置了本地的虚拟机vmnetwork1的地址
2 此种方式,接收的flume的ss地址只能有一个,个人认为在数据量大时会有弊端
3 当前批次文件执行完之后,flume会在文件的名称后面增加COMPLETED,比如将文件” test.log” 变更为”test.log.COMPLETED”,个人认为是标记用的,防止数据重复
4 测试中发现,如果在不同的时间内产生了两个相同的文件,flume会报错的。比如先手工产生文件test.log,flume执行完之后,会将文件” test.log” 变更为”test.log.COMPLETED"。如果此时再手工产生一个文件test.log,flume就会报文件名重复使用的错误。我的理解就是flume依据文件名,来区分是否进行了同步