背景
在项目初期的时候,大家都是赶着上线,一般来说对日志没有过多的考虑,当然日志量也不大,所以用log4j就够了,随着应用的越来越多,日志散落在各个服务器的logs文件夹下,确实有点不大方便。或者是分布式系统:当我们需要日志分析的时候你大概会这么做:直接在日志文件中 grep、awk就可以获得自己想要的信息。这就造成了日志查询极其繁琐;如果日志中有敏感数据,也要考虑是否开放给所有人
可能遇到的问题:
日志量太大如何归档、文本搜索太慢怎么办、如何多维度查询
应用太多,面临数十上百台应用时你该怎么办,随意登录服务器查询log对系统的稳定性及安全性肯定有影响如果使用人员对Linux不太熟练那面对庞大的日志简直要命那么为什么要用ELK呢?ELK又能给我们解决哪些问题呢?
ELK使用组件简介
- Filebeat :是一个日志文件托运工具,在你的服务器上安装客户端后,filebeat会监控日志目录或者指定的日志文件,追踪读取这些文件(追踪文件的变化,不停的读)【Ruby语言】
- Kafka:是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模的网站中的所有动作流数据
- Logstash:【如果对日志做深加工就需要这个组件】是一根具备实时数据传输能力的管道,负责将数据信息从管道的输入端传输到管道的输出端;与此同时这根管道还可以让你根据自己的需求在中间加上滤网,Logstash提供里很多功能强大的滤网以满足你的各种应用场景
- 它提供了一个分布式多用户能力的全文搜索引擎,基于RESTFUL web接口
- 是ElasticSearch的用户界面
在实际应用场景下,为了满足大数据实时检索的场景,利用Filebeat去监控日志文件,将Kafka作为Filebeat的输出端,Kafka实时接收到Filebeat后以Logstash作为输出端输出,到Logstash的数据也许还不是我们想要的格式化或者特定业务的数据,这时可以通过Logstash的一些过滤插件对数据进行过滤最后达到想要的数据格式以ElasticSearch作为输出端输出,数据到ElasticSearch就可以进行丰富的分布式检索了。Kibana可以将ElasticSearch里的数据很好的展示给用户使用
| 名称 | 简称 | 组织架构 | 简介 | 推荐使用 |
|---|---|---|---|---|
| 方案1 | ELK | logstash+es+kibana | Logstash部署一般比较吃内存 | 经典模式 |
| 方案2 | EFK | filebeat+es+kibana | filebeat比Logstash轻量许多此种架构非常适合中小型单的日志收集系统。因为logstash里面提供了一些丰富的过滤功能,其实一般很多系统都用不上,所以就可以直接采用filebeat进行日志的收集 | 轻量级,无侵入 |
| 方案3 | FELK | filebeat+logstash+es+kibana | 此种设计适合需要丰富采集日志信息的系统 | |
| 可部署一台Logstash用于接收filebeat收集到的日志进行集中的过滤后再传给es。当然你要是机器足够的话 Logstash也可以部署集群减轻压力 | ||||
| 方案4 | 个性化框架 | FELK 引入kafka或者redis | 高并发大数据流量系统采用的方案 |
一般来说其实第一种和第二种用的更多,相信绝大部分公司使用第一种就可以满足
方案1 ELK
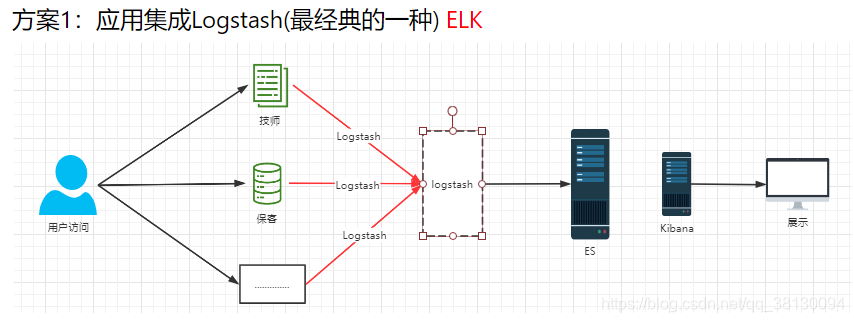
优势:集成方便对应用侵入少,搭建容易
短板:
- 如果web应用比较多,都同时往logstash直接发送日志,logstash可能扛不住压力
- 还有一些其他系统也需要收集日志,比如大数据系统,这种架构可能就不是很合适
- logstash是一个重量级的中间件,很耗内存
集成方式
1:在springboot应用的pom.xml中添加logstash-logback-encoder依赖
<!--集成logstash-->
<dependency>
<groupId>net.logstash.logback</groupId>
<artifactId>logstash-logback-encoder</artifactId>
<version>5.3</version>
</dependency>
2:web应用下的logback-spring.xml文件内容需要修改
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE configuration>
<configuration>
<include resource="org/springframework/boot/logging/logback/defaults.xml"/>
<include resource="org/springframework/boot/logging/logback/console-appender.xml"/>
<!--应用名称-->
<property name="APP_NAME" value="APP_NAME"/>
<!--日志文件保存路径-->
<property name="LOG_FILE_PATH" value="${LOG_FILE:-${LOG_PATH:-${LOG_TEMP:-${java.io.tmpdir:-/tmp}}}/logs}"/>
<contextName>${APP_NAME}</contextName>
<!--每天记录日志到文件appender-->
<appender name="FILE" class="ch.qos.logback.core.rolling.RollingFileAppender">
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>${LOG_FILE_PATH}/${APP_NAME}-%d{
yyyy-MM-dd}.log</fileNamePattern>
<maxHistory>30</maxHistory>
</rollingPolicy>
<encoder>
<pattern>${FILE_LOG_PATTERN}</pattern>
</encoder>
</appender>
<!--输出到logstash的appender-->
<appender name="LOGSTASH" class="net.logstash.logback.appender.LogstashTcpSocketAppender">
<!--可以访问的logstash日志收集端口-->
<destination>127.0.0.1:4560</destination>
<encoder charset="UTF-8" class="net.logstash.logback.encoder.LogstashEncoder"/>
</appender>
<root level="INFO">
<appender-ref ref="CONSOLE"/>
<appender-ref ref="FILE"/>
<appender-ref ref="LOGSTASH"/>
</root>
</configuration>
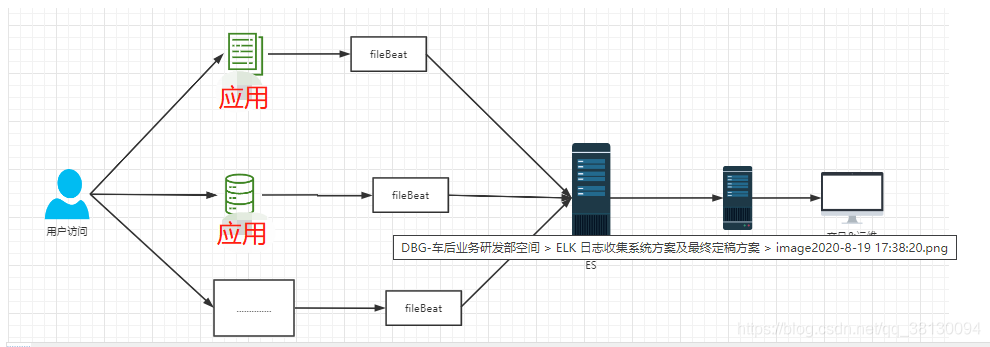
方案二 EFK
fileBeat插件同步数据到es EFK
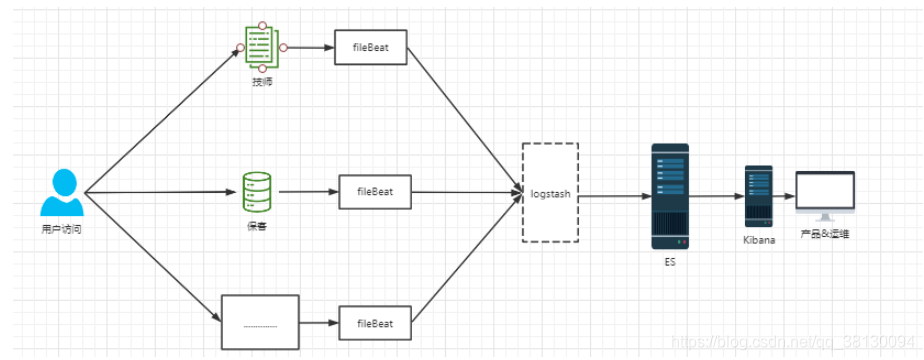
方案三: FELK
如果需要对数据进行加工处理就需要logstash
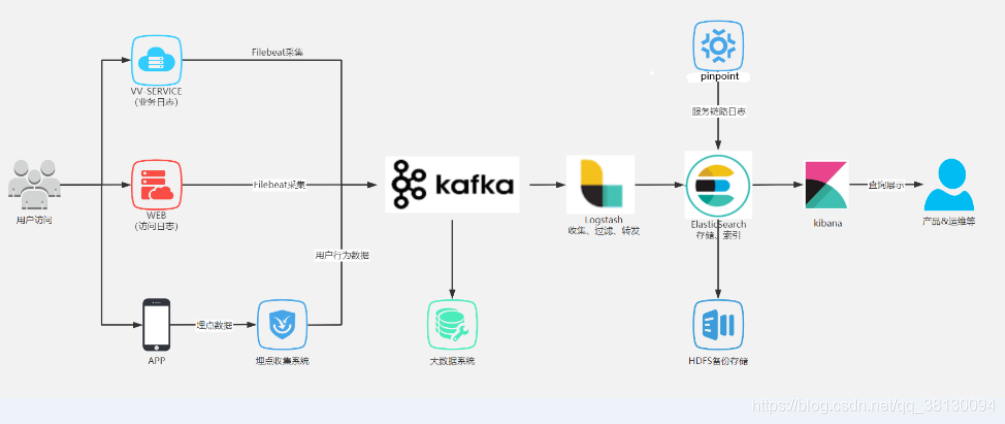
方案四:个性化框架
(采集到的日志需要进行加工或者多方需要的情况)引入kafka或者redis。一般也会采用Filebeat+(消息中间件)+logstash(也可以不要,直接通过消息中间件入es)+es+kibana
大型互联网公司后端日志收集系统架构:相当吃服务器资源,可能只有头部互联网公司的核心业务在用
通过redsi/kafka中间件来限流
总结:
各个方案各有优缺点,在合适的场景使用合适的解决方案才是我们所追求的目标