目录
windows的Navicat连接ubuntu16.04的mysql-cluster
1)在装有数据库的那台电脑,登入mysql后,更改 "mysql" 数据库里的 "user" 表里的 "host" 项,从"localhost"改成"%":
2)登入MySQL:
cd /usr/local/mysql
bin/mysql -u root -p
Enter password:hjhmysql
3)切换数据库
mysql>use mysql;
mysql>select host, user from user;
+-----------+-----------+
| host | user |
+-----------+-----------+
| % | hive |
| localhost | hive |
| localhost | mysql.sys |
| localhost | root |
+-----------+-----------+
4 rows in set (0.00 sec)
修改登录权限
mysql>update user set host = '%' where user = 'root';
刷新,生效,最后一步,至关重要
mysql>flush privileges;

连接成功!
windows eclipse连接ubuntu大数据框架
hadoop-eclipse-plugin-3.0.1.jar工具包制作:
为了做mapreduce开发,要使用eclipse,并且需要对应的hadoop插件hadoop-eclipse-plugin-3.0.1.jar,首先说明一下,在hadoop1.x之前官方hadoop安装包中都自带有eclipse的插件,而如今随着程序员的开发工具eclipse版本的增多和差异,hadoop插件也必须要和开发工具匹配,hadoop的插件包也不可能全部兼容.为了简化,如今的hadoop安装包内不会含有eclipse的插件.需要各自根据自己的eclipse自行编译从Eclipse3.5开始,安装目录下就多了一个dropins目录。只要将插件解压后拖到该目录即可安装插件。
将hadoop-3.0.1-src.tar.gz解压,比如:D:\hadoop\hadoop-3.0.1。win10需要管理员权限解压eclipse Mars.2 Release (4.5.2)的工具包时dropins,把hadoop-eclipse-plugin-2.7.3.jar复制到dropins目录下重启eclipse,点击window->preferences,出现Hadoop Map/Reduce

添加Hadoop解压路径D:\Big Data\hadoop\hadoop-3.0.1;点击Open Perspective看到Map/Reduce,点击,下面的控制台多出了Map/Reduce Locations视图右键Map/Reduce Locations试图的空白处,选择新建,定义Hadoop集群的链接。

此处Location name起名:
BigDate_Hadoop因为本次环境为hadoop3.0.1环境没有设置JobTracker端口所以默认端口为50030HDFS路径端口在core-site.xml的fs.defaultFS中也没有设置所以hdfs端口使用hdfs-sit.xml的rpc端口9820

到此连接成功,与访问服务器web网页显示一致。
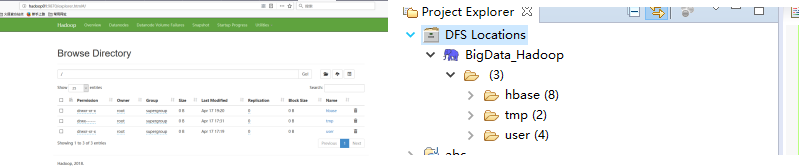
在eclipse上进行开发
添加开源中国maven库:http://maven.oschina.net/home.html
maven\conf\settings.xml
a.准备安装了maven,我安装的是maven3.5.0
b.安装了JDK,我安装的是JDK1.8.0_131
c.下载protocol buffers的编译器程序即protoc.exe,放到通过PATH环境变量可以找到的目录(或者将protoc.exe所在目录加入到PATH环境变量中)。
Protocol Buffers(简称protobuf)是谷歌的一项技术,用于将结构化的数据序列化、反序列化,经常用于网络传输。这货实际上类似于XML生成和解析,但protobuf的效率高于XML,。
不过protobuf生成的是字节码,可读性比XML差。类似的还有json、Java的Serializable等解压后有两个文件:protobuf-java-2.5.0.jar和protoc.exe。
protobuf-java-2.5.0.jar即protobuf所需要的jar包,如果用maven的话可以无视这个文件;
protoc.exe是protobuf代码生成工具。protoc.exe,放到通过PATH环境变量可以找到的目录。
目录(或者将protoc.exe所在目录加入到PATH环境变量中)。本次放到D:\Program Files\apache-maven-3.5.0\bin
d.通过maven获取源码
解压源码压缩包到D:\Big Data\hadoop进入源码根目录下的hadoop-maven-plugins目录,执行mvn install。(windows系统进入cmd)注意执行mvn命令的过程中,可能下载很多maven所需文件,而且因为网速问题,可以经常出错。这时的解决办法是不断重新执行相关mvn命令(包括下面那个步骤也是如此),直到不是因为下载东西导致出错(此时才需要真正查看错误信息)。成功后会显示BUILD SUCCESS。



进入hadoop-maven-plugins目录的上层目录(即源代码根目录),执行
mvn eclipse:eclipse -DskipTests
成功后会显示BUILD SUCCESS。(等待时间较长)
打开Eclipse,专门建一个workspace-BigData,导入hadoop-3.0.1-src
mvn install: 安装package到本地仓库,方便本地其它项目使用
mvn eclipse:eclipse: 生成Eclipse的配置文件(先删除再生成)
下载插件:
http://repo1.maven.org/maven2/.m2e/connectors/m2eclipse-mavenarchiver/0.17.2/N/LATEST
安装插件时候报错:
错误1:
Plugin execution not covered by lifecycle configuration 错误:
解决方案一:在pom.xml中在报错的plugins的外面再包上一层<pluginManagement></pluginManagement>此方法不可取,因为
有些是父类改完之后影响子类
解决方案二:
通过在eclipse下载插件:m2e-apt解决,下载路径:http://download.jboss.org/jbosstools/updates/m2e-extensions/m2e-apt
或者在Eclipse Marketplace查找apt stands for Annotation Processing Tool
解决之后重启eclipse
错误2:
hadoop-annotations工程的pomx.xml中一直有错Missing artifact jdk.tools:jdk.tools:jar:1.8
首先把D:\Program Files\repository-BigData\jdk\tools\jdk.tools\1.8该路径下tools.jar包copy进去,改名:jdk.tools-1.8.jar把自带的<systemPath>${JAVA_HOME}/../lib/tools.jar</systemPath>改成如下即可,把..去掉,估计是带..无法识别
<dependency>
<groupId>jdk.tools</groupId>
<artifactId>jdk.tools</artifactId>
<version>1.8</version>
<scope>system</scope>
<systemPath>${JAVA_HOME}/lib/tools.jar</systemPath>
</dependency>
hadoop-annotations中的问题解决后,整个工程的Missing artifact jdk.tools:jdk.tools:jar:1.8均消失

进入D:\Big Data\hadoop\hadoop-3.0.1-src\hadoop-common-project\hadoop-common\src\test\proto>
protoc --java_out=../java *.proto
执行后,以上错误消失,在TestRPC.java中导入正确的包import org.apache.hadoop.ipc.protobuf.TestProtos;
错误4:
AvroRecord cannot be resolved to a type TestAvroSerialization.java
需要下载avro-tools-1.7.7.jar文件,目前2018/04/19最新版1.8.2,此包release于2017/05/20
把下载后的avro-tools-1.7.7.jar放到,当前hadoop支持1.7.7
D:\Big Data\hadoop\hadoop-3.0.1-src\hadoop-common-project\hadoop-common\src\test\avro目录下
cmd进入命令行,进入源码根目录下的“hadoop-common-project\hadoop-common\src\test\avro”执行命令,
java -jar avro-tools-1.7.7.jar compile schema avroRecord.avsc ../java 。
其中avsc文件是avro的模式文件,上面命令是要通过模式文件生成相应的.java文件。
刷新项目,问题解决
错误5:eclipse出的错误:

解决方法一:
eclipse -application org.eclipse.equinox.p2.garbagecollector.application-profile D__Program Files_eclipse_committers-mars_eclipse
但是还是有错
解决方法二:Help->Install New SoftWare->Available Software Sites 中所有URL删除之后重启即可。
错误6:
hadoop-streaming 异常
在eclipse中,右键单击hadoop-streaming项目,选择“Properties”,左侧栏选择JavaBuild Path,然后右边选择Source标签页,出错的是路径。点击“Link Source按钮”,选择被链接的目录为“<你的源代码根目录>/hadoop-yarn-project/hadoop-yarn
/hadoop-yarn-server/hadoop-yarn-server-resourcemanager/conf”,链接名可以使用显示的(也可以随便取);
inclusionpatterns中添加capacity-scheduler.xml,exclusion patters中添加**/*.java,这个信息与出错的那项一样;
完毕后将出错的项删除。刷新hadoop-streaming项目。
错误7:
①Plugin execution not covered by lifecycle configuration: org.apache.maven.plugins:
maven-dependency-plugin:3.0.2:list (execution: deplist, phase: compile)
②Plugin execution not covered by lifecycle configuration: org.apache.hadoop:hadoop-maven-plugins:3.0.1:
resource-gz (execution: resource-gz, phase: generate-resources)
③Plugin execution not covered by lifecycle configuration: org.apache.hadoop:hadoop-maven-plugins:3.0.1:protoc
(execution: compile-protoc, phase: generate-sources)
④Plugin execution not covered by lifecycle configuration: org.apache.hadoop:hadoop-maven-plugins:3.0.1:
version-info (execution: version-info, phase: generate-resources)
解决:加入</pluginManagement>进行去错
a.下载winutils.exe和hadoop.dll
https://blog.csdn.net/woshixuye/article/details/53537519
在resources中添加log4j.properties文件,并配置内容
1.1 缺少winutils.exe
Could not locate executable null \bin\winutils.exe in the hadoop binaries
1.2 缺少hadoop.dll
Unable to load native-hadoop library for your platform… using builtin-Java classes where applicable
把下载完的winutils.exe和hadoop.dll放到HAPOOP_HOME目录的bin下
hadoop.dll需要放到c:\windows\system32
b.windows中配置hadoop和spark的环境变量
加入HADOOP_HOME和PATH中加入%HADOOP_HOME\bin
配置完环境变量还需要重启一下电脑才行
在wordcount.java程序的Run Configurations中配置
hdfs://hadoop01:9820/user/root/input
hdfs://hadoop01:9820/user/root/output
出现错误:java.lang.UnsatisfiedLinkError: org.apache.hadoop.io.nativeio.NativeIO$Windows.access0
首先下载eclipse的反编译插件:查找jad
![]()
参照:https://blog.csdn.net/xubo245/article/details/50587660
hadoop.dll和hadoop版本不匹配导致出错
去csdn搜索与版本匹配的hadoop.dll和winutils.exe复制到对应的%HADOOP_HOME\bin下和c:\windows\system32
再次执行wordcount.java成功!!!
指定好输入输出路径,如图:


driver=com.mysql.jdbc.Driver
urluser=jdbc:mysql:loadbalance://hadoop01:3306,hadoop02:3306,hadoop03:3306,hadoop04:3306,hadoop05:3306/harbour_user_db?roundRobinLoadBalance=true
urlbusiness=jdbc:mysql:loadbalance://hadoop01:3306,hadoop02:3306,hadoop03:3306,hadoop04:3306,hadoop05:3306/harbour_business_db?roundRobinLoadBalance=true
username=root
password=hjhmysql
#定义初始连接数
initialSize=0
#定义最大连接数
maxActive=100
#定义最大空间
maxIdle=100
#定义最小空间
minIdle=1
#定义最长等待时间
maxWait=60000
salt=\u4ECA\u5929\u4F60\u5403\u4E86\u5417?
备注:由于oozie的workflow.xml写起来比较费劲,而自定义的shell定时自动执行hadoop离线计算流程,只有执行工作流功能,没有监测执行功能,不能直观查看问题所在,而且没有log,所以选择有jenkins结合定时执行shell的方式来执行hadoop工作流