hadoop离线(Hadoop&HDFS)
-
hadoop
- 狭义hadoop apache 软件 java语言 是大数据的处理平台
- HDFS(hadoop分布式文件系统):大数据的分布式存储
- MapReduce(分布式计算框架):大数据分布式处理计算
- YARN:集群资源(RAM CPU)管理任务调度
- 广义hadoop hadoop生态体系 生态圈
- 狭义hadoop apache 软件 java语言 是大数据的处理平台
-
hadoop作为大数据的平台软件 并不会跟具体的行业业务挂钩
它只提供了大数据的存储分析解决方案 至于你用于什么行业 是用户的事
-
hadoop版本
-
社区版:官方维护的版本 来自于apache软件基金会维护
-
商业版:第三方的商业公司在社区版的基础进行商业化开发发现 重点提高稳定兼容性
著名的商业版本叫做:CDH
hadoop本身发展至今存在着3个大系列版本:1.X 2.X 3.X
当下企业中用的做多的是2系列的高阶版本:2.6~2.8
apahce: hadoop-2.7.4-src.tar.gz 源码包 hadoop-2.7.4.tar.gz 官方编译的安装包 CDH: hadoop-2.6.0-cdh5.14.0-src.tar.gz 源码包 hadoop-2.6.0-cdh5.14.0.tar.gz cdh编译的安装包 关于cdh版本号 只有保证cdh版本号一致 各个软件之间是兼容的。 -
-
集群规划
所谓的集群规划指的是根据软件特性并且结合服务器硬件特性做出合理安排。
- 如果某个组件需要大量内存或者磁盘 优先为其分配大高内存高磁盘机器
- 如果两个组件之间有需求上的冲突 尽量不要部署在一台机器上
- 如果两个组件之间有工作上的依赖 尽量保持在一台机器上
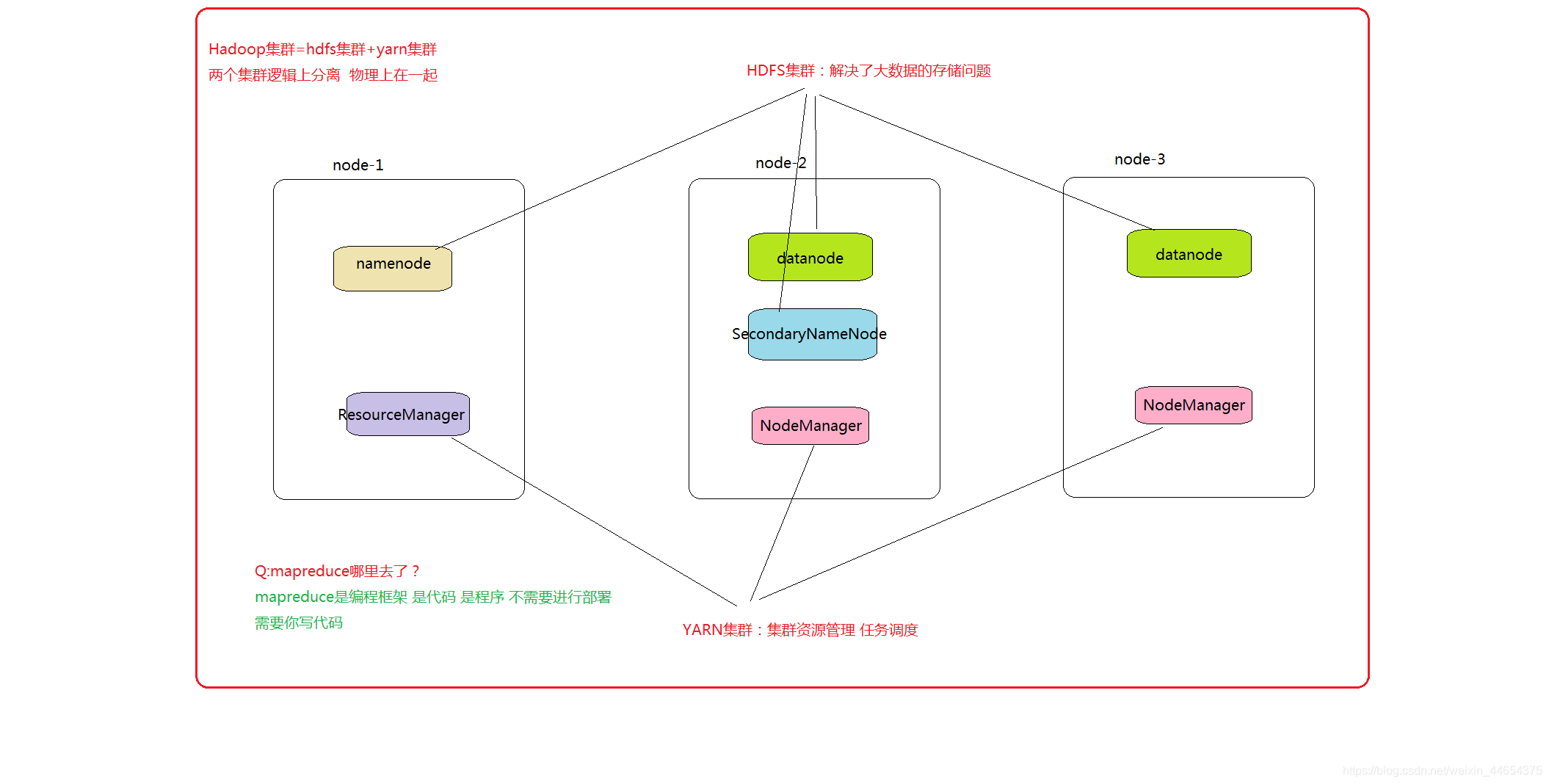
hadoop集群 hdfs集群: 主角色:namenode 从角色:datanode "秘书"角色:secondarynamenode yarn集群: 主角色:resourcemanager 从角色:nodemanager nodemanager和datanode是好基友 两个角色几乎成双成对出现 关于hadoop中角色的简称: namenode nn datanode dn secondarynamenode snn resourcemanager rm nodemanager nm mapreduce mr以三台机器继续部署规划:
node-1: namenode datanode | resourcemanager nodemanager node-2: datanode secondarynamenode | nodemanager node-3: datanode | nodemanager如果集群需要扩展,增加哪些角色呢?
node-4: datanode nodemanager node-5: datanode nodemanager node-6: datanode nodemanager ....... -
源码编译
-
软件的运行需要操作系统的支持 不同的操作直接存在着差异
官方编译好的版本是最大公约数编译 为了更好的是软件特性匹配自己的操作系统
往往需要结合源码再重新编译
-
修改软件源码 使之符合自己的特性 这种情况也许重新编译
-
-
hadoop安装包目录结构
- bin :基本管理脚本
- sbin:集群启动关闭脚本
- etc:配置文件
- share:编译后的jar 和自带样例
-
第一类 :1个 hadoop-evn.sh
export JAVA_HOME=/export/servers/jdk1.8.0_65 保证hadoop启动运行的时候可以加载的jdk -
第二类:4个(common hdfs yarn mapreduce) xxxx-site.xml
-
core-site.xml
指定使用hdfs作为默认文件系统 以及指定hdfs主角色所在ip和端口 <property> <name>fs.defaultFS</name> <value>hdfs://node-1:9000</value> </property> 指定hadoop运行时存储数据所在的位置 <property> <name>hadoop.tmp.dir</name> <value>/export/data/hadoopdata</value> </property> -
hdfs-site.xml
指定hdfs存储文件的备份数 默认是3 <property> <name>dfs.replication</name> <value>2</value> </property> 指定secondarynamenode所在机器的ip和端口 <property> <name>dfs.namenode.secondary.http-address</name> <value>node-2:50090</value> </property> -
mapred-site.xml
指定mr程序运行的框架,也就是由谁为mr程序运行提供运算的资源 <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> -
yarn-site.xml
指定yarn主角色所在的机器 <property> <name>yarn.resourcemanager.hostname</name> <value>node-1</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property>
-
-
第三类:1个 slaves
从角色所在机器的ip 注意一行一个 node-1 node-2 node-3 -
namenode format操作
-
是在集群首次启动之前执行 且执行一次 后续不需要了
-
该操作准备来说是一个初始化的操作
-
format中主要生成了hdfs(namenode)工作所需要的目录和一些初始化的文件
这个目录就是配置中指定的:hadoop.tmp.dir -
此外初始化中还会有集群的一些基本属性信息 保证集群的后续运行
-
在namenode所在的机器执行
-rw-r--r--. 1 root root 321 Feb 16 12:13 fsimage_0000000000000000000 -rw-r--r--. 1 root root 62 Feb 16 12:13 fsimage_0000000000000000000.md5 -rw-r--r--. 1 root root 2 Feb 16 12:13 seen_txid -rw-r--r--. 1 root root 208 Feb 16 12:13 VERSIONQ:如果初始化了多次怎么办?
因为format多次会导致主从之间的集群标识clusterID不一致 造成互相不认识 并且数据丢失 因此在企业中 不允许犯错 如果真的格式化了多次 删除每台机器 上hadoop.tmp.dir指定的文件夹 重新format一次 这样就相当于搭建了一个新集群 -
-
hadoop集群的启动
-
单节点逐个启动
- hdfs:hadoop-daemon.sh start|stop (namenode/datanode/secondarynamenode)
- yarn:yarn-daemon.sh start|stop (resourcemanager/nodemanager)
-
脚本一键启动
- hdfs: start-dfs.sh stop-dfs.sh
- yarn:start-yarn.sh stop-yarn.sh
更加狠一点:start-all.sh stop-all.sh
注意:要想使用官方的一键脚本 提取配置好免密登录以及slaves文件
-
-
web页面
- hdfs集群: http://namenode_host:50070
- yarn集群:http://resourcemanager_host:8088
-
hadoop初体验
-
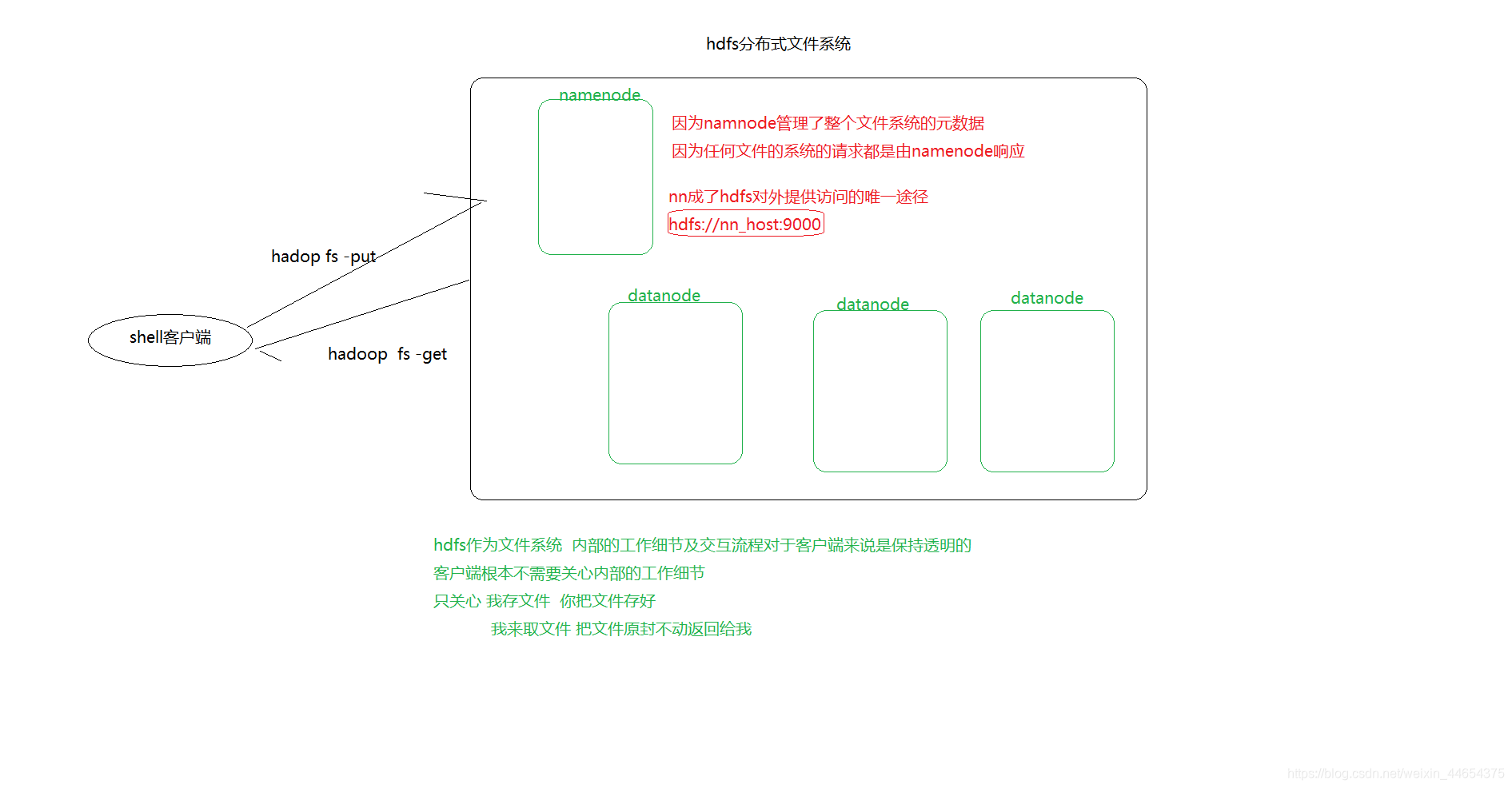
hdfs
本质上就是文件系统 用来存储文件
和标准文件系统一样 文件夹就是文件夹 文件就是文件
针对hdfs操作 比较慢?为什么慢? 和底层是分布式有关系吗?
-
yarn+mapreduce
mr程序本质就是java程序
mr程序第一步都是去找yarn,找yarn干嘛的?yanr是管理资源的?是去要资源的吗?
mr程序是有两个阶段组成的:map reduce
先map在reduce?
为什么数据量小的时候分布式计算体现不出来高效率呢?
-
-
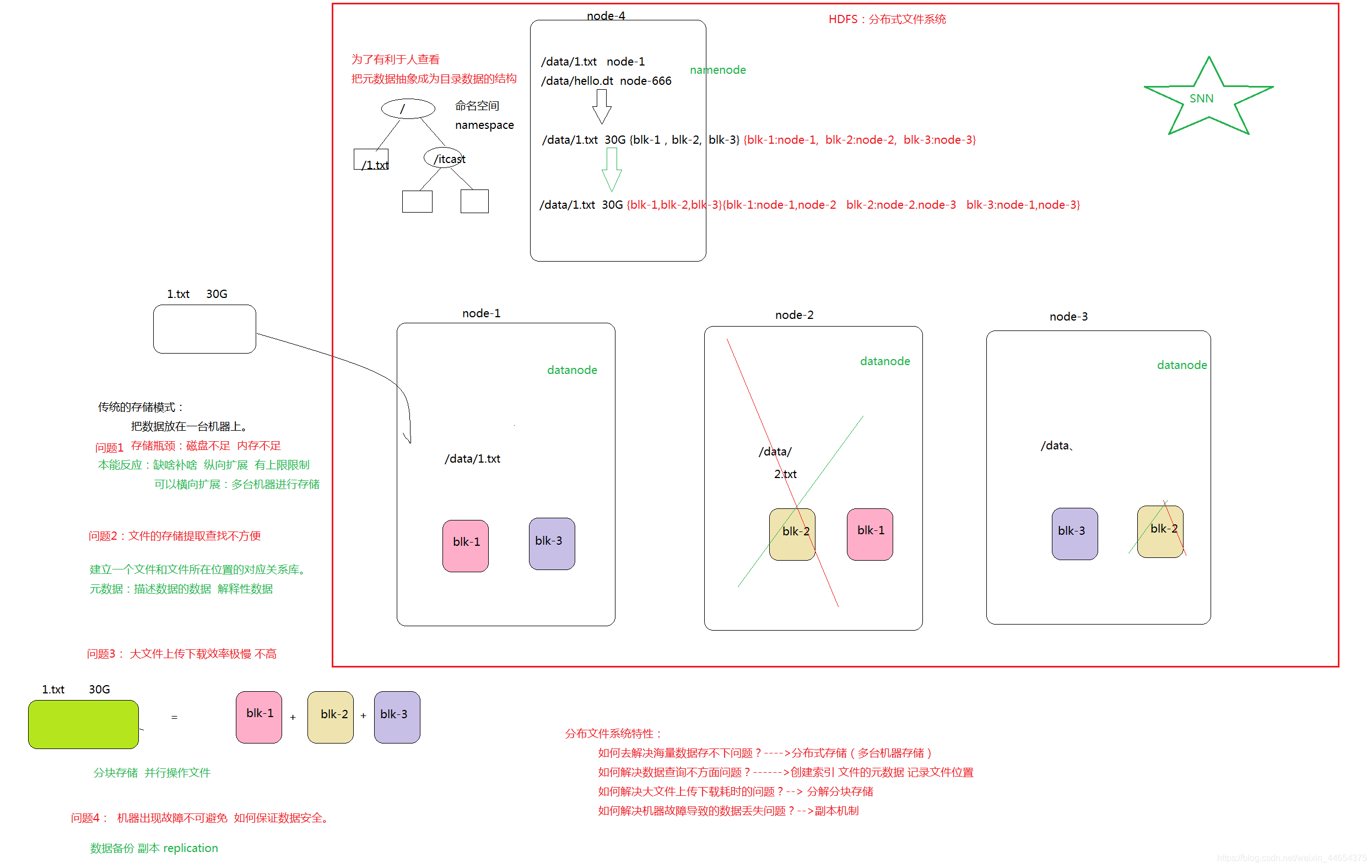
hdfs重要特性
hdfs首先它是文件系统 其次才是他的分布式特性。
-
主从架构
- 主角色 namenode
- 从角色 datanode
主从角色各司其职 共同配合对外提供分布式的文件存储服务。
-
分块存储 (hadoop2.x 128M 1.x 64M)
1.txt 150M----> blk-1:0--128M blk-2:128--150M 2.txt 100M----> blk-1:0--100M -
namenode 管理文件系统元数据 目录树的命名空间
datanode 管理具体的文件数据块 定时向namenode进行汇报
-
副本机制
hdfs默认副本数为3 (最终是3个 1+2=3)
1.txt=blk-1+blk-2+blk-3 设置副本数为3 最终会有几个block? 9块 blk-1,blk-2,blk-3---->blk-1,blk-2,blk-3----->blk-1,blk-2,blk-3 -
不支持文件的修改
-
-
hdfs shell客户端操作
hadoop fs ars hdfs://nn_host:9000/ 操作的是hdfs文件系统 hadoop fs ars file:/// 操作的是本地文件系统 hadoop fs ars gfs://ip:port/ 操作的就是google文件系统 一般可以简写 hadoop fs ars / 具体指的是什么文件系统 取决于配置文件中:fs.defaultFS-
put 文件上传操作 把文件从本地文件系统上传至hdfs
何谓本地? 执行命令的时候客户端所在机器的文件系统
hadoop fs -put file:///root/zookeeper.out hdfs://node-1:9000/a/b/c hadoop fs -put file:///root/zookeeper.out hdfs://node-1:9000/a/b/c 全敲 hadoop fs -put install.log /a/b/c 简敲 -
get 文件下载操作 把文件从hdfs下载到本地文件系统
hadoop fs -get hdfs://node-1:9000/a/b/c/zookeeper.out file:///root/allen/ hadoop fs -get /a/b/c/install.log ./ -
appendToFile
可以用于小文件的合并
-
setrep 修改指定文件的副本个数
注意:十分耗时 在企业实际操作中 避免使用 会造成hdfs集群性能问题
对于文件的副本数 通常在上传至hdfs之前确定好
-