版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/kiss_xiaojie/article/details/77926044
Hadoop —- HDFS
- HDFS 逻辑架构
HDFS是一个主从逻辑(master/slave)体系结构。
- master —>
NameNode:执行文件系统的命名空间操作,维护元数据。NameNode 不参与文件的传输。 - slave —>
DataNode:依照 NameNode 的命令赋值处理客户的读写请求。DataNode 按块(默认块为 128MB
)存储数据但不知数据的 整体结构。
- master —>
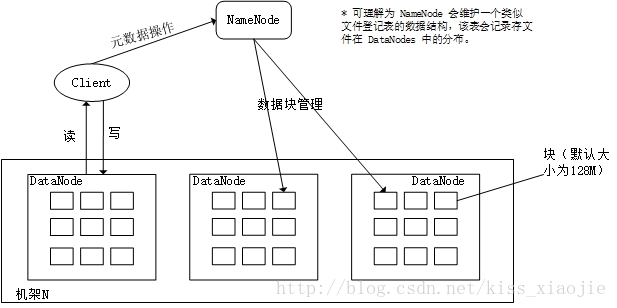
NameNode
- HDFS 主进程名,整个集群中只有一个。可以说 NameNode 开启即是集群的开始,NameNode 关闭就是集群的停止。
- NameNode 的三大功能
- 应答客户端存取(具体到某个数据块的存取时,由所在的 DataNode 负责。这样可大大减轻 NameNode 的负担)
- 协调整个 HDFS 存取
- NameNode 的被设计的很智能,而 DataNode 则毫无智能所言(也就是对全局信息了解甚少)
- DataNode 实际上仅仅是一个命令执行者,并不知道文件的 存在 ,这就需要 HDFS 的协调了
- 管理 HDFS 命名空间(可理解成分布式的文件管理)
- NameNode 使用 metadata(元数据,一数据结构)描述、管理整个文件系统。它包括了文件存储位置的分布、文件属性信息以及 DataNode 状体信息等
- metadata 的持久化(物理结构)是通过 edits 和 fsimage
- 日志文件 edits 记录 HDFS 元数据的变化
- fsimage 存储文件系统的命名空间,包括文件的映射、文件的属性信息。
- NameNode 启动时,从磁盘中读取这两个文件,通过 fsimage 形成初步的 metadata,然后利用事务日志更新 metadata ,最后将新的元数据保存成本地磁盘的新的映像文件(fsimage)。这样,初始化完毕,且可以截去旧的事务日志。(复杂点的 HDFS 架构还设有 Secondary NameNode 辅助 NameNode 在运行中更新这两个文件)
- edits 过大问题:运行 NameNode 过程中会持续把操作写到 edits 事务日志中,这最终会导致 edits 文件过大。解决:NameNode 采用轮询方式写出 edits。
- NameNode 单点故障
- 因为 NameNode 整个集群中只有一个,所以一旦 NameNode 宕机,整个集群服务都随之崩溃。
- 解决方案
- 1)对 NameNode 进行多机热备。或参考 MapR 公司的方案,该公司对 HDFS 进行了重构,不存在单点故障。(可随时恢复)
- 2)设置 edits 和 fsimage 副本。(恢复时需要时间)
DataNode
- 部署 DataNode 的节点被称为存储从节点,主要是用来执行 NameNode 的命令、监控并上传所在主机的数据块状态等。
- DataNode 中同一数据往往有多个副本,这是利用冗余来提高可靠性。当 NameNode 发现数据的某副本失效,NameNode 会智能的指导数据补充备份。
- DataNode 中数据副本所处的位置也有讲究。NameNode 会综合机架、结点位置来指定。
- DataNode 与 NameNode 的通信是使用 心跳包 完成的。
- NameNode 不会主动的请求 DataNode ,而是 DataNode 会隔一定的时间周期地向 NameNode 发送数据(心跳包,其中包括各种状态信息)。NameNode 指挥 DataNode 也是通过响应心跳包完成的。
- DataNode 超过一定时间仍没发送心跳包,NameNode 会认为它已经死掉,不再向它指派任务。
HDFS 存取步骤(略)
HDFS 其他概念
- 移动计算比移动数据更划算
- 对于大文件来说,移动计算要比移动数据的代价要低。如果在数据旁边执行操作,那么效率会比较高,当数据特别大的时候效果更明显,这样可以减少网络的拥塞提高系统的吞吐量。
- HDFS 提供了接口,以便让程序到自己数据存储的地方执行。
- DataNode 使用本地文件系统来存储 HDFS 数据,但是它对 HDFS 文件一无所知,只是用一个个文件存储 HDFS 的每个数据块。
- 移动计算比移动数据更划算