Pandas Task上 综合测试
一、2002 年-2018 年上海机动车拍照拍卖
问题
(1) 哪一次拍卖的中标率首次小于 5%?
load_path = '../data/'
df_car = pd.read_csv(load_path+'2002年-2018年上海机动车拍照拍卖.csv')
df_car
df_car['rate'] = df_car['Total number of license issued'] / df_car['Total number of applicants']
df_car.loc[df_car['rate']<0.05].head()

15年的5月
(2) 将第一列时间列拆分成两个列,一列为年份(格式为 20××),另一列为
月份(英语缩写),添加到列表作为第一第二列,并将原表第一列删除,
其他列依次向后顺延。
list_date = list(df_car['Date'].str.split('-'))
list_year = [x[0] for x in list_date]
list_month = [x[1] for x in list_date]
df_car['month'] = list_month
def year_change(x):
y = []
for i in x:
if len(i) == 1:
y.append('200'+i)
else:
y.append('20'+i)
return y
list_year1 = year_change(list_year)
df_car['year'] = list_year1
df_car.drop(columns='Date', inplace=True)
cols = list(df_car.columns)
cols.remove('month')
cols.remove('year')
cols.insert(0, 'month')
cols.insert(0, 'year')
cols
df_car = df_car[cols]
df_car

(3) 按年统计拍卖最低价的下列统计量:最大值、均值、0.75 分位数,要求
显示在同一张表上。
df_car.groupby('year')['lowest price '].agg(['max', 'mean', ('quantile(q=0.75)' ,lambda x: x.quantile(q=0.75))])

(4) 现在将表格行索引设为多级索引,外层为年份,内层为原表格第二至第
五列的变量名,列索引为月份。
df_car.set_index(['year', 'Total number of license issued', 'lowest price ', 'avg price', 'Total number of applicants'])

(5) 一般而言某个月最低价与上月最低价的差额,会与该月均值与上月均值
的差额具有相同的正负号,哪些拍卖时间不具有这个特点?
list_1 = []
list_2 = []
for i in range(202):
list_1.append(df_car.loc[i+1, 'lowest price '] - df_car.loc[i, 'lowest price '])
list_2.append(df_car.loc[i+1, 'avg price'] - df_car.loc[i, 'avg price'])
def pos_neg(list1, list2):
index = []
for i in range(202):
if list1[i] * list2[i] < 0:
index.append(i+1)
return index
df_car.loc[index_list]

(6) 将某一个月牌照发行量与其前两个月发行量均值的差额定义为发行增
益,最初的两个月用 0 填充,求发行增益极值出现的时间。
list_issue = []
for i in range(201):
list_issue.append(df_car.loc[i+2, 'Total number of license issued'] - 0.5*(df_car.loc[i, 'Total number of license issued']+df_car.loc[i, 'Total number of license issued']))
list_issue.insert(0, 0)
list_issue.insert(0, 0)
df_car['issue_gain'] = list_issue
df_car

df_car['issue_gain'].max()
df_car.loc[df_car['issue_gain']==8500]

2008年的1月出现最大值
df_car['issue_gain'].min()
df_car.loc[df_car['issue_gain']==-7000]

2008年的4月出现最小值
二、2007 年-2019 年俄罗斯机场货运航班运载量
问题
(1) 求每年货运航班总运量。
df_air = pd.read_csv(load_path+'2007年-2019年俄罗斯货运航班运载量.csv')
df_air.groupby('Year')['Whole year'].sum()

(2) 每年记录的机场都是相同的吗?
df_air.groupby('Airport name')['Airport coordinates'].nunique()

不是一样的
(3) 按年计算 2010 年-2015 年全年货运量记录为 0 的机场航班比例。
df_0 = pd.DataFrame()
df_0 = df_air.loc[df_air['Whole year']==0]
df_0.groupby('Year')['Whole year'].count() / df_air.groupby('Year')['Whole year'].count()

(4) 若某机场至少存在 5 年或以上满足所有月运量记录都为 0,则将其所有
年份的记录信息从表中删除,并返回处理后的表格
airport_0 = df_air.groupby('Airport coordinates')['Whole year'].apply(lambda x: len(x[x==0])>=5)
list_name = list(airport_0.index)
list_bool = list(airport_0.values)
list_air = []
for i in range(len(list_name)):
if list_bool[i] == False:
list_air.append(list_name[i])
df_air.loc[df_air['Airport coordinates'].isin(list_air)]

(5) 采用一种合理的方式将所有机场划分为东南西北四个分区,并给出 2017
年-2019 年货运总量最大的区域。
import re
df_coor = pd.DataFrame()
df_coor = df_air.loc[df_air['Airport coordinates']!='Not found']
list_long = []
list_lat = []
pattern = re.compile("'(.*)'")
for coor in list(df_coor['Airport coordinates'].values):
long, lat = coor.split(',')
str_re1=pattern.findall(long)
str_re2=pattern.findall(lat)
list_long.append(float(str_re1[0]))
list_lat.append(float(str_re2[0]))
df_coor['longtitude'] = list_long
df_coor['latitude'] = list_lat
list_long.sort()
list_lat.sort()
# 根据观测结果得经度在0可划分,维度在60可划分
list_long = [-180, 0, 180]
list_lat = [0, 60, 90]
df_coor['longtitude'] = pd.cut(df_coor['longtitude'], bins=list_long, labels=['西', '东'])
df_coor['latitude'] = pd.cut(df_coor['latitude'], bins=list_lat, labels=['南', '北'])
df_coor[['longtitude', 'latitude']] = df_coor[['longtitude', 'latitude']].astype(object)
df_coor['direction'] = df_coor['longtitude'] + df_coor['latitude']
df_coor = df_coor.loc[df_coor['Year'].isin([2017, 2018, 2019])]
df_coor.groupby('direction')['Whole year'].sum()
direction
东北 159358.73
东南 2145856.10
西北 86.00
西南 63.00
Name: Whole year, dtype: float64
东南方向最多
(6) 在统计学中常常用秩代表排名,现在规定某个机场某年某个月的秩为该
机场该月在当年所有月份中货运量的排名(例如 *** 机场 19 年 1 月运
量在整个 19 年 12 个月中排名第一,则秩为 1),那么判断某月运量情
况的相对大小的秩方法为将所有机场在该月的秩排名相加,并将这个量
定义为每一个月的秩综合指数,请根据上述定义计算 2016 年 12 个月
的秩综合指数。
df_trace = df_air.loc[(df_air['Year']==2016)&(df_air['Whole year']!=0)]
month_list = df_trace.columns[2:14]
for n in df_trace.index:
month = df_trace.loc[n, month_list].sort_values(ascending=False)
rank = 1
for i in month.index:
df_trace.loc[n, i] = rank
rank += 1
df_trace[month_list].apply(lambda x: x.sum())
三、新冠肺炎在美国的传播
问题
(1) 用 corr() 函数计算县(每行都是一个县)人口与表中最后一天记录日期
死亡数的相关系数。
df_confirm = pd.read_csv(load_path+'美国确证数.csv')
df_death = pd.read_csv(load_path+'美国死亡数.csv')
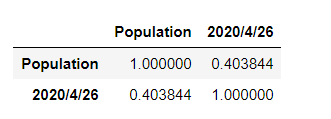
df_corr = pd.DataFrame(df_death[['Population', '2020/4/26']])
df_corr.corr()
(2) 截止到 4 月 1 日,统计每个州零感染县的比例。
df_no_confirm = pd.DataFrame(df_confirm.loc[df_confirm['2020/4/1']== 0])
(df_no_confirm.groupby('Province_State')['UID'].count() / df_confirm.groupby('Province_State')['UID'].count()).fillna(1)

(3) 请找出最早出确证病例的三个县。

(4) 按州统计单日死亡增加数,并给出哪个州在哪一天确诊数增加最大(这
里指的是在所有州和所有天两个指标一起算,不是分别算)。
df_death = pd.read_csv(load_path+'美国死亡数.csv')
end = len(df_death.columns) -1
for i in range(end, 12, -1):
df_death.iloc[:, i] = df_death.iloc[:, i] - df_death.iloc[:, i-1]
df_death_day = df_death.set_index('Province_State').iloc[:, 11:].groupby('Province_State').sum()

df_confirm = pd.read_csv(load_path+'美国确证数.csv')
end = len(df_confirm.columns)-1
for i in range(end, 11, -1):
df_confirm.iloc[:, i] = df_confirm.iloc[:, i] - df_confirm.iloc[:, i-1]
df_confirm_day = df_confirm.set_index('Province_State').iloc[:, 10:].groupby('Province_State').sum()
for i in df_confirm_day.index:
print('{}单日确诊最大的天数为\t\t{}'.format(i, df_confirm_day.loc[i].idxmax(axis=1)))
Alabama单日确诊最大的天数为 2020/4/26
Alaska单日确诊最大的天数为 2020/3/28
Arizona单日确诊最大的天数为 2020/4/23
Arkansas单日确诊最大的天数为 2020/4/23
California单日确诊最大的天数为 2020/4/20
Colorado单日确诊最大的天数为 2020/4/24
Connecticut单日确诊最大的天数为 2020/4/22
Delaware单日确诊最大的天数为 2020/4/26
District of Columbia单日确诊最大的天数为 2020/4/8
Florida单日确诊最大的天数为 2020/4/2
Georgia单日确诊最大的天数为 2020/4/14
Hawaii单日确诊最大的天数为 2020/4/3
Idaho单日确诊最大的天数为 2020/4/2
Illinois单日确诊最大的天数为 2020/4/24
Indiana单日确诊最大的天数为 2020/4/25
Iowa单日确诊最大的天数为 2020/4/25
Kansas单日确诊最大的天数为 2020/4/23
Kentucky单日确诊最大的天数为 2020/4/12
Louisiana单日确诊最大的天数为 2020/4/2
Maine单日确诊最大的天数为 2020/4/2
Maryland单日确诊最大的天数为 2020/4/8
Massachusetts单日确诊最大的天数为 2020/4/24
Michigan单日确诊最大的天数为 2020/4/3
Minnesota单日确诊最大的天数为 2020/4/17
Mississippi单日确诊最大的天数为 2020/4/19
Missouri单日确诊最大的天数为 2020/4/10
Montana单日确诊最大的天数为 2020/4/2
Nebraska单日确诊最大的天数为 2020/4/23
Nevada单日确诊最大的天数为 2020/3/30
New Hampshire单日确诊最大的天数为 2020/4/15
New Jersey单日确诊最大的天数为 2020/4/22
New Mexico单日确诊最大的天数为 2020/4/22
New York单日确诊最大的天数为 2020/4/15
North Carolina单日确诊最大的天数为 2020/4/25
North Dakota单日确诊最大的天数为 2020/4/18
Ohio单日确诊最大的天数为 2020/4/19
Oklahoma单日确诊最大的天数为 2020/4/19
Oregon单日确诊最大的天数为 2020/4/5
Pennsylvania单日确诊最大的天数为 2020/4/23
Rhode Island单日确诊最大的天数为 2020/4/15
South Carolina单日确诊最大的天数为 2020/4/9
South Dakota单日确诊最大的天数为 2020/4/15
Tennessee单日确诊最大的天数为 2020/4/23
Texas单日确诊最大的天数为 2020/4/9
Utah单日确诊最大的天数为 2020/4/10
Vermont单日确诊最大的天数为 2020/4/11
Virginia单日确诊最大的天数为 2020/4/25
Washington单日确诊最大的天数为 2020/4/2
West Virginia单日确诊最大的天数为 2020/4/19
Wisconsin单日确诊最大的天数为 2020/4/25
Wyoming单日确诊最大的天数为 2020/4/21
(5) 现需对每个州编制确证与死亡表,第一列为时间,并且起始时间为该州
开始出现死亡比例的那一天,第二列和第三列分别为确证数和死亡数,
每个州需要保存为一个单独的 csv 文件,文件名为“州名.csv”。
df_confirm = pd.read_csv(load_path+'美国确证数.csv')
df_death = pd.read_csv(load_path+'美国死亡数.csv')
df_confirm_state = df_confirm.set_index('Province_State').iloc[:, 10:].groupby('Province_State').sum().T
df_death_state = df_death.set_index('Province_State').iloc[:, 11:].groupby('Province_State').sum().T
for state in df_confirm_state.columns:
for i in df_confirm_state.index:
if df_death_state.loc[i, state] > 0:
date = i
break
df_save = pd.DataFrame({
'Date':date, 'Cofirm':df_confirm_state.loc['2020/4/26', state], 'Death':df_death_state.loc['2020/4/26', state]}, index=[0])
df_save.to_csv(load_path+state+'.csv')
(6) 现需对 4 月 1 日至 4 月 10 日编制新增确证数与新增死亡数表,第一列
为州名,第二列和第三列分别为新增确证数和新增死亡数,分别保存为
十个单独的 csv 文件,文件名为“日期.csv”。
df_confirm = pd.read_csv(load_path+'美国确证数.csv')
df_death = pd.read_csv(load_path+'美国死亡数.csv')
df_confirm_state = df_confirm.set_index('Province_State').iloc[:, 10:].groupby('Province_State').sum().T
df_death_state = df_death.set_index('Province_State').iloc[:, 11:].groupby('Province_State').sum().T
for state in df_confirm_state.columns:
for i in df_confirm_state.index:
if df_death_state.loc[i, state] > 0:
date = i
break
df_save = pd.DataFrame({
'Date':date, 'Cofirm':df_confirm_state.loc['2020/4/26', state], 'Death':df_death_state.loc['2020/4/26', state]}, index=[0])
df_save.to_csv(load_path+state+'.csv')