package com.imooc.mr;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.SequenceFileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.io.IOException;
/**
* 需求:读取hdfs上的hello.txt文件,计算
*
* 最终需要的结果形式如下:
* hello 2文件中每个单词出现的总次数
* *
* * 原始文件hello.txt内容如下:
* * hello you
* * hello me
* me 1
* you 1
*
* Created by xuwei
*/
public class WordCountJob {
/**
* Map阶段
*/
public static class MyMapper extends Mapper<LongWritable, Text,Text,LongWritable>{
Logger logger = LoggerFactory.getLogger(MyMapper.class);
/**
* 需要实现map函数
* 这个map函数就是可以接收<k1,v1>,产生<k2,v2>
* @param k1
* @param v1
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void map(LongWritable k1, Text v1, Context context)
throws IOException, InterruptedException {
//输出k1,v1的值
//System.out.println("<k1,v1>=<"+k1.get()+","+v1.toString()+">");
//logger.info("<k1,v1>=<"+k1.get()+","+v1.toString()+">");
//k1 代表的是每一行数据的行首偏移量,v1代表的是每一行内容
//对获取到的每一行数据进行切割,把单词切割出来
String[] words = v1.toString().split(" ");
//迭代切割出来的单词数据
for (String word : words) {
//把迭代出来的单词封装成<k2,v2>的形式
Text k2 = new Text(word);
LongWritable v2 = new LongWritable(1L);
//把<k2,v2>写出去
context.write(k2,v2);
}
}
}
/**
* Reduce阶段
*/
public static class MyReducer extends Reducer<Text,LongWritable,Text,LongWritable>{
Logger logger = LoggerFactory.getLogger(MyReducer.class);
/**
* 针对<k2,{v2...}>的数据进行累加求和,并且最终把数据转化为k3,v3写出去
* @param k2
* @param v2s
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void reduce(Text k2, Iterable<LongWritable> v2s, Context context)
throws IOException, InterruptedException {
//创建一个sum变量,保存v2s的和
long sum = 0L;
//对v2s中的数据进行累加求和
for(LongWritable v2: v2s){
//输出k2,v2的值
//System.out.println("<k2,v2>=<"+k2.toString()+","+v2.get()+">");
//logger.info("<k2,v2>=<"+k2.toString()+","+v2.get()+">");
sum += v2.get();
}
//组装k3,v3
Text k3 = k2;
LongWritable v3 = new LongWritable(sum);
//输出k3,v3的值
//System.out.println("<k3,v3>=<"+k3.toString()+","+v3.get()+">");
//logger.info("<k3,v3>=<"+k3.toString()+","+v3.get()+">");
// 把结果写出去
context.write(k3,v3);
}
}
/**
* 组装Job=Map+Reduce
*/
public static void main(String[] args) {
try{
if(args.length!=2){
//如果传递的参数不够,程序直接退出
System.exit(100);
}
//指定Job需要的配置参数
Configuration conf = new Configuration();
//创建一个Job
Job job = Job.getInstance(conf);
//注意了:这一行必须设置,否则在集群中执行的时候是找不到WordCountJob这个类的
job.setJarByClass(WordCountJob.class);
//指定输入路径(可以是文件,也可以是目录)
FileInputFormat.setInputPaths(job,new Path(args[0]));
//指定输出路径(只能指定一个不存在的目录)
FileOutputFormat.setOutputPath(job,new Path(args[1]));
//指定map相关的代码
job.setMapperClass(MyMapper.class);
//指定k2的类型
job.setMapOutputKeyClass(Text.class);
//指定v2的类型
job.setMapOutputValueClass(LongWritable.class);
//指定reduce相关的代码
job.setReducerClass(MyReducer.class);
//指定k3的类型
job.setOutputKeyClass(Text.class);
//指定v3的类型
job.setOutputValueClass(LongWritable.class);
//提交job
job.waitForCompletion(true);
}catch(Exception e){
e.printStackTrace();
}
}
}
编写完代码后,将hadoop-client与log4j在pom中的scope设为provided,表示只在编译阶段使用,打成jar后就不需要了,因为这两个依赖在hadoop集群中已经存在。
选择db_hadoop-1.0-SNAPSHOT-jar-with-dependencies.jar这个jar,将它上传到我们bigdata01的集群节点中
然后写一个数据集
通过该命令执行MR
hadoop jar db_hadoop-1.0-SNAPSHOT-jar-with-dependencies.jar com.imooc.learnmr.WordCountJob /test/hello.txt /out
然后再bigdata01:8088 可以看到该任务的信息
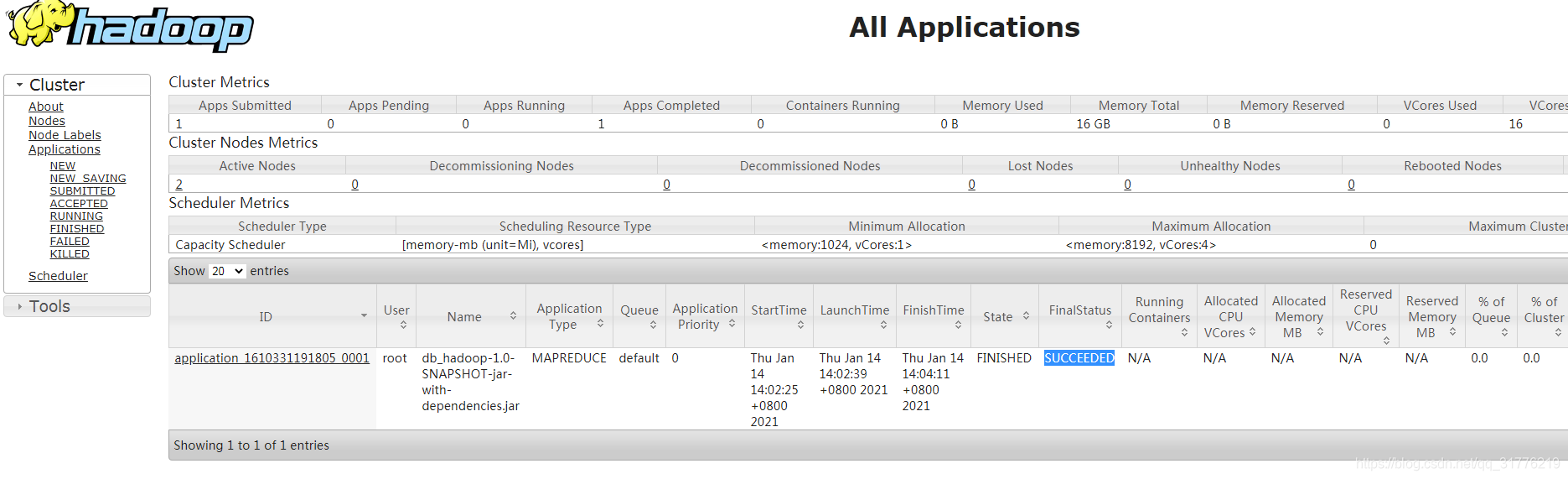
最后通过命令:hdfs dfs -ls /out 查看t输出结果