一、利用Hadoop中自带的hadoop-mapreduce-examples-2.8.5.jar中含有的pi示例计算圆周率
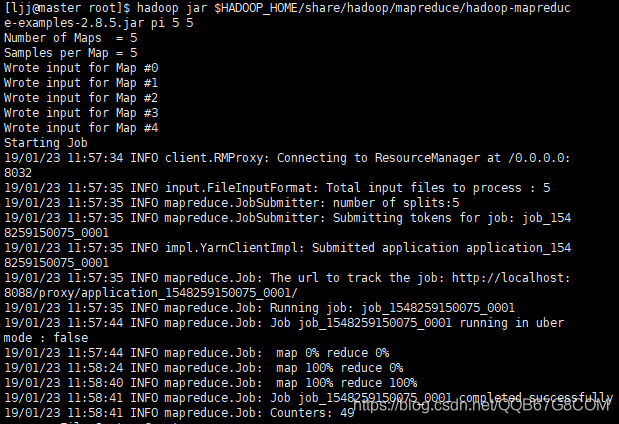
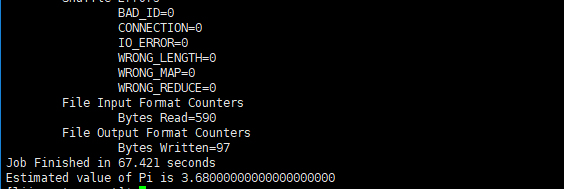
$ hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.8.5.jar pi 5 5
第一个5代表Number of Maps,总共运行10次map任务;Samples per Map则代表每次map任务投掷5次,pi 5 5最后得出的结果是3.68···,当Number of Maps和Samples per Map越大求出的value就越接近π(圆周率)。
二、通过shell利用wordcount示例统计单词数
[ljj@master hadoopeco]$ cd $HADOOP_HOME/temp
[ljj@master temp]$ mkdir file
[ljj@master temp]$ cd file
[ljj@master file]$ echo "Hello World Bye World" > file01.txt
[ljj@master file]$ echo "Hello Hadoop Goodbye Hadoop" > file02.txt
[ljj@master file]$ ls
file01.txt file02.txt
[ljj@master file]$ cat file01.txt
Hello World Bye World
[ljj@master file]$ cat file02.txt
Hello Hadoop Goodbye Hadoop
[ljj@master file]$ hdfs dfs -ls /tmp
Found 3 items
drwx------ - ljj supergroup 0 2019-01-22 15:43 /tmp/hadoop-yarn
drwx-wx-wx - ljj supergroup 0 2019-01-16 19:23 /tmp/hive
drwxr-xr-x - ljj supergroup 0 2019-01-22 15:46 /tmp/tianchi
[ljj@master file]$ hdfs dfs -mkdir /tmp/wc
[ljj@master file]$ hdfs dfs -mkdir /tmp/wc/input
[ljj@master file]$ hdfs dfs -put $HADOOP_HOME/temp/file/file01.txt /tmp/wc/input
[ljj@master file]$ hdfs dfs -put $HADOOP_HOME/temp/file/file02.txt /tmp/wc/input
[ljj@master file]$ hdfs dfs -ls /tmp/wc/input
Found 2 items
-rw-r--r-- 1 ljj supergroup 22 2019-01-23 12:31 /tmp/wc/input/file01.txt
-rw-r--r-- 1 ljj supergroup 28 2019-01-23 12:31 /tmp/wc/input/file02.txt
[ljj@master file]$ hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.8.5.jar wordcount /tmp/wc/input /tmp/wc/output19/01/23 12:34:45 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032
19/01/23 12:34:46 INFO input.FileInputFormat: Total input files to process : 2
19/01/23 12:34:46 INFO mapreduce.JobSubmitter: number of splits:2
19/01/23 12:34:47 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1548259150075_0002
19/01/23 12:34:47 INFO impl.YarnClientImpl: Submitted application application_1548259150075_0002
19/01/23 12:34:47 INFO mapreduce.Job: The url to track the job: http://localhost:8088/proxy/application_1548259150075_0002/
19/01/23 12:34:47 INFO mapreduce.Job: Running job: job_1548259150075_0002
19/01/23 12:34:54 INFO mapreduce.Job: Job job_1548259150075_0002 running in uber mode : false
19/01/23 12:34:54 INFO mapreduce.Job: map 0% reduce 0%
19/01/23 12:35:00 INFO mapreduce.Job: map 100% reduce 0%
19/01/23 12:35:05 INFO mapreduce.Job: map 100% reduce 100%
19/01/23 12:35:05 INFO mapreduce.Job: Job job_1548259150075_0002 completed successfully
19/01/23 12:35:06 INFO mapreduce.Job: Counters: 49
(略一部分)
[ljj@master file]$ hdfs dfs -ls /tmp/wc
Found 2 items
drwxr-xr-x - ljj supergroup 0 2019-01-23 12:31 /tmp/wc/input
drwxr-xr-x - ljj supergroup 0 2019-01-23 12:35 /tmp/wc/output
[ljj@master file]$ hdfs dfs -ls /tmp/wc/output
Found 2 items
-rw-r--r-- 1 ljj supergroup 0 2019-01-23 12:35 /tmp/wc/output/_SUCCESS
-rw-r--r-- 1 ljj supergroup 41 2019-01-23 12:35 /tmp/wc/output/part-r-00000
[ljj@master file]$ hdfs dfs -cat /tmp/wc/output/*
Bye 1
Goodbye 1
Hadoop 2
Hello 2
World 2
三、关于MapReduce的输入AND输出
Map/Reduce框架运转在<key, value> 键值对上,也就是说, 框架把作业的输入看为是一组<key, value> 键值对,同样也产出一组 <key, value> 键值对做为作业的输出,这两组键值对的类型可能不同。
框架需要对key和value的类(classes)进行序列化操作, 因此,这些类需要实现 Writable接口。 另外,为了方便框架执行排序操作,key类必须实现 WritableComparable接口。
一个Map/Reduce 作业的输入和输出类型如下所示:
(input) <k1, v1> -> map -> <k2, v2> -> combine -> <k2, v2> -> reduce -> <k3, v3> (output)
四、官方栗子:WordCount v1.0
WordCount是一个简单的应用,它可以计算出指定数据集中每一个单词出现的次数。
这个应用适用于 单机模式, 伪分布式模式 或 完全分布式模式 三种Hadoop安装方式。
异常解决:
org.apache.hadoop.security.AccessControlException: Permission denied: user=Administrator, access=WRITE, inode="/tmp/wc":ljj:supergroup:drwxr-xr-x
at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.check(FSPermissionChecker.java:318)
at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkPermission(FSPermissionChecker.java:219)
at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkPermission(FSPermissionChecker.java:189)
at org.apache.hadoop.hdfs.server.namenode.FSDirectory.checkPermission(FSDirectory.java:1663)
at org.apache.hadoop.hdfs.server.namenode.FSDirectory.checkPermission(FSDirectory.java:1647)
at org.apache.hadoop.hdfs.server.namenode.FSDirectory.checkAncestorAccess(FSDirectory.java:1606)
at org.apache.hadoop.hdfs.server.namenode.FSDirMkdirOp.mkdirs(FSDirMkdirOp.java:60)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.mkdirs(FSNamesystem.java:3041)
at org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.mkdirs(NameNodeRpcServer.java:1079)
at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolServerSideTranslatorPB.mkdirs(ClientNamenodeProtocolServerSideTranslatorPB.java:652)
at org.apache.hadoop.hdfs.protocol.proto.ClientNamenodeProtocolProtos$ClientNamenodeProtocol$2.callBlockingMethod(ClientNamenodeProtocolProtos.java)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:447)
at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:989)
at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:850)
at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:793)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1844)
at org.apache.hadoop.ipc.Server$Handler.run(Server.java:2489)
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
at java.lang.reflect.Constructor.newInstance(Constructor.java:423)
at org.apache.hadoop.ipc.RemoteException.instantiateException(RemoteException.java:121)
at org.apache.hadoop.ipc.RemoteException.unwrapRemoteException(RemoteException.java:88)
at org.apache.hadoop.hdfs.DFSClient.primitiveMkdir(DFSClient.java:2474)
at org.apache.hadoop.hdfs.DFSClient.mkdirs(DFSClient.java:2447)
at org.apache.hadoop.hdfs.DistributedFileSystem$25.doCall(DistributedFileSystem.java:1159)
at org.apache.hadoop.hdfs.DistributedFileSystem$25.doCall(DistributedFileSystem.java:1156)
at org.apache.hadoop.fs.FileSystemLinkResolver.resolve(FileSystemLinkResolver.java:81)
at org.apache.hadoop.hdfs.DistributedFileSystem.mkdirsInternal(DistributedFileSystem.java:1156)
at org.apache.hadoop.hdfs.DistributedFileSystem.mkdirs(DistributedFileSystem.java:1148)
at org.apache.hadoop.fs.FileSystem.mkdirs(FileSystem.java:1914)
at org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter.setupJob(FileOutputCommitter.java:343)
at org.apache.hadoop.mapred.LocalJobRunner$Job.run(LocalJobRunner.java:538)
Caused by: org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.security.AccessControlException): Permission denied: user=Administrator, access=WRITE, inode="/tmp/wc":ljj:supergroup:drwxr-xr-x
at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.check(FSPermissionChecker.java:318)
at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkPermission(FSPermissionChecker.java:219)
at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkPermission(FSPermissionChecker.java:189)
at org.apache.hadoop.hdfs.server.namenode.FSDirectory.checkPermission(FSDirectory.java:1663)
at org.apache.hadoop.hdfs.server.namenode.FSDirectory.checkPermission(FSDirectory.java:1647)
at org.apache.hadoop.hdfs.server.namenode.FSDirectory.checkAncestorAccess(FSDirectory.java:1606)
at org.apache.hadoop.hdfs.server.namenode.FSDirMkdirOp.mkdirs(FSDirMkdirOp.java:60)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.mkdirs(FSNamesystem.java:3041)
at org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.mkdirs(NameNodeRpcServer.java:1079)
at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolServerSideTranslatorPB.mkdirs(ClientNamenodeProtocolServerSideTranslatorPB.java:652)
at org.apache.hadoop.hdfs.protocol.proto.ClientNamenodeProtocolProtos$ClientNamenodeProtocol$2.callBlockingMethod(ClientNamenodeProtocolProtos.java)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:447)
at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:989)
at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:850)
at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:793)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1844)
at org.apache.hadoop.ipc.Server$Handler.run(Server.java:2489)
at org.apache.hadoop.ipc.Client.getRpcResponse(Client.java:1489)
at org.apache.hadoop.ipc.Client.call(Client.java:1435)
at org.apache.hadoop.ipc.Client.call(Client.java:1345)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:227)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:116)
at com.sun.proxy.$Proxy14.mkdirs(Unknown Source)
at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolTranslatorPB.mkdirs(ClientNamenodeProtocolTranslatorPB.java:583)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.hadoop.io.retry.RetryInvocationHandler.invokeMethod(RetryInvocationHandler.java:409)
at org.apache.hadoop.io.retry.RetryInvocationHandler$Call.invokeMethod(RetryInvocationHandler.java:163)
at org.apache.hadoop.io.retry.RetryInvocationHandler$Call.invoke(RetryInvocationHandler.java:155)
at org.apache.hadoop.io.retry.RetryInvocationHandler$Call.invokeOnce(RetryInvocationHandler.java:95)
at org.apache.hadoop.io.retry.RetryInvocationHandler.invoke(RetryInvocationHandler.java:346)
at com.sun.proxy.$Proxy15.mkdirs(Unknown Source)
at org.apache.hadoop.hdfs.DFSClient.primitiveMkdir(DFSClient.java:2472)
... 9 more
19/01/25 00:20:52 INFO mapreduce.Job: Job job_local1430700062_0001 running in uber mode : false
19/01/25 00:20:52 INFO mapreduce.Job: map 0% reduce 0%
19/01/25 00:20:52 INFO mapreduce.Job: Job job_local1430700062_0001 failed with state FAILED due to: NA
19/01/25 00:20:52 INFO mapreduce.Job: Counters: 0
四、官方示例
package persion.ljj.example
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import com.google.gson.Gson;
public class WordCount {
/**
* 定义Map内部类实现字符串分解
*
* Mapper<keyin, valuein, keyout, valueout>
* JDK自带的基本类型序列化效率低,Hadoop自定义了一套序列化框架
*
* Long ---> LongWritable
* String ---> Text
* Integer ---> IntWritable
* Null ---> NullWritable
*/
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable>
{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
//实现map()函数
public void map(Object key, Text value, Context context) throws IOException, InterruptedException
{
//将字符串拆分成单词
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken()); //将分解后的一个单词写入word类
context.write(word, one); //手机<key, value>
}
}
}
//定义Reduce内部类规约同一key的value
public static class IntSumReducer extends Reducer<Text,IntWritable,Text,IntWritable>
{
private IntWritable result = new IntWritable();
//实现reduce()函数
public void reduce(Text key, Iterable<IntWritable> values,Context context) throws IOException, InterruptedException {
int sum = 0;
//遍历迭代器values,得到同一key的所有value
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);//产生输出对<key,result>
}
}
public static void main(String[] args) throws Exception {
//为任务设定配置文件
Configuration conf = new Configuration();
//hadoop中的一次计算任务成为Job,面函数主要负责新建一个job对象并为之设定相应的mapper和reducer类,以及输入、输出路径
Job job = Job.getInstance(conf, "word count");//新建一个用户定义的Job
job.setJarByClass(WordCount.class);//设置执行任务的jar
job.setMapperClass(TokenizerMapper.class);//设置Mapper类
job.setCombinerClass(IntSumReducer.class);//设置combine类
job.setReducerClass(IntSumReducer.class);//设置reducer类
job.setOutputKeyClass(Text.class);//设置job输出的key
job.setOutputValueClass(IntWritable.class);//设置job输出的值
FileInputFormat.addInputPath(job, new Path("hdfs://master:8020/tmp/wc/input"));//设置输入文件路径
FileOutputFormat.setOutputPath(job, new Path("hdfs://master:8020/tmp/wc/output3"));//设置输出文件路径
System.exit(job.waitForCompletion(true) ? 0 : 1);//提交任务等待完成
}
}
更进一步的请看:十六、Hadoop之Java手动编写Map/Reduce
参考:Hadoop官方中文文档