一、源数据格式
user_id,item_id,behavior_type,user_geohash,item_category,time
其中behavior_type为行为类型,具体表示为:
1.浏览 2.收藏 3.加入购入车 4.购买
前十行数据展示:
user_id,item_id,behavior_type,user_geohash,item_category,time
10001082,285259775,1,97lk14c,4076,2014-12-08 18
10001082,4368907,1,,5503,2014-12-12 12
10001082,4368907,1,,5503,2014-12-12 12
10001082,53616768,1,,9762,2014-12-02 15
10001082,151466952,1,,5232,2014-12-12 11
10001082,53616768,4,,9762,2014-12-02 15
10001082,290088061,1,,5503,2014-12-12 12
10001082,298397524,1,,10894,2014-12-12 12
10001082,32104252,1,,6513,2014-12-12 12二、任务要求
(1)计算2014年12月份购买过产品的人数
(2)计算2014年12月份产品总浏览数
(3)计算2014年12月份每一类产品的浏览次数
三、具体实现
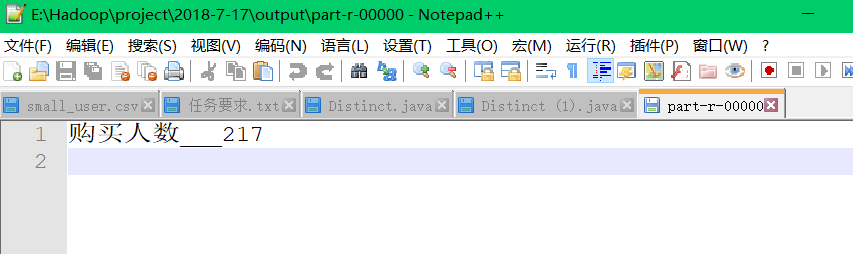
(1)计算2014年12月份购买过产品的人数
关键代码如下:
String[]str=value.toString().split(",");
if(str[5].length()>=7) {
if(str[2].equals("4")&&str[5].substring(0, 7).equals("2014-12")){
k.set(str[0]);
context.write(k,NullWritable.get());
}
}计算结果为:
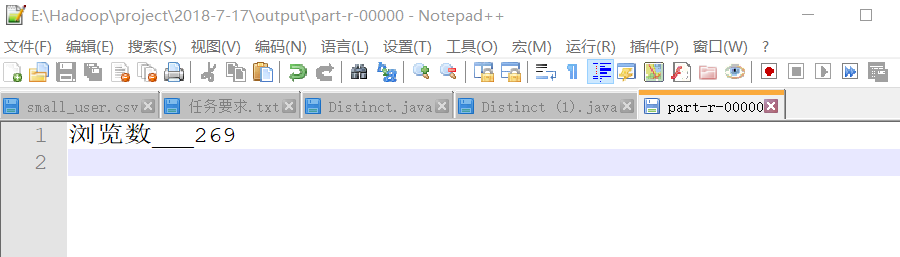
(2)计算2014年12月份产品总浏览数
关键代码如下:
if(str[5].length()>=7) { //第二问
if(str[2].equals("1")&&str[5].substring(0, 7).equals("2014-12")){
k.set(str[0]);
context.write(k,NullWritable.get());
}
}计算结果为:
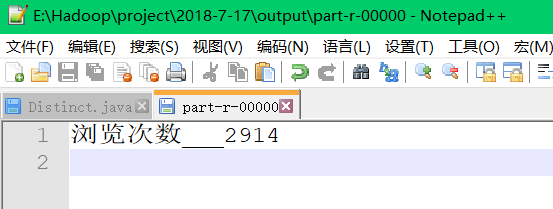
(3)计算2014年12月份每一类产品的浏览次数
关键代码如下:
String[]str=value.toString().split(",");
if(str[5].length()>=7) { //第三问
if(str[2].equals("1")&&str[5].substring(0, 7).equals("2014-12")){
k.set(str[4]);
context.write(k,NullWritable.get());
}
}计算结果为:
附录:完整源代码
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.Job;
public class Distinct2 {
static class DistinctMapper extends Mapper<LongWritable, Text, Text, NullWritable>{
Text k=new Text();
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, NullWritable>.Context context)
throws IOException, InterruptedException {
if(key.get()==0) { //去除第一行的表头
return;
}
String[]str=value.toString().split(",");
if(str[5].length()>=7) { //第一问
if(str[2].equals("4")&&str[5].substring(0, 7).equals("2014-12")){
k.set(str[0]);
context.write(k,NullWritable.get());
}
}
/*if(str[5].length()>=7) { //第二问
if(str[2].equals("1")&&str[5].substring(0, 7).equals("2014-12")){
k.set(str[0]);
context.write(k,NullWritable.get());
}
}*/
/* if(str[5].length()>=7) { //第三问
if(str[2].equals("1")&&str[5].substring(0, 7).equals("2014-12")){
k.set(str[4]);
context.write(k,NullWritable.get());
}
}*/
}
}
static class DistinctReduce extends Reducer<Text, NullWritable, Text, NullWritable>{
long sum=0;
@Override
protected void reduce(Text key, Iterable<NullWritable> values,
Reducer<Text, NullWritable, Text, NullWritable>.Context context) throws IOException, InterruptedException {
sum++;
}
@Override
protected void cleanup(Reducer<Text, NullWritable, Text, NullWritable>.Context context)
throws IOException, InterruptedException {
context.write(new Text("购买人数___"+sum), NullWritable.get());
}
}
public static void main(String[] args) throws Exception{
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJobName("distinct");
job.setMapperClass(DistinctMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(NullWritable.class);
job.setReducerClass(DistinctReduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
FileInputFormat.addInputPath(job, new Path("E:\\Hadoop\\project\\2018-7-17\\input"));
FileSystem fs = FileSystem.get(conf);
if(fs.exists(new Path("E:\\Hadoop\\project\\2018-7-17\\output"))) {
fs.delete(new Path("E:\\Hadoop\\project\\2018-7-17\\output"),true);
}
FileOutputFormat.setOutputPath(job, new Path("E:\\Hadoop\\project\\2018-7-17\\output"));
job.setJarByClass(Distinct2.class);
boolean flag = job.waitForCompletion(true);
if(flag) {
System.out.println("Finished!");
}
}
}
