- 分布式锁
- 基于数据库实现分布式锁
- 基于缓存Redis实现分布式锁
- Redisson
- 基于Zookeeper实现分布式锁
1. 数据库实现
(1)悲观锁实现:利用select … where … for update 加排他锁,业务处理完再用commit()释放锁
- 注:要注意行锁转换成表锁的问题
- InnoDB引擎在加锁的时候,只有通过索引进行检索的时候才会使用行级锁,否则会使用表级锁。这里我们希望使用行级锁,就要给method_name添加索引,值得注意的是,这个索引一定要创建成唯一索引,否则会出现多个重载方法之间无法同时被访问的问题。重载方法的话建议把参数类型也加上
- 存在问题和解决方式
- 阻塞问题:无需while()循环,for update语句会在执行成功后立即返回,在执行失败时一直处于阻塞状态,直到成功
- 服务宕机:使用这种方式,服务宕机之后数据库会自己把锁释放掉,无需担心
(2)乐观锁实现:CAS,利用唯一性约束insert加锁,delete解锁
- 加锁:
-
insert into methodLock(method_name,desc) values (‘method_name’,‘desc’)
-
- 解锁:
-
delete from methodLock where method_name ='method_name'
-
- 对method_name做唯一性约束,这里如果有多个请求同时提交到数据库的话,数据库会保证只有一个操作可以成功
- 存在问题和解决方式
- 单点问题:这把锁强依赖数据库的可用性,数据库是一个单点,一旦数据库挂掉,会导致业务系统不可用 ——> 主备模式解决
- 可能死锁:这把锁没有失效时间,一旦解锁操作失败,就会导致锁记录一直在数据库中,其他线程无法再获得到锁 ——> 做一个定时任务,每隔一定时间把数据库中的超时数据清理一遍
- 非阻塞锁:数据的insert操作,一旦插入失败就会直接报错。没有获得锁的线程并不会进入排队队列,要想再次获得锁就要再次触发获得锁操作 ——> while循环,直到insert成功再返回成功
- 不可重入:这把锁是非重入的,同一个线程在没有释放锁之前无法再次获得该锁。因为数据中数据已经存在了 ——> 在数据库表中加个字段,记录当前获得锁的机器的主机信息和线程信息,那么下次再获取锁的时候先查询数据库,如果当前机器的主机信息和线程信息在数据库可以查到的话,直接把锁分配给他就可以了
- 不可解决的问题:
- select for update是否加行锁不确定:MySql会对查询进行优化,即便在条件中使用了索引字段,但是否使用索引来检索数据是由 MySQL 通过判断不同执行计划的代价来决定的
- 排他锁来进行分布式锁的lock,那么一个排他锁长时间不提交,就会占用数据库连接。一旦类似的连接变得多了,就可能把数据库连接池撑爆
(3)总结
- 优点
- 用以实现,简单易懂
- 缺点
- 数据库开销,性能影响大
- 数据库的行级锁并不一定靠谱,尤其是当我们的锁表并不大的时候
- 会有各种各样的问题,在解决问题的过程中会使整个方案变得越来越复杂
2. Redis实现
- 涉及命令
- SETNX key val:当且仅当key不存在时,set一个key为val的字符串,返回1;若key存在,则什么都不做,返回0
- expire key timeout:为key设置一个超时时间,单位为second,超过这个时间锁会自动释放,避免死锁
- delete key:删除key
- 核心思想:key=lock, value=uuid();每次先用SETNX尝试拿锁,如果key不存在说明可以加锁;如果key不存在说明已经加了锁了,再通过uuid()判断是不是自己的可重入锁
- 由于需要保证原子性,通过lua脚本:
-
LUA_SCRIPT = "if redis.call('get', KEYS[1]) == ARGV[1] then return redis.call('del', KEYS[1]) else return 0 end";
(1)Redisson:开源库(Ref:https://blog.csdn.net/shuangyueliao/article/details/89344256)
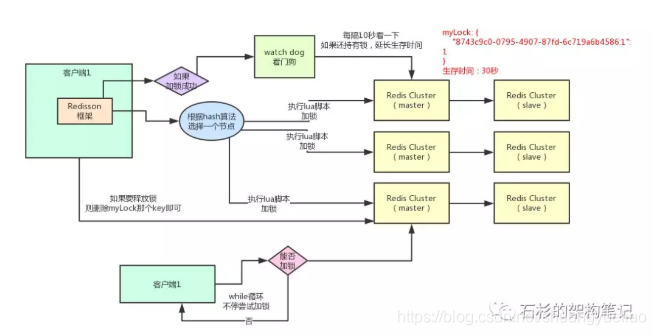
- Client1加锁:LUA脚本
- Client1生成uuid,并加锁(hash数据结构):hset myLock 8743c9c0-0795-4907-87fd-6c719a6b4586:1 1
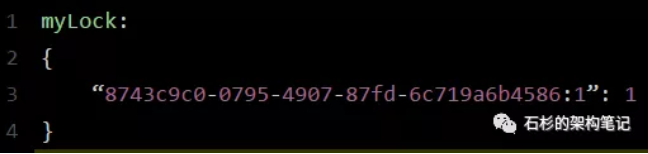
- 上述就代表“8743c9c0-0795-4907-87fd-6c719a6b4586:1”这个客户端对“myLock”这个锁key完成了加锁
- 接着会执行“pexpire myLock 30000”命令,设置myLock这个锁key的生存时间是30秒
- Client2尝试加锁,加锁失败
- 首先判断exists myLock,锁已经存在
- 其次判断是否是自己的可重入锁:uuid()不一样,不是的
- 最后获取到pttl myLock返回的一个数字,这个数字代表了myLock这个锁key的剩余生存时间
- while()循环,不停CAS尝试加锁
- watch dog自动延期机制
- Client1加锁的锁key默认生存时间才30秒,如果超过了30秒,客户端1还想一直持有这把锁,怎么办呢
- Client1一旦加锁成功,就会启动一个watch dog看门狗,他是一个后台线程,会每隔10秒检查一下,如果客户端1还持有锁key,那么就会不断的延长锁key的生存时间
- Client1继续加锁:可重入锁
- 首先判断exists myLock,锁已经存在
- 其次判断是否是自己的可重入锁:uuid()一样,可重入锁
- 对这个hash的value+1,表示可重入次数
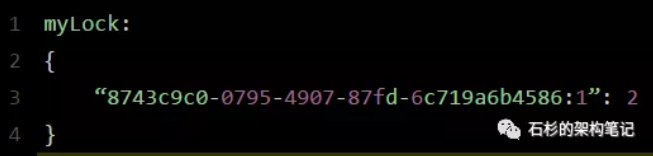
- 释放锁
- 当解锁时,对value-1,如果发现是0,则del MyLock,释放锁
- 缺点:在redis master实例宕机的时候,可能导致多个客户端同时完成加锁
- 过程中一旦发生redis master宕机,主备切换,redis slave变为了redis master
- 客户端2来尝试加锁的时候,在新的redis master上完成了加锁,而客户端1也以为自己成功加了锁
- 此时就会导致多个客户端对一个分布式锁完成了加锁,导致各种脏数据的产生
3. Zookeeper实现
- 大致思想:每个客户端对某个方法加锁时,在zookeeper上的与该方法对应的指定节点的目录下,生成一个唯一的瞬时有序节点。 判断是否获取锁的方式很简单,只需要判断有序节点中序号最小的一个。 当释放锁的时候,只需将这个瞬时节点删除即可。同时,其可以避免服务宕机导致的锁无法释放,而产生的死锁问题
4. 总结
- 从理解的难易程度角度(从低到高):数据库 > 缓存 > Zookeeper
- 从实现的复杂性角度(从低到高):Zookeeper >= 缓存 > 数据库
- 从性能角度(从高到低):缓存 > Zookeeper >= 数据库
- 从可靠性角度(从高到低):Zookeeper > 缓存 > 数据库
Ref
http://www.hollischuang.com/archives/1716
https://blog.csdn.net/qq_35620501/article/details/95047642
https://www.cnblogs.com/barrywxx/p/11644803.html
Redisson:https://blog.csdn.net/shuangyueliao/article/details/89344256