目录
前言
在机器学习中,肯定要用到各种各样的数据集,记录一下自己可视化Pascal VOC数据集的方法,参考资料为pytorch官方实现的方法
一、VOC数据集
可以从这个链接去下载VOC的数据集:Pascal VOC 官网
一般从网上下载下来的VOC数据集的格式如下

1.其中Annotations中为记录图像和标签信息的xml文件,简单看一下xml文件中的内容。

可以看到xml文件中包含了图像的长宽信息,里面标注物体的类别,boundingbox的左上角和右下角坐标等等。我们等会使用的函数会自动帮助我们处理xml中的这些树形结构
2.ImageSets中主要包含的是划分的训练集和测试集中图片的名称
3.JPEGImages中就是数据集的原始图片
4.labels中就是对应图片中的boundingbox和其类别

二、读取VOC数据集
这里我们主要使用的是pytorch官方读取VOC格式提供的代码
主要使用datasets库里的VOCDetection方法。
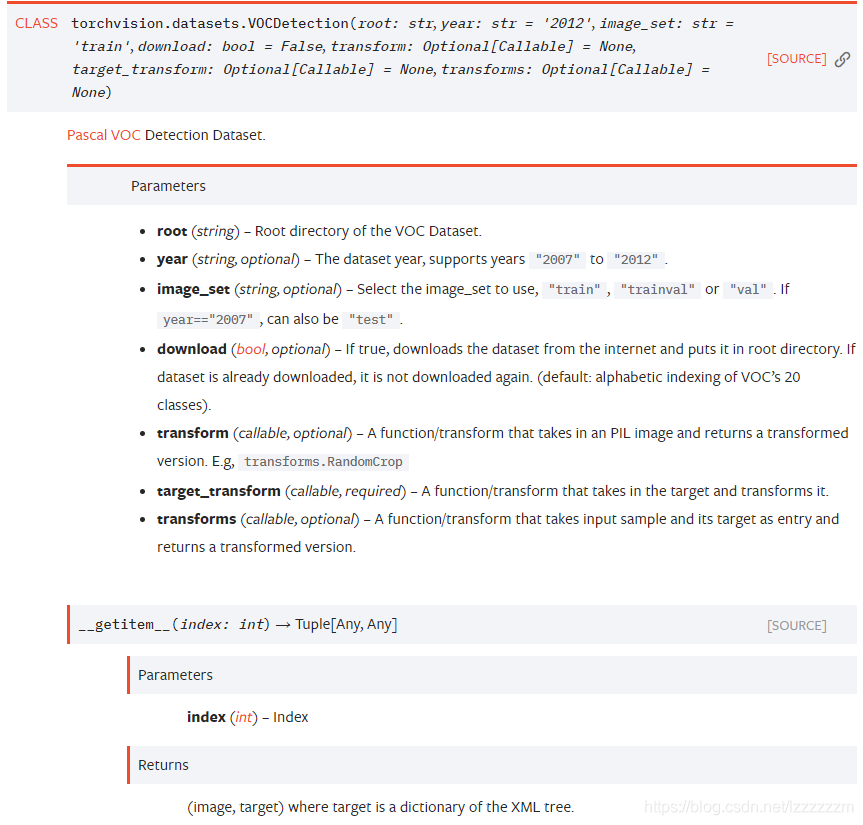
| 参数 | 含义 |
| root | VOC数据集的路径 |
| year | 哪年的VOC数据集 |
| image_set | 此数据为训练集还是测试集 |
| download | 是否要从网上下载 |
| transform | 图像的变化 |
| target_transfrom | 标签的变化 |
利用这个函数我们就可以对此数据集进行读取了,而其返回值,是一个可枚举类型,我们枚举其,得到我们需要的数据。
import numpy as np
import torchvision.datasets as datasets
import cv2 as cv
# 画框标注函数
def draw_box(image, boxes, classes, scores, line_thickness=3):
cv.rectangle(image, (int(boxes['xmin']), int(boxes['ymin'])), (int(boxes['xmax']), int(boxes['ymax'])),
(255, 0, 0), line_thickness)
cv.putText(image, classes, (int(boxes['xmin']), int(boxes['ymin'])), cv.FONT_HERSHEY_COMPLEX,
0.5, (255, 0, 0), 2)
def main():
data_path = "./data" # 数据集路径
voc_train = datasets.VOCDetection(data_path, year="2007", image_set="train")
for index, target in enumerate(voc_train):
image, label = target[0], target[1]
object = label['annotation']['object']
image = cv.cvtColor(np.array(image), cv.COLOR_RGB2BGR) # 转成向量,可以显示,opencv默认位BGR
for index in range(len(object)):
class_name, bndbox = object[index]['name'], object[index]['bndbox']
draw_box(image, bndbox, class_name, 1)
cv.imshow('image', image)
cv.waitKey()
if __name__ == "__main__":
main()
输出结果
