数据清洗-表格合并并添加时间戳
提取文件名字
读取指定类型文件名字
分离文件名字
names = os.listdir(path)
for name in names:
index = name.rfind('.')
name = name[:index]
print(name)
flag = name.split('_')
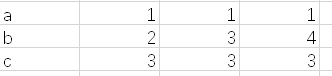
原始表格如上图所示,无表头
对表格增加列,并将指定信息写入列中
定义表头
合并表格
总程序:
import os
import pandas as pd
path = os.getcwd()
names = os.listdir(path)
for name in names:
index = name.rfind('.')
csv = name[index:]
if(csv =='.csv'): #由于文件夹中有其他文件,进行筛选,否则转化为dataframe时报错
df = pd.read_csv(name,header=None,names=['temp','tempavg','tempmax','tempmin'])# 注意这里增加表头的方式!!
# df.columns=['temp','tempavg','tempmax','tempmin'] #增加表头,否则下一步添加列时不方便
name_new = name[:index]
flag = name_new.split('_')
print(flag)
time = flag[2]
series = flag[1]
df['time'] = time
df['series'] = series
df.to_csv(name,index=False) #保存更改,注意不需要自动添加索引!
for name in names:
index = name.rfind('.')
csv = name[index:]
if(csv =='.csv'): #由于文件夹中有其他文件,进行筛选,否则转化为dataframe时报错
print(csv)
df = pd.read_csv(name)
df.to_csv('allok.csv',encoding="utf_8_sig",header=False,index=False,mode='a+')
df = pd.read_csv('allok.csv',header=None,names=['temp','tempavg','tempmax','tempmin','time','series'])# 定义合并好的表格名字
df.to_csv('allok.csv',index=True)
index索引问题
针对默认添加的索引不是从1开始
df.index = np.arange(1, len(df))
导出数据过长变成科学计数法

由于导出的数据过长,变成了科学计数法;导致后面在合并表格时四舍五入了…
因此加入df['time'] = str(time)+'\t'

成功解决!
合并表格升级(特征行列展开合并)
原表格样式:(需要合并几万个专业个这样的表格)

合并后成为了每个参数的均值、最值分开的总表
path = os.getcwd()
names = os.listdir(path)
i = 0
for name in names:
index = name.rfind('.')
csv = name[index:]
if(csv =='.csv'): #由于文件夹中有其他文件,进行筛选,否则转化为dataframe时报错
df = pd.read_csv(name)
for index,row in df.iterrows():
feature_name = row[0]
feature_avg = feature_name+'_avg'
feature_min = feature_name+'_min'
feature_max = feature_name+'_max'
df[feature_avg] = str(row[1])+'\t'
df[feature_max] = str(row[2])+'\t'
df[feature_min] = str(row[3])+'\t'#防止科学计数
data =df.iloc[:1,4:] #定位表格
if(i == 0):
data.to_csv('gather_operate.csv',encoding="utf_8_sig",header =True,index = False ,mode='a+')
else:
data.to_csv('gather_operate.csv',encoding="utf_8_sig",header =False,index = False ,mode='a+')
i=i+1
提取文件名字到表格,并保存到父目录
import os,sys
import xlwt
path = os.getcwd()
dirs = os.listdir(path)
write =xlwt.Workbook()
sheet = write.add_sheet('sheet_name')
i = 0
for file in dirs:
if os.path.splitext(file)[1]=='.csv':
sheet.write(i,0,file)
i+=1
print(i)
write.save('../file_name.xls')
pandas写入csv格式文件出现中文乱码
df.to_csv("cnn_predict_result.csv",encoding="utf_8_sig")
批量合并表格时移植表头
i = 0
for name in names:
index = name.rfind('.')
csv = name[index:]
if(csv =='.csv'): #由于文件夹中有其他文件,进行筛选,否则转化为dataframe时报错
if(i==0):
print("header")
df = pd.read_csv(name)
df.to_csv('特征值数据汇总.csv',encoding="utf_8_sig",header=True,index=False,mode='a+')#拼接第一个表格时保留表头
else:
print(csv)
df = pd.read_csv(name)
df.to_csv('特征值数据汇总.csv',encoding="utf_8_sig",header=False,index=False,mode='a+')
i=i+1
Pandas输出表格字符串过长变为科学计数法
网上那种直接改单元格格式的方法,文件关闭后再打开还是老样子
后来看了一篇文章
df[‘time’]=[’ %i’ % i for i in df[‘time’]]选择要修改的列加入/t,我的理解是加个字符就行
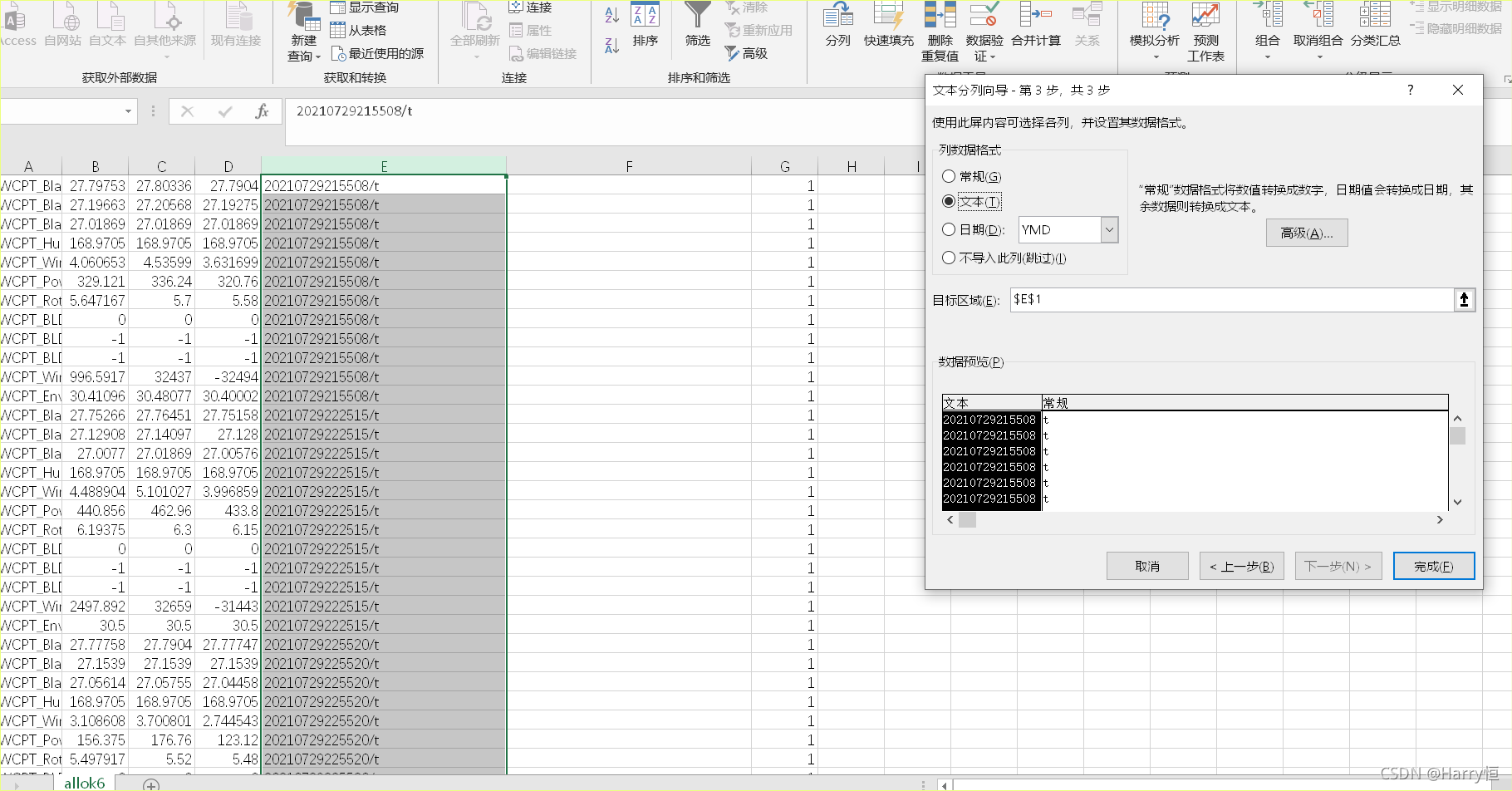
使用Excel 分列