摘要
单位:Korea University
论文
代码(未放出)
传统方法通常使用多尺度输入图像堆叠子网络,并通过从底部子网络到顶部子网络逐渐提升图像的sharpess,这样做不可避免地产生较高的计算成本。本文重新审视了粗粒度到细粒度的策略,提出一个multi-input multi-output U-net (MIMO-UNet). 单个编码器可以接受多个尺度的输入,缓解训练难度;单个解码器可以输出多个尺度的结果;非对称特征融合技术的引入,有效地融合多尺度特征。结果SOTA。

方法
Coarse-to-Fine

以上的4个方法是论文中的Related Work介绍的不同的Corase-to-Fine的方法,感觉图还是很直观的。这些和本文方法的不同之处在于,这些方法在粗粒度到细粒度过度的时候是一种串行的方式,而本文是将不同粒度,也就是尺度,给混合起来。
网络结构
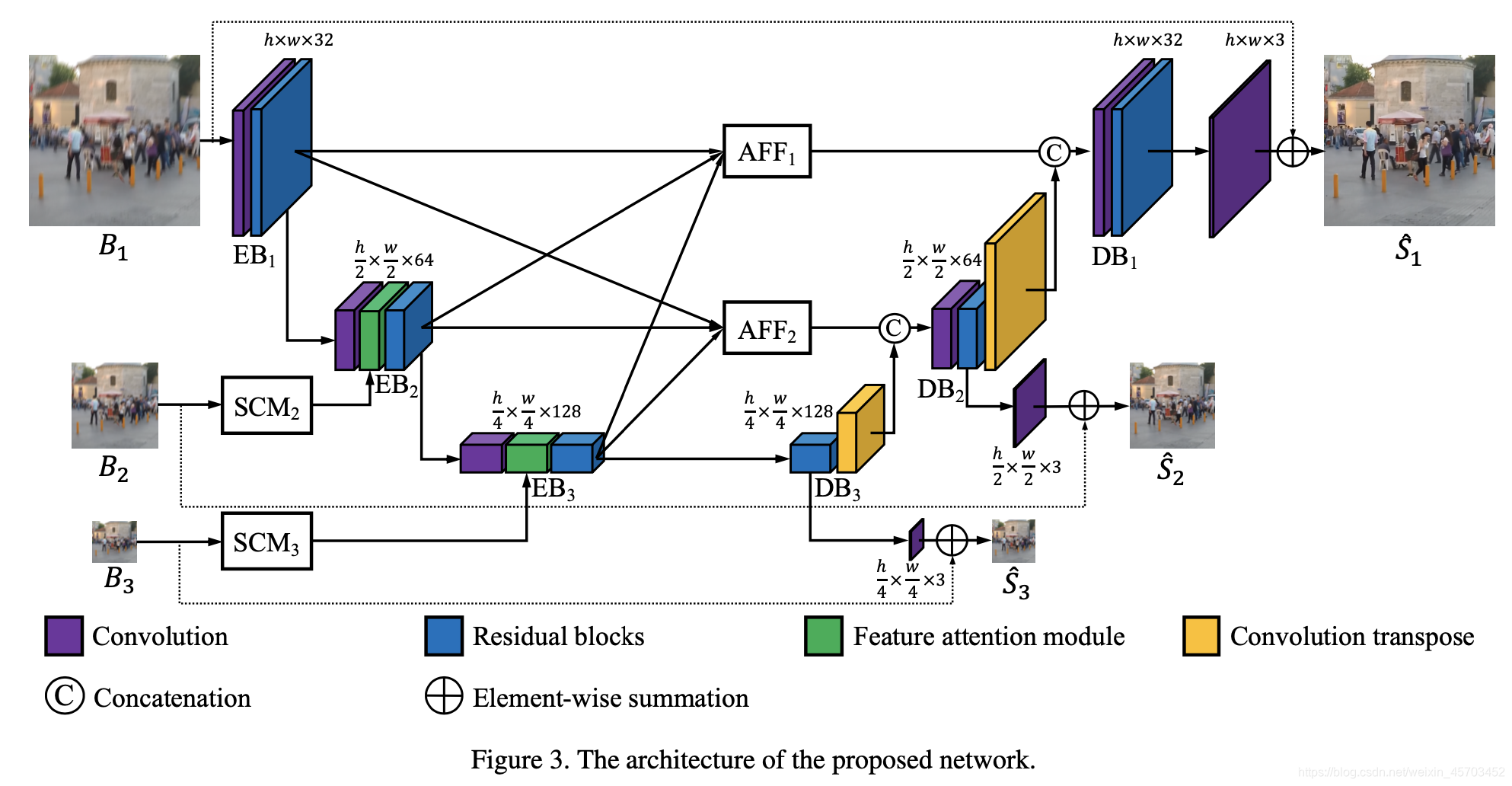
结构也是很明了,如上图所示,多输入多输出,EB是encoder block,DB是decoder block。

上图的各个模块名字起的倒是不错,但是内部实现是平平无奇的。韩国人真会来事[\doge]
ECCV2020的一篇论文是这样做的:

相比之下,不同点在于:
- 本文多输入,实现上是对图像进行多个尺度的resize;而上面这篇论文里是单输入,产生的特征进行多个尺度的resize。
- 本文的特征融合路径是上面论文的一种,即最小尺度的特征的来源只有一条路径,不像其他尺度会融合不同尺度的信息。
- 此外,本文的不同尺度融合有种dense的感觉,比如AFF1前面的特征,都是从不同尺度的Residual Block后获取得到的,而RB之后的特征又会进行下采样得到下一个尺度的信息;上面论文是一种并行结构,融合的特征是尺度上单独的信息。
- 本文多输出,方便构造不同尺度上的残差形式。
因此,本文还是有一些创新的。
loss
在损失上采用内容也就是L1损失;此外用了个FFT变换,在频域做了个损失。
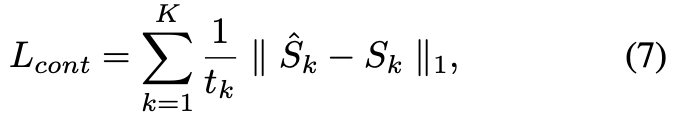

实验
结果
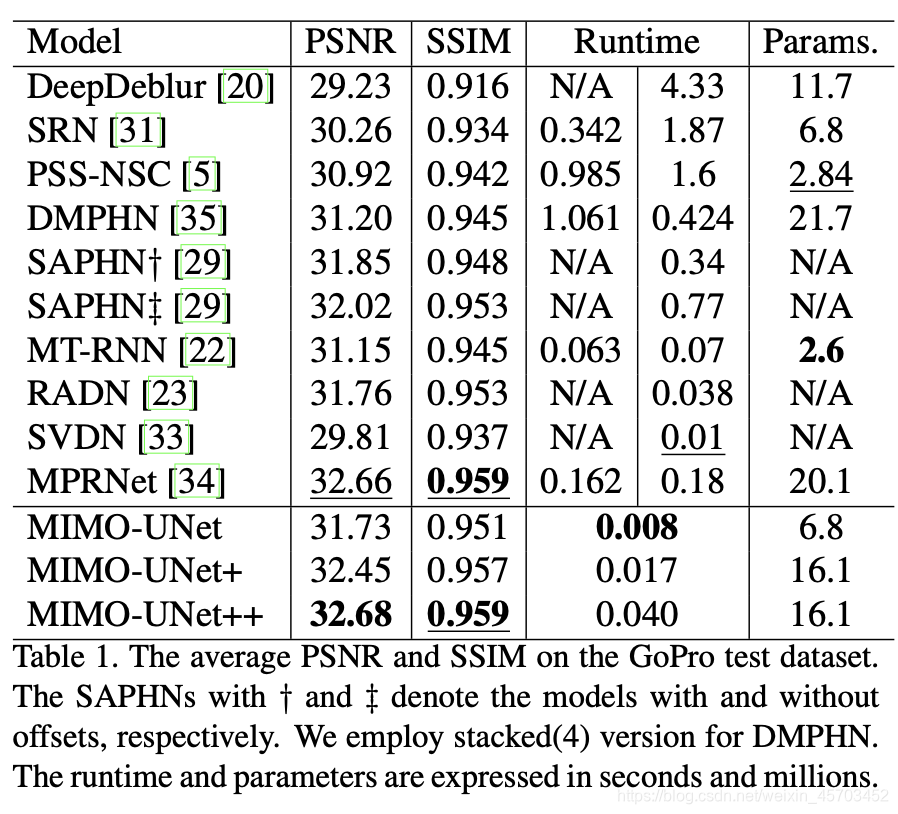
原本是8个编解码结构,+代表的是20个编解码,++代表后者测试时候用self-ensemble。本方法的计算时间不错。
消融实验

multi-input single encoder(MISE)
multi-output single decoder(MOSD)
AFF是Figure4的结构
MSFR是频域损失,这个是我比较关注的,可以看出提升还挺大的。
此外,本文方法上还做了扩展,在目标检测的效果上也好一点,就不放图了。就酱紫,下次再见!