Spark数据读取、处理以及保存
手动反爬虫,禁止转载: 原博地址 https://blog.csdn.net/lys_828/article/details/121204749(CSDN博主:Be_melting)
知识梳理不易,请尊重劳动成果,文章仅发布在CSDN网站上,在其他网站看到该博文均属于未经作者授权的恶意爬取信息
4 数据收集与处理
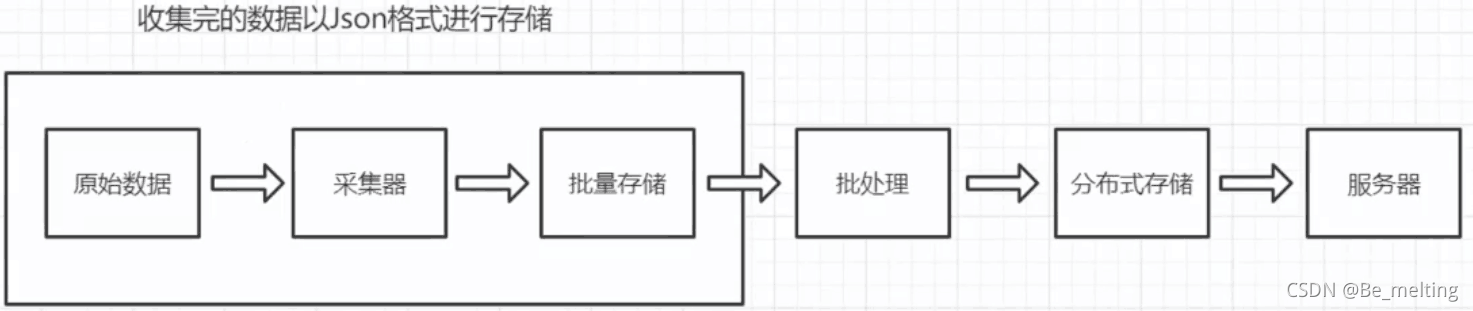
在1.4部分介绍了数据分析金字塔,接下来的内容就是进行一层层阶梯的攀登。首先来进行金字塔底端的数据记录,也就是数据的收集、展示与传递信息,具体要进行的操作就是下图中被框起来的三个部分。
4.1 Spark环境封装
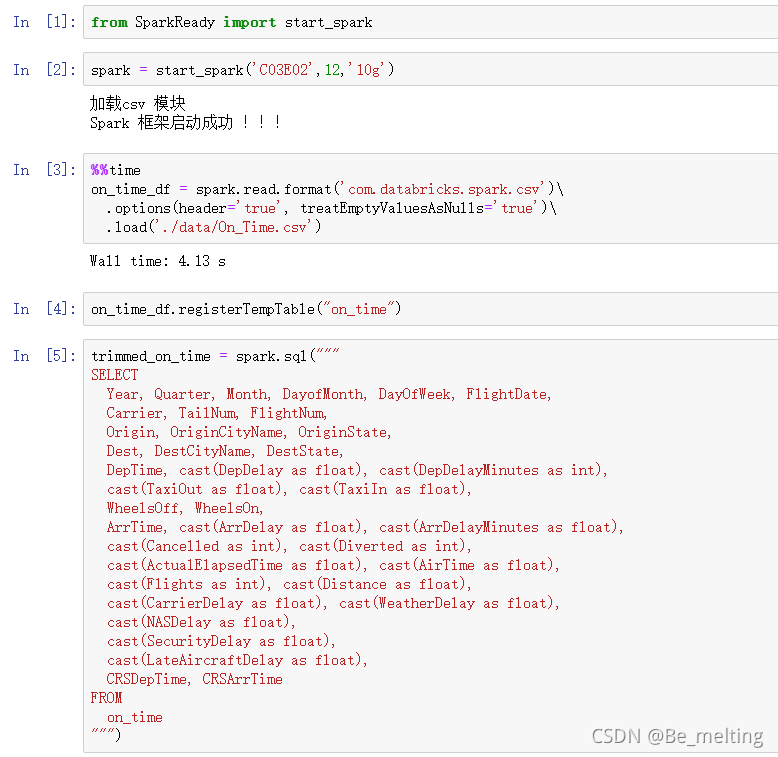
通过前面的测试代码,可以发现每次执行Spark程序时候,最开始就是要输入创建进程的代码,由于此类代码都是一致的,而且再今后的工作生产中会经常使用到Spark,因此在工作开启前,可以把创建Spark进程和读取文件的操作直接封装起来,单独创建一个py文件,后续使用的时候直接调用即可。
首先在准备课程文件夹的同级目录中创建一个step1文件夹,里面新建一个SparkReady.py的文件,文件中的内容如下。
import os ,sys ,re
import pymongo
import findspark
findspark.init()
from pyspark.sql import SparkSession
def start_spark(appname='Default APP'):
name = appname
spark = SparkSession.builder.appName(name).getOrCreate()
print("Spark 框架启动成功 !!! ")
return spark
然后在该文件夹下创建一个example00.py文件,输入的测试代码如下。
from SparkReady import start_spark
import time
spark = start_spark('App2')
time.sleep(1000)
输出结果中会打印‘Spark 框架启动成功 !!!’,在浏览器中输入localhost:4040,会看到Spark的进程已经创建成功,app.name就是指定的名称。
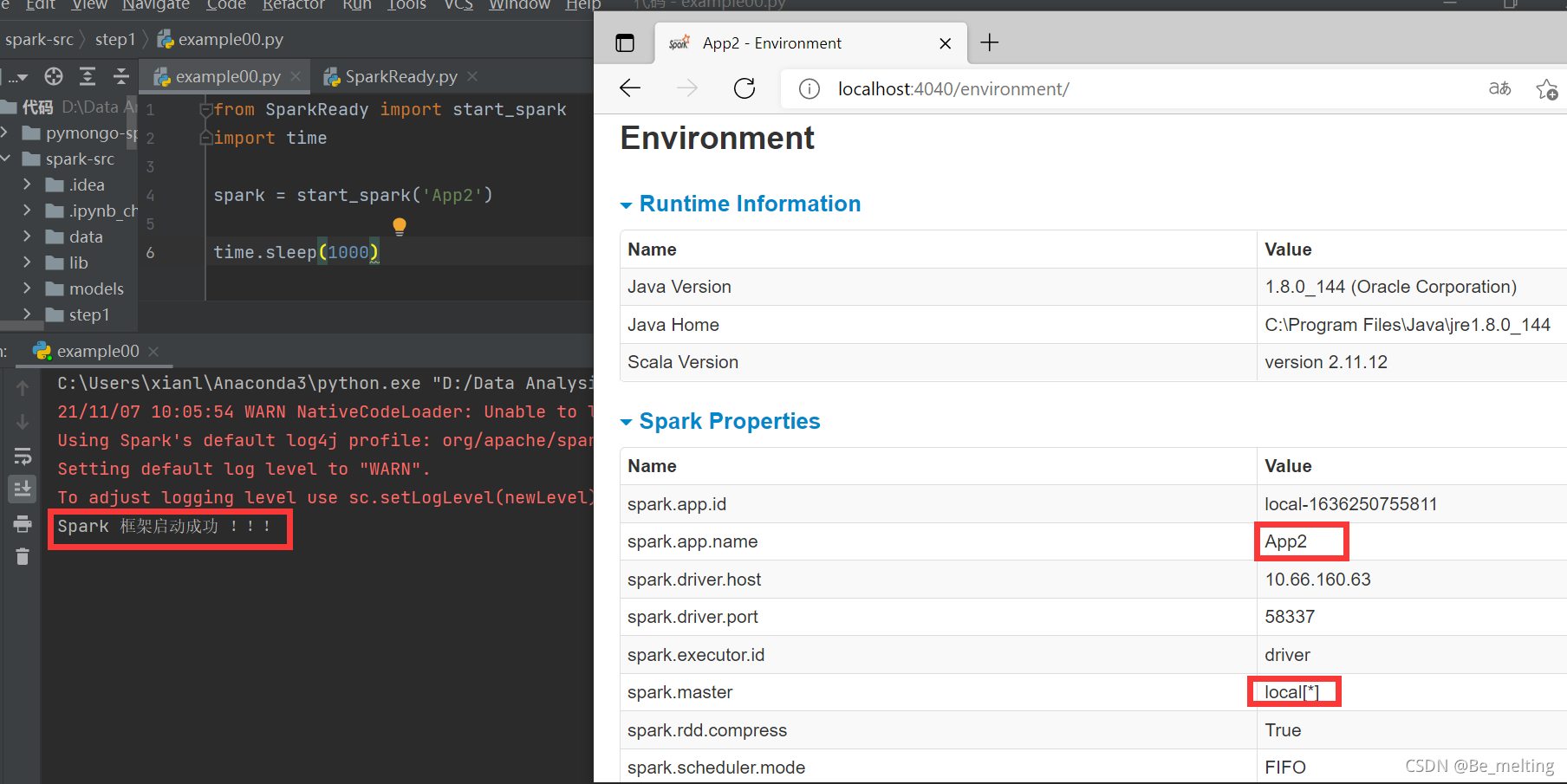
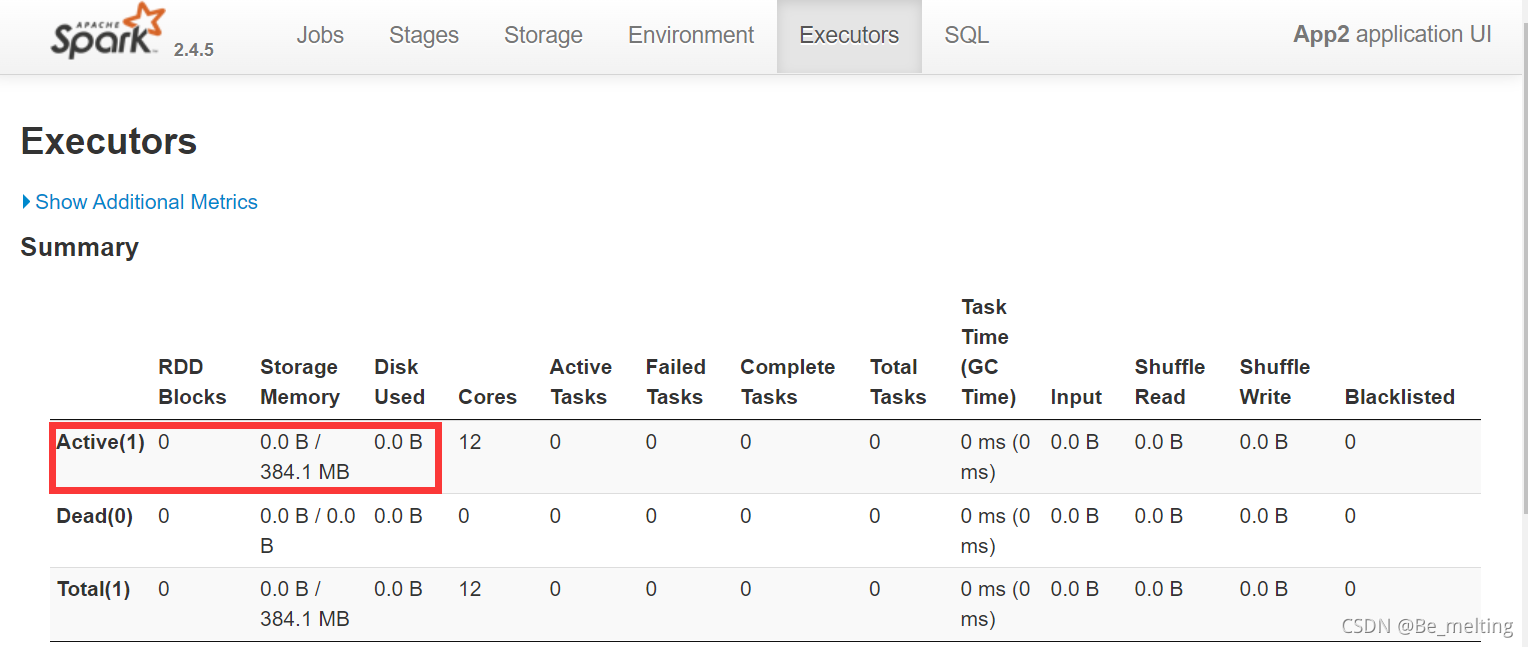
需要留意一个属性,就是这里的spark.master,默认就是local[*],表示spark会使用电脑中的所有的cpu,此外进入到Executors选项卡中,第一行表示激活的进程,这里显示存储内容为384.1M也就是约1G的40%,如果不进行任何设置,程序跑起来就把所有的处理器都占用了,内存爆了后,电脑很容易就崩溃。
接着就是对封装的启动Spark的程序进行额外参数的设置,修改的程序代码如下。
import os ,sys ,re
import pymongo
import findspark
findspark.init()
from pyspark.sql import SparkSession
#添加两个cpu和1g的内存
def start_spark(appname='Default APP',core=2,mem='1g'):
name = appname
dmem = mem
cpu = "local[" +str(core) +"]"
try:
spark #防止已经创建
except:
spark = SparkSession.builder.master(cpu).appName(name).config("spark.driver.memory",dmem).getOrCreate()
print('加载csv 模块')
os.environ['PYSPARK_SUBMIT_ARGS'] = 'pyspark --packages com.databricks:spark-csv_2.10:1.4.0'
print ("Spark 框架启动成功 !!! ")
return spark
设置完毕后,再次执行example00.py文件后,刷新网页页面,就会发现Spark中的信息已经发生改变了(为了方便后续csv文件的读入,这里添加了加载csv的代码)。

可以根据自己的电脑的配置,进行两个性能参数的设置,量力而行(测试电脑是12个处理器,内存为15.2G)。
4.2 利用Spark处理数据
4.2.1 配置Spark并读取CSV文件
在step1文件夹中新建一个example01.py文件,根据自己的电脑配置性能,然后读入准备好得航班数据文件,测试代码执行如下。

数据读入后,可以通过show()的方法进行查看,操作及对应输出如下。(输出的格式会保留类似之前sql输出的样式,由于数据中的字段较多,这里只截取对应字段数据)

因此为了后续方便数据的处理,可以使用toPandas()方法,将读入的内容转换称为我们熟悉的DataFrame数据类型,代码操作及输出如下。
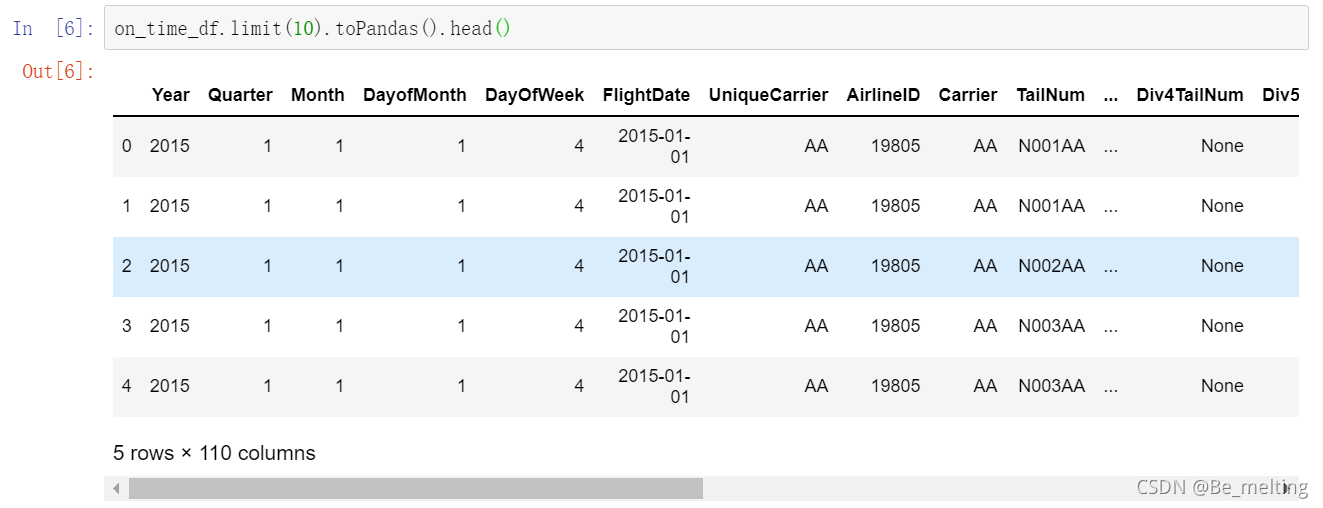
注意点:虽然上面的操作将数据转化为我们熟悉的数据类型,但是Spark中的数据是分布在多台电脑上的,一旦转化为pandas就会把数据自动集中在一台电脑上,可能导致数据量过大,程序崩溃,因此再使用toPandas()方法时候一定要带上limIt(),限制数据量。
通过转化后可以很简单的利用之前的知识进行查询,比如获取所有的字段名称,输出如下。

4.2.2 Spark下的SQL查询
(1)指定字段查询
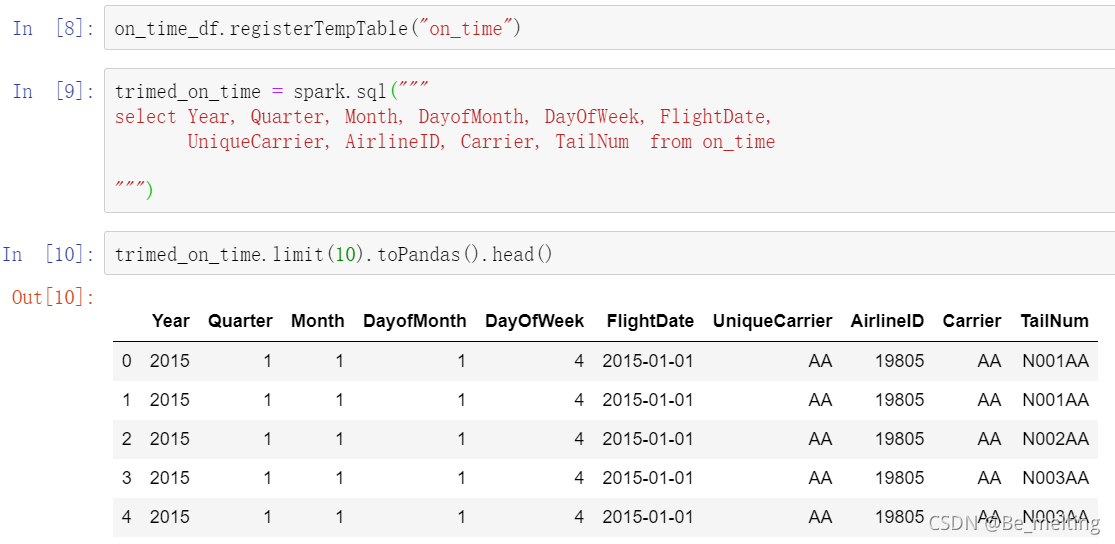
此外也可以直接使用SQL语句进行数据的查询,首先要将获取的Spark中的数据转化为表结构,然后就使用查询语句就可以完成,代码操作及输出如下。
(2) 汇总字段计算查询
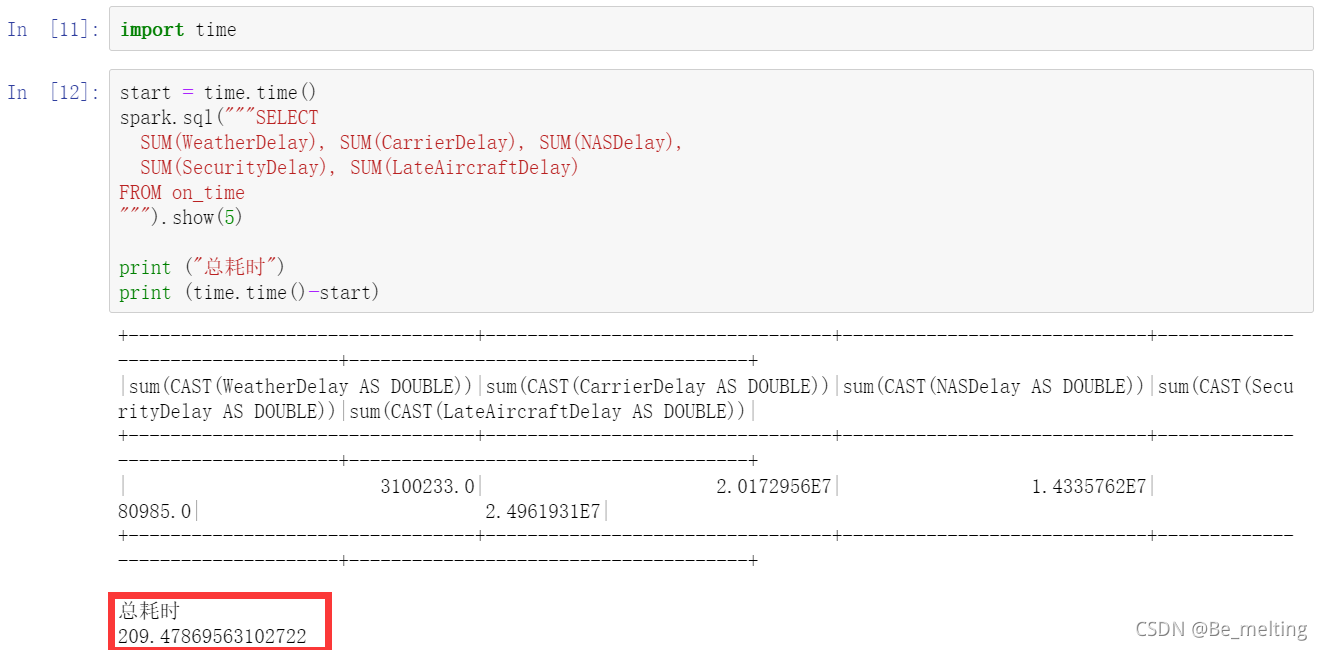
也可以添加一些汇总的计算函数用于SQL语句的查询,输出如下。
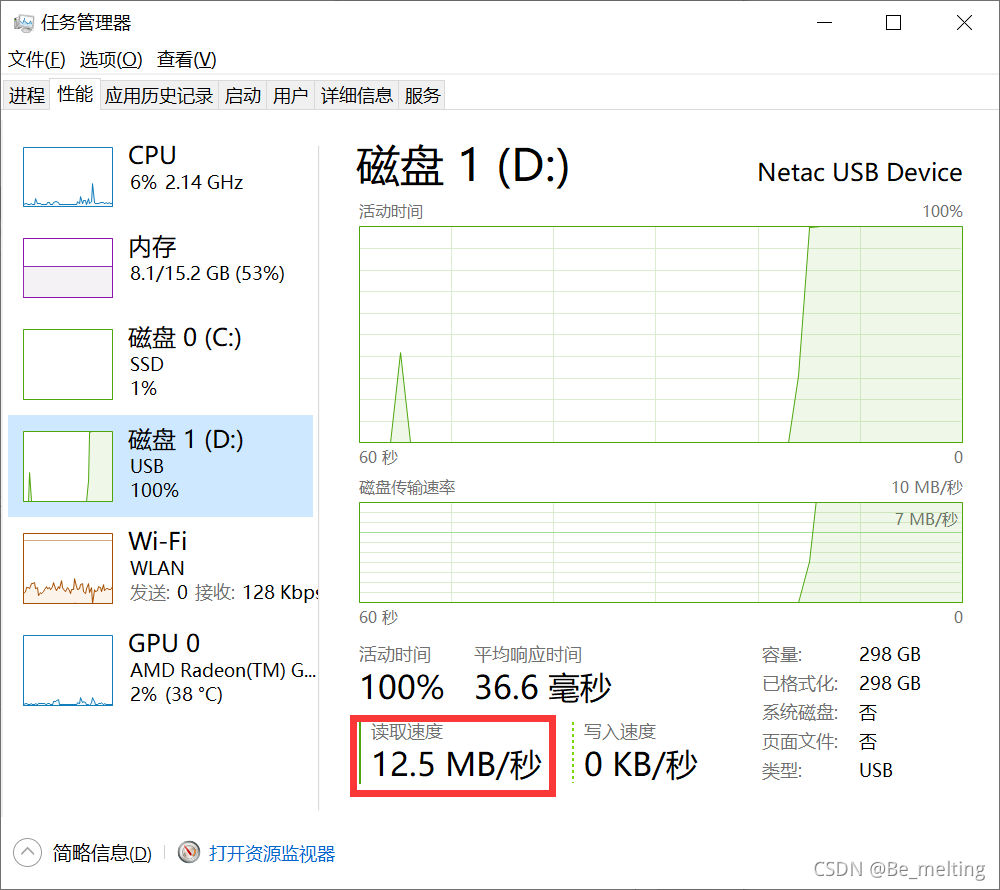
上面测试的数据是在外接的D盘移动硬盘上(电脑中只有C盘),在运行程序的时候打开任务管理器可以发现读取速度只有12.5MB/秒,且当前的磁盘全部占用,但是发现CPU却几乎没有使用。
然后把数据放置在C盘,在数据所在的文件夹打开jupyter notebook,再次运行程序,可以发现程序很快运行完毕,总共用时只有4.78s。(速度提高50倍左右)
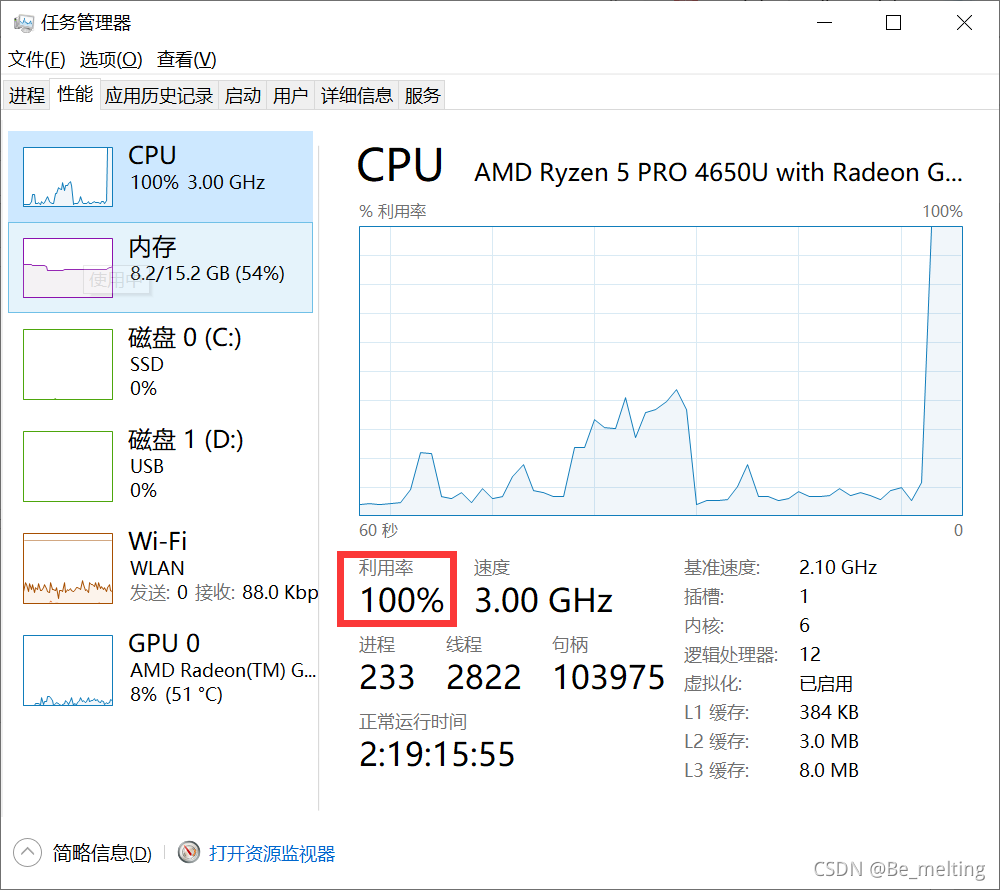
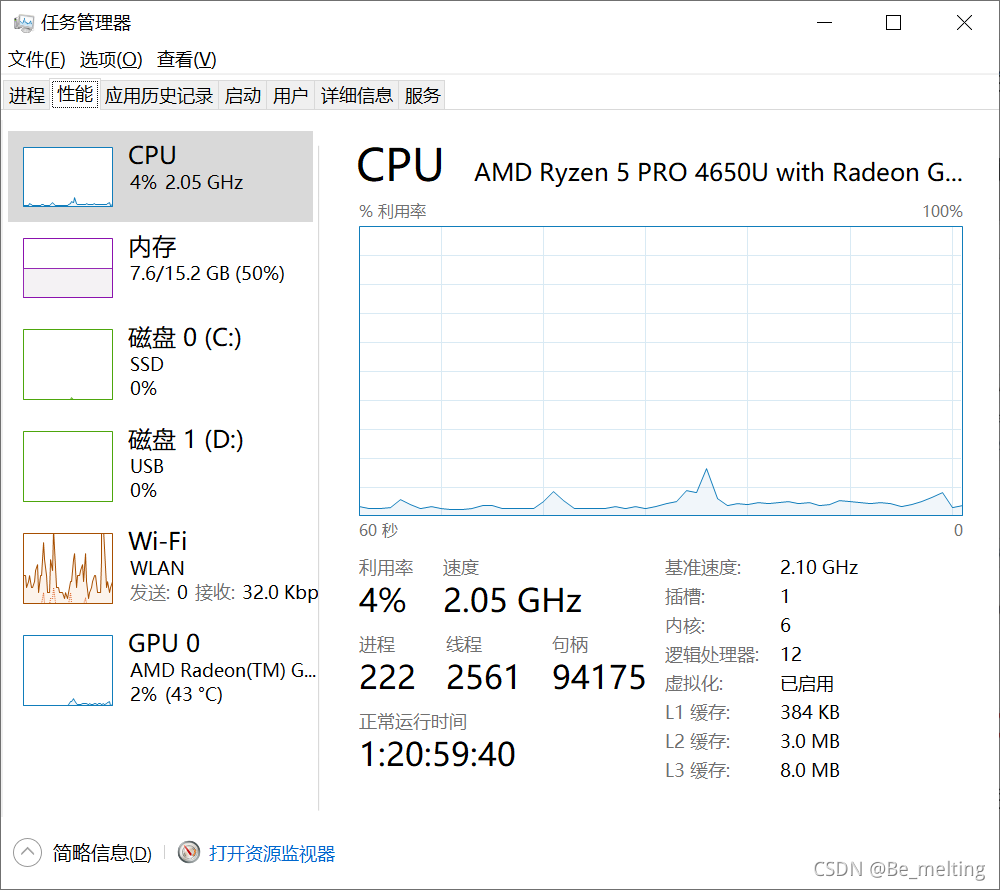
任务管理器中CPU和内存运行情况如下,在处理期间CPU利用率达到100%。

打开localhost:4040界面,可以看到spark的工作流程,红框中指定20个处理器都进行工作。

(3) 计数查询与范围查询
对数据进行计数,输出执行时间仅有1.65s。

也可以指定范围查询,比如查询一段时间范围之内的数据,此外在jupyter notebook中进行单个cell运行时间的获取,可以直接通过魔法函数%%time执行,下面的代码操作工执行4.13s,查询到了46w+的数据量。
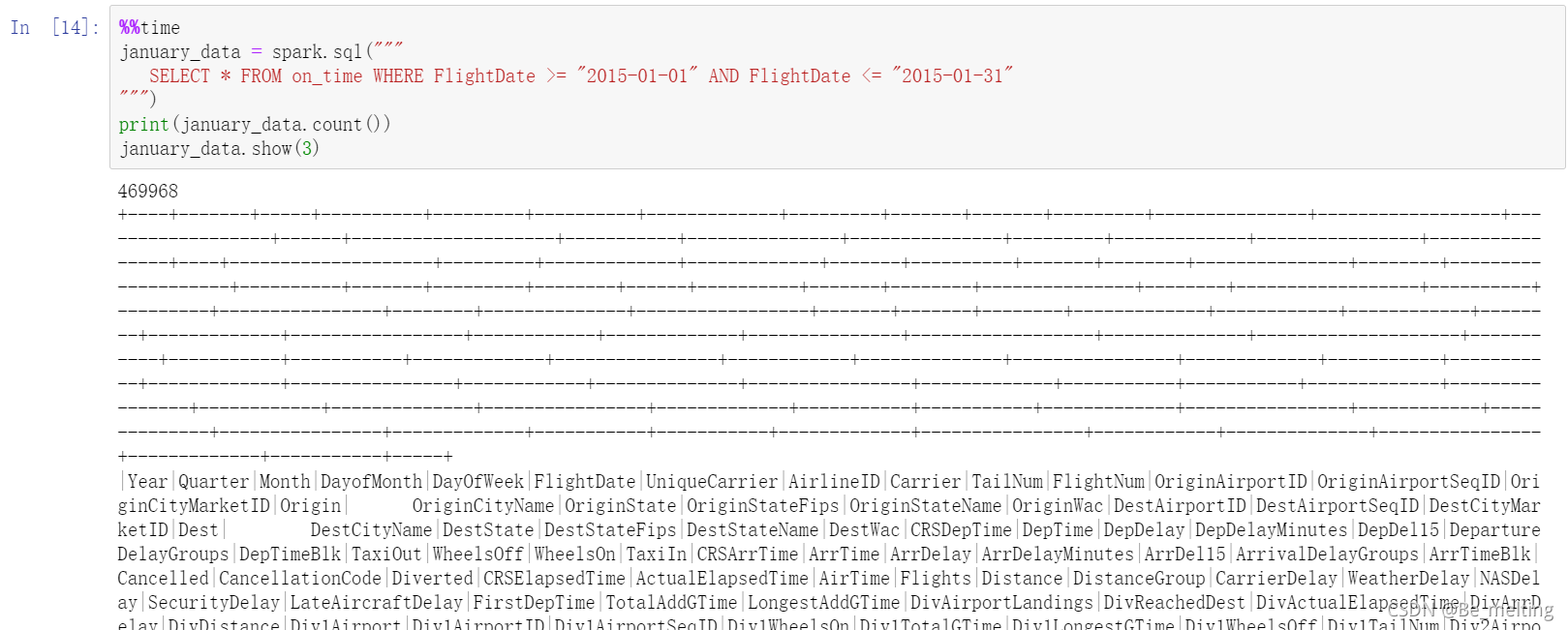
为了方便查看也可以转化为pandas数据类型,已经筛选完毕后的数据再进行pandas转化的过程基本上是秒出数据,如下。

4.2.3 数据筛选
航班数据中共有110+字段,有些字段信息是不需要的,因此要进行必要信息的筛选,每个字段的具体信息可以在之前介绍下载数据的界面进行查看,都有详细的解析,如下代码就是筛选目标的字段进行输出。

数据筛选完毕后,可以通过printSchema()查看每个字段的数据类型,输出如下(只进行部分截取)。

4.2.4 数据空值处理及分组排序优化
在进行数据查看的时候,为了方便,可以将数据转化为pandas数据类型,但是特别注意只要转化一部分,不能把所有的数据都进行转化,否则就会将数据全都放在一台电脑上进行处理,压垮这台电脑了,再次提醒使用toPandas()方法的时候一定要加上limit()的限定取值,比如这里查看300条数据的情况,代码及输出如下。

接下来看一下进行分组和排序的情况,代码及输出结果如下。

此时打开loacalhost:4040,看一下刚刚的任务过程,当涉及到分组group by和order by时候系统会默认安排200个分区进行工作(涉及到Spark安装完成后,当多台电脑或者多个处理器时候,数据要进行分组或者排序,这期间需要有一个默认的规则进行。如果只有一台电脑或者一个处理器就可以很简单的进行分组排序,但是一旦多了起来,那彼此数据之间是见不到面,所以在进行分组或者排序时候Spark就默认安排了200个分区)。
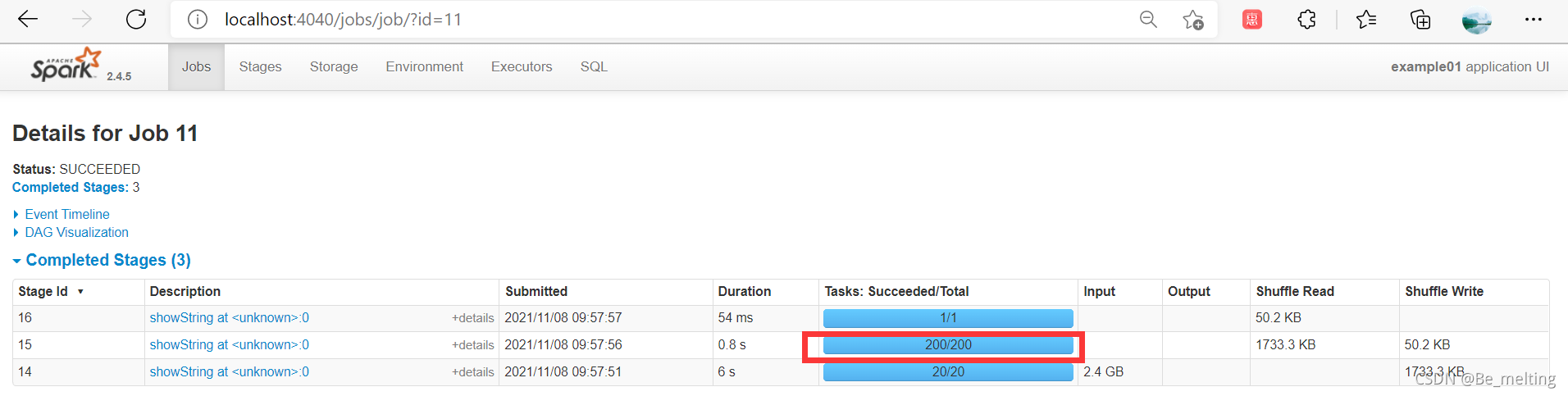
这个200可以根据自己的电脑处理器的个数进行制定,比如测试的电脑是12个,那么就可以指定分区的数量为6个,然后再测试输出的时间,如下。
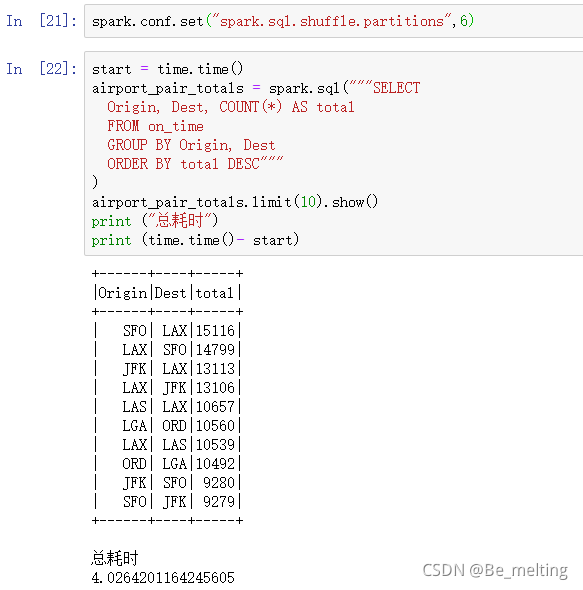
此时程序运行结束只用了4s,查看localhost:4040的运算过程,可以发现原来200个分区处的地方现在变成刚刚指定的6个分区,整体上的速度是进行了优化。

4.2.5 数据Json化并进行压缩处理
先新建一个example02.py文件,重新加载spark启动相关配置,然后读入新文件。
(1)直接生成Jsonl文件

(2)直接生成Jsonl压缩文件

(3)直接生成大数据压缩文件

4.2.6 文件读取速度对比
对比CSV文件、Jsonl压缩文件和大数据压缩文件三者之间的读取数据,其中CSV直接读上面加载数据时候已经显示为4.13s,接下来就是查看Jsonl压缩文件和大数据压缩文件读取情况,输出结果如下。

其中生成的Jsonl文件,相当于把原来的数据中都加上了key的信息,所以数据量变大,自然文件存储和读取都消耗时间,但是使用大数据技术压缩文件和读取都是很省时间,而且文件的内存也很小。