今天在卡耐基的《人性的弱点》上看到有一句就是,学习应该是有计划的复习,在学习新的内容前,应该要把旧的知识复习一遍,然后每个月再复习总的一遍,每周要反省自己。
Hadoop
Hadoop是什么
1.从原则上讲Hadoop是apache基金会的一个开源的分布式系统基础架构
2.一般来讲Hadoop 指的更是Hadoop生态圈,例如包括Hadoop,solr,pig,hive,zookeeper,mahout等等
Hadoop主要解决问题
海量数据的存储和计算
Hadoop的优势
1.可靠性,Hadoop底层维护多个数据副本,当储存或者计算出现故障时,可以找回数据
2.高扩展性,可以扩展的节点非常多
3.高效性,Hadoop是并行工作的,mapreduce,
4.高容错性,失败的任务能够重新分配
Hadoop的版本1.x和2.x区别
1.Hadoop 1.x的组成主要是hdfs,mapreduce,以及一些common,注意的是此时的mapreduce的功能不只是用于计算,Hadoop的资源调度也是由mapreduce负责。这样的mapreduce耦合性会很大。
2.Hadoop 2.x的组成是由hdfs, mapreduce,common,以及yarn,为了降低耦合性, 此时的mapreduce只有计算功能,资源管理功能分配给了y资源管理框架arn。
hdfs
hdfs–1组件

1.HDFS 遵循主/从架构,由单个 NameNode(NN) 和多个 DataNode(DN) 组成
2.NameNode是一个管理文件系统命名空间和调节客户端访问文件的主服务器,DataNode是管理对应节点的存储,通常是一个服务器部署一个DataNode。内部地,一个文件被分割为一个或多个数据块,这些数据块被存储在不同的DataNode。NameNode用于操作文件系统的命名空间,例如打开、关闭和重命名文件和目录,同时决定了数据块和DataNode的映射关系。DataNode用于处理数据的读写请求,同时执行数据块的创建,删除和来自NameNode的复制指令。
NameNode和DataNode都是被设计为可运行在普通服务器之上的软件,这些服务器通常都是使用GNU/Linux的操作系统。HDFS是用Java语言构建的,任何支持Java的服务器都可以启动NameNode和DataNode服务。使用高度可移植的Java语言意味着HDFS可以部署在广泛的机器上。一个典型的部署方式是单独启动NameNode在一台服务器,集群的其余每一台服务器都启动一个DataNode。也可以把多个DataNode部署在同一台服务器,但在实际的生产环境是不建议的。
3.Secondary NameNode:定时到 NameNode 去获取edit logs,并更新到 fsimage 上。一旦它有了新的 fsimage 文件,它将其拷贝回 NameNode 中。
NameNode 在下次重启时会使用这个新的 fsimage 文件,从而减少重启的时间。Secondary NameNode 的整个目的是在 HDFS 中提供一个检查点。它只是NameNode 的一个助手节点
hdfs–2文件系统命名空间
HDFS 的 文件系统命名空间 的层次结构与大多数文件系统类似 (如 Linux), 支持目录和文件的创建、移动、删除和重命名等操作,支持配置用户和访问权限,但不支持硬链接和软连接。NameNode 负责维护文件系统名称空间,记录对名称空间或其属性的任何更改。
hdfs–3 块
由于 Hadoop 被设计运行在廉价的机器上,这意味着硬件是不可靠的,为了保证容错性,HDFS 提供了数据复制机制。HDFS 将每一个文件存储为一系列块,每个块由多个副本来保证容错,块的大小和复制因子可以自行配置(默认情况下,块大小是 128M,默认复制因子是 3)
hdfs–4数据块的机架放置
HDFS 采用机架感知副本放置策略,对于常见情况,当复制因子为 3 时,HDFS 的放置策略是:
在写入程序位于 datanode 上时,就优先将写入文件的一个副本放置在该 datanode 上,否则放在随机 datanode 上。之后在另一个远程机架上的任意一个节点上放置另一个副本,并在该机架上的另一个节点上放置最后一个副本。此策略可以减少机架间的写入流量,从而提高写入性能。
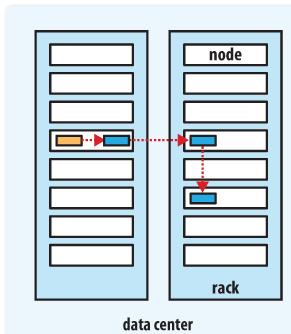
如果复制因子大于 3,则随机确定第 4 个和之后副本的放置位置,同时保持每个机架的副本数量低于上限,上限值通常为 (复制系数 - 1)/机架数量 + 2,需要注意的是不允许同一个 dataNode 上具有同一个块的多个副本。
hdfs–5 副本的选择
为了最大限度地减少带宽消耗和读取延迟,HDFS 在执行读取请求时,优先读取距离读取器最近的副本。如果在与读取器节点相同的机架上存在副本,则优先选择该副本。如果 HDFS 群集跨越多个数据中心,则优先选择本地数据中心上的副本。
hdfs–6架构的稳定性
1. 心跳机制和重新复制
每个 DataNode 定期向 NameNode 发送心跳消息,如果超过指定时间没有收到心跳消息,则将 DataNode 标记为死亡。NameNode 不会将任何新的 IO 请求转发给标记为死亡的 DataNode,也不会再使用这些 DataNode 上的数据。 由于数据不再可用,可能会导致某些块的复制因子小于其指定值,NameNode 会跟踪这些块,并在必要的时候进行重新复制。
2.数据的完整性
由于存储设备故障等原因,存储在 DataNode 上的数据块也会发生损坏。为了避免读取到已经损坏的数据而导致错误,HDFS 提供了数据完整性校验机制来保证数据的完整性,具体操作如下:
当客户端创建 HDFS 文件时,它会计算文件的每个块的 校验和,并将 校验和 存储在同一 HDFS 命名空间下的单独的隐藏文件中。当客户端检索文件内容时,它会验证从每个 DataNode 接收的数据是否与存储在关联校验和文件中的 校验和 匹配。如果匹配失败,则证明数据已经损坏,此时客户端会选择从其他 DataNode 获取该块的其他可用副本。
3.元数据的磁盘故障
FsImage 和 EditLog 是 HDFS 的核心数据,这些数据的意外丢失可能会导致整个 HDFS 服务不可用。为了避免这个问题,可以配置 NameNode 使其支持 FsImage 和 EditLog 多副本同步,这样 FsImage 或 EditLog 的任何改变都会引起每个副本 FsImage 和 EditLog 的同步更新。
4.支持快照
快照支持在特定时刻存储数据副本,在数据意外损坏时,可以通过回滚操作恢复到健康的数据状态。
hdfs–7 hdfs的特点
1 高容错
由于 HDFS 采用数据的多副本方案,所以部分硬件的损坏不会导致全部数据的丢失
2 高吞吐量
HDFS 设计的重点是支持高吞吐量的数据访问,而不是低延迟的数据访问。
3 大文件支持
HDFS 适合于大文件的存储,文档的大小应该是是 GB 到 TB 级别的。
4简单一致性模型
HDFS 更适合于一次写入多次读取 (write-once-read-many) 的访问模型。支持将内容追加到文件末尾,但不支持数据的随机访问,不能从文件任意位置新增数据。
5跨平台移植性
HDFS 具有良好的跨平台移植性,这使得其他大数据计算框架都将其作为数据持久化存储的首选方案
图解hdfs
1. HDFS写数据原理



HDFS读数据原理

HDFS故障类型和其检测方法


读写故障的处理

DataNode 故障处理

副本布局策略

以上资料来自GitHub的大神的文章https://github.com/heibaiying/BigData-Notes,感谢他们的风险让我们这些新人有学习的机会,鞠躬感谢!!