HDFS 分布式文件系统
基本原理:将文件切分成等大的数据块,分别存储在多台机器上;每个数据块存在多个备份;将数据切分、容错、负载均衡等功能透明化。
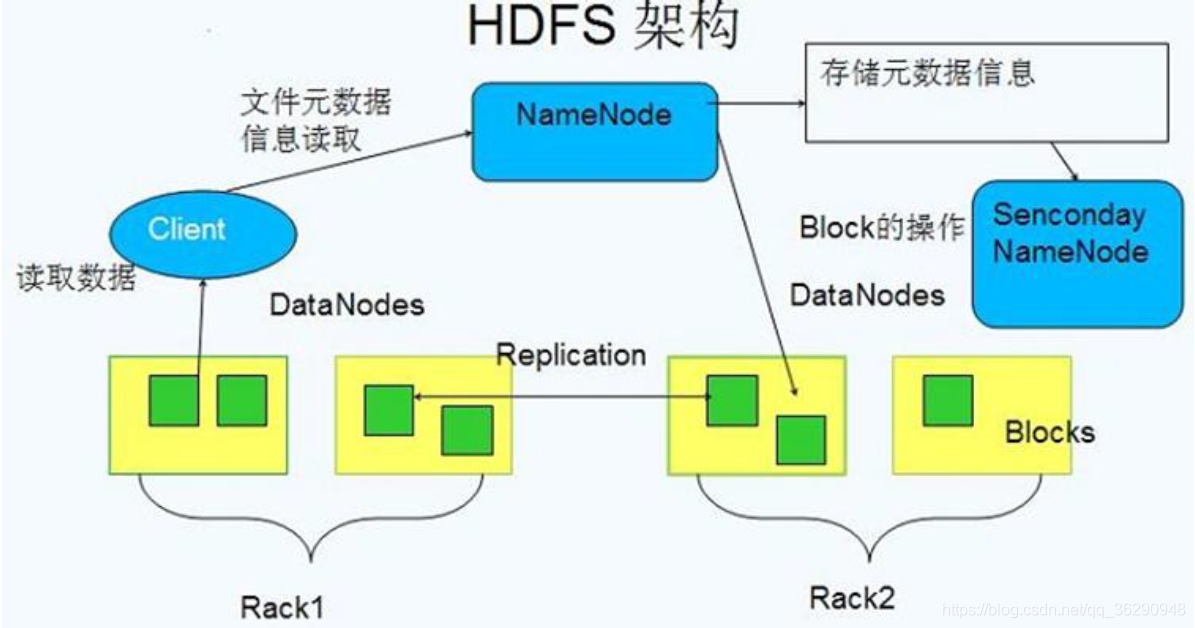
namenode: 管理文件系统的命名空间,它维护着文件系统树及整棵树内所有的文件和目录.
包含两个文件:命名空间镜像文件(fs-image:是HDFS文件系统存于硬盘中的元数据检查点,里面记录了自最后一次检查点之前HDFS文件系统中所有目录和文件的序列化信息)和编辑日志(edit-logs:保存了来自最后一次检查点之后所有针对HDFS文件系统的操作,比如:增加文件、重命名文件、删除目录等等)文件。
datanode:是文件系统的工作节点,它们根据需要存储并检索数据块(受客户端或namenode调度),并且定期向namenode发送它们所存储的块的列表(定时发送心跳)。
客户端(Client):Client代表用户通过namenode和datanode访问整个文件系统,客户端提供一个类似于POSIX(可移植操作系统界面)的文件系统接口,因此用户在编程时无需知道namenode和datanode也可实现其功能。
SencondaryNameNode:SNameNode是NameNode的助手,不要将其理解成是NameNode的备份。Secondary NameNode的整个目的在HDFS中提供一个Checkpoint Node,所以也被叫做checkpoint node。
SencondaryNameNode定时的从NameNode获取edit-logs,并更新到fs-image上。一旦它有新的fs-image文件,它将其拷贝回NameNode上,NameNode在下次重启时回使用这个新的fsimage文件,从而减少重启的时间。
注:关于NameNode是什么时候将改动写到edit logs中的?这个操作实际上是由DataNode的写操作触发的,当我们往DataNode写文件时,DataNode会跟NameNode通信,告诉NameNode什么文件的第几个block放在它那里,NameNode这个时候会将这些元数据信息写到edit logs文件中。
HDFS写数据过程:
首先client请求NN(namenode),要将多个文件写入HDFS,NN根据DN(datanode)的健康状态、复制因子、机架感知等因素随机选择的DN,建立pipline,client选择一个DN1将数据写入,其他DN从DN1复制数据,复制成功后将反馈回复给DN1,最终通过DN1将反馈传递给client,client将信息反馈给NN,NN更新元数据,client关闭pipline。
HDFS读取数据过程:
首先client请求NN,要读取数据,NN根据元数据将存储数据的DNs列表返回给client,client根据列表信息连接DN读取数据,最终Client合并读取来的数据块(block).
HDFS常用命令:

[cat]
使用方法:hadoopfs-cat URI [URI …]
说明:将路径指定文件的内容输出到stdout
[appendToFile]
使用方法:hadoopfs-appendToFile<localsrc> ... <dst>
说明:添加(追加)一个或多个源文件到目标文件中。或者将标准输入中的数据写入目标文件。
[chgrp]
使用方法:hadoopfs-chgrp[-R] GROUP URI [URI ...]
说明:改变hdfs文件所属组。修改该权限的用户必须拥有此目录权限或者父用户。-R是否递归
[chmod]
使用方法:hadoopfs-chmod[-R] <MODE[,MODE]... | OCTALMODE> URI [URI ...]
说明:修改文件权限。-R表示是否递归。修改者必须拥有该目录权限,或者是拥有者的父用户。
[chown]
使用方法:hadoopfs-chown[-R] [OWNER][:[GROUP]] URI [URI ]
说明:修改文件拥有者。修改者必须拥有该文件或者是其父用户。-R表示递归。
[copyFromLocal]
使用方法:hadoopfs-copyFromLocal<localsrc> URI
说明:拷贝本地文件到HDFS。类似于put命令,但可以拷贝目录。-f参数表示覆盖原来已存在目录。
[copyToLocal]
使用方法:hadoopfs-copyToLocal[-ignorecrc] [-crc] URI <localdst>
说明:拷贝HDFS文件到本地,类似于get命令,但可以拷贝目录。
[count]
使用方法:hadoopfs-count [-q] [-h] [-v] <paths>
说明:统计目录下文件数,空间占用情况。
-h:输出格式化后的信息。-v:输出表头
[cp]
使用方法:hadoopfs-cp[-f] [-p | -p[topax]] URI [URI ...] <dest>
说明:将文件从源路径复制到目标路径。这个命令允许有多个源路径,此时目标路径必须是一个目录。-f 如果目标目录已存在,则覆盖之前的目录。
[df]
使用方法:hadoopfs-df[-h] URI [URI ...]
显示目录空闲空间,-h:转换为更加易读的方式,比如67108864用64M代替。
[expunge]
使用方法:hadoopfs–expunge
说明:清空回收站
[get]
使用方法:hadoopfs-get [-ignorecrc] [-crc] <src> <localdst>
说明:复制文件到本地文件系统。可用-ignorecrc选项复制CRC校验失败的文件。使用-crc选项复制文件以及CRC信息
[getmerge]
使用方法:hadoopfs-getmerge<src> <localdst> [addnl]
接受一个源目录和一个目标文件作为输入,并且将源目录中所有的文件连接成本地目标文件。addnl是可选的,用于指定在每个文件结尾添加一个换行符。
[ls]
使用方法:hadoopfs -ls<args>
说明:如果是文件,则按照如下格式返回文件信息:文件名<副本数> 文件大小修改日期修改时间权限用户ID 组ID如果是目录,则返回它直接子文件的一个列表,就像在Unix中一样。目录返回列表的信息如下:目录名<dir> 修改日期修改时间权限用户ID 组ID
[lsr]
使用方法:hadoopfs-lsr<args>
说明:ls命令的递归版本。类似于Unix中的ls-R。
[mkdir]
使用方法:hadoopfs-mkdir<paths>
接受路径指定的uri作为参数,创建这些目录。其行为类似于Unix的mkdir-p,它会创建路径中的各级父目录。
[mv]
使用方法:hadoopfs-mv URI [URI …] <dest>
说明:将文件从源路径移动到目标路径。这个命令允许有多个源路径,此时目标路径必须是一个目录。不允许在不同的文件系统间移动文件。
[put]
使用方法:hadoopfs-put <localsrc> ... <dst>
说明:从本地文件系统中复制单个或多个源路径到目标文件系统。也支持从标准输入中读取输入写入目标文件系统。
Example:
hadoopfs-put localfile/user/hadoop/hadoopfile
hadoopfs -put localfile1 localfile2 /user/hadoop/hadoopdir
hadoopfs -put -hdfs://host:port/hadoop/hadoopfile(从标准输入中读取输入。)
[rm]
使用方法:hadoopfs-rmURI [URI …]
删除指定的文件。只删除非空目录和文件。-r 递归删除。
Example:
hadoopfs-rmhdfs://host:port/file /user/hadoop/emptydir
[setrep]
使用方法:hadoop fs -setrep [-R] [-w] <numReplicas> <path>
说明:改变一个文件的副本系数。-R选项用于递归改变目录下所有文件的副本系数。-w选项指定,改请求等待操作执行结束。
hadoopfs-setrep-w 3 -R /user/hadoop/dir1
[stat]
使用方法:hadoopfs-tail [-f] URI
说明:返回指定路径的统计信息。
%b:文件大小
%F:文件类型
%g:所属组
%o:block大小
%n:文件名
%r:复制因子数
%u:文件所有者
%Y,%y:修改日期
Example:
hadoopfs-stat "%F %u:%g %b %y %n" /file
[tail]
使用方法:hadoopfs-tail [-f] URI
说明:将文件尾部1K字节的内容输出到stdout。支持-f选项,行为和Unix中一致。。
Example:
hadoopfs-tail pathname
[text]
使用方法:hadoopfs-text <src>
说明:类似于cat。将源文件输出为文本格式。允许的格式是zip和TextRecordInputStream。
[touchz]
使用方法:hadoopfs-touchzURI [URI …]
说明:创建一个0字节的空文件。
Example:
Hadoopfs-touchzpathname
[truncate]
使用方法:hadoopfs-truncate [-w] <length> <paths>
说明:文件截断,-w要求该命令等待恢复完成。
Example:
hadoopfs-truncate 55 /user/hadoop/file1 /user/hadoop/file2
hadoopfs-truncate -w 127 hdfs://nn1.example.com/user/hadoop/file1
[usage]
使用方法:hadoopfs-usage command
说明:返回命令的帮助信息。
[find]
使用方法:hadoopfs-find <path> ... <expression> ...
说明:查找满足表达式的文件和文件夹。没有配置path的话,默认的就是全部目录/;如果表达式没有配置,则默认为-print。
-name pattern 不区分大小写,对大小写不敏感
-inamepattern 对大小写敏感。
-print 打印。
-print0 打印在一行。
Example:hadoopfs -find / -name test –print
[getfacl]
使用方法:hadoopfs -getfacl[-R] <path>
说明:获取文件的acl权限。-R指定递归查找
hadoop fs -getfacl -R /dir
补充命令:
bin/hadoopdfsadmin命令支持一些和HDFS管理相关的操作。
bin/hadoopdfsadmin-help +命令 能列出所有当前支持的命令。
DistCp(分布式拷贝)是用于大规模集群内部和集群之间拷贝的工具。它使用Map/Reduce实现文件分发,错误处理和恢复,以及报告生成。它把文件和目录的列表作为map任务的输入,每个任务会完成源列表中部分文件的拷贝。由于使用了Map/Reduce方法,这个工具在语义和执行上都会有特殊的地方。
使用方法:
hadoopdistcphdfs://nn1:8020/foo/bar \hdfs://nn2:8020/bar/foo命令行中可以指定多个源目录:
hadoopdistcphdfs://nn1:8020/foo/a \hdfs://nn1:8020/foo/b \hdfs://nn2:8020/bar/foo
或者使用-f选项,从文件里获得多个源:
hadoopdistcp-f hdfs://nn1:8020/srclist \hdfs://nn2:8020/bar/foo
其中srclist的内容是hdfs://nn1:8020/foo/ahdfs://nn1:8020/foo/b
参考:http://hadoop.apache.org/docs/r1.0.4/cn/distcp.html
HDFS getConf 用于获取hdfs配置信息。
Example:
hdfsgetconf-namenodes
hdfsgetconf-secondaryNameNodes
hdfsgetconf-backupNodes
hdfsgetconf-includeFile
hdfsgetconf-excludeFile
hdfsgetconf-nnRpcAddresses
hdfsgetconf-confKeydfs.namenode.name.dir
hdfsgetconf-confKeydfs.datanode.data.dir
hdfsgetconf-confKeydfs.replication
参照:http://hadoop.apache.org/docs/r2.7.3/hadoop-project-dist/hadoop-hdfs/HDFSCommands.html#getconf
HDFS oev
用法:hdfsoev[OPTIONS] -i INPUT_FILE -o OUTPUT_FILE
说明:命令hdfsoev用于查看edits文件。
-i,–inputFile<arg>输入edits文件,如果是xml后缀,表示XML格式,其他表示二进制。
-o,–outputFile<arg>输出文件,如果存在,则会覆盖。
可选参数:
-p,–processor <arg>指定转换类型: binary (二进制格式), xml (默认,XML格式),stats (打印edits文件的静态统计信息)
-f,–fix-txids重置输入edits文件中的transaction IDs
-r,–recover使用recovery模式,跳过eidts中的错误记录。
-v,–verbose打印处理时候的输出。
Example:
hdfsoev-i /data1/hadoop/hdfs/name/current/edits_0000000000019382469-0000000000019383915 -o /home/hadoop/edits.xml
未指定-p选项,默认转换成xml格式,查看edits.xml文件。输出的xml文件中记录了文件路径(PATH),修改时间(MTIME)、添加时间(ATIME)、客户端名称(CLIENT_NAME)、客户端地址(CLIENT_MACHINE)、权限(PERMISSION_STATUS)等非常有用的信息。
当edits文件破损进而导致HDFS文件系统出现问题时,可以通过将原有的binary文件转换为xml文件,并手动编辑xml文件然后转回binary文件来实现。
参照:http://lxw1234.com/archives/2015/08/442.htm
HDFS oiv
用法:hdfsoiv[OPTIONS] -i INPUT_FILE
说明:命令hdfsoiv用于将fsimage文件转换成其他格式的,如文本文件、XML文件。
-i,–inputFile<arg>输入FSImage文件。
-o,–outputFile<arg> 输出转换后的文件,如果存在,则会覆盖。
可选参数:
-p,–processor<arg>将FSImage文件转换成哪种格式:(Ls|XML|FileDistribution).默认为Ls.
-h,–help显示帮助信息
Example:
hdfsoiv-i /data1/hadoop/dfs/name/current/fsimage_0000000000019372521 -o /home/hadoop/fsimage.txt
由于未指定-p选项,默认为Ls,出来的结果和执行hadoopfs–ls–R一样。
hdfsoiv-i /data1/hadoop/dfs/name/current/fsimage_0000000000019372521 -o /home/hadoop/fsimage.xml-p XML
指定-p XML,将fsimage文件转换成XML格式,查看fsimage.xml
XML文件中包含了fsimage中的所有信息,比如inodeid、type、name、修改时间、权限、大小等等。
参照:http://lxw1234.com/archives/2015/08/440.htm
HDFS fsck
用法:hdfsfsck<path>
[-list-corruptfileblocks|[-move | -delete | -openforwrite] [-files [-blocks [-locations | -racks]]] [-includeSnapshots] [-storagepolicies] [-blockId<blk_Id>]
说明:检查HDFS上文件和目录的健康状态、获取文件的block信息和位置信息等。
-list-corruptfileblocks:查看文件中损坏的块
-move:将损坏的文件移动至/lost+found目录
-delete:删除损坏的文件
-files:检查并列出所有文件状态
-openforwrite:检查并打印正在被打开执行写操作的文件
-blocks:打印文件的Block报告(需要和-files一起使用)
-locations:打印文件块的位置信息(需要和-files -blocks一起使用。)
-racks:打印文件块位置所在的机架信息
Example:
hdfsfsck/hivedata/warehouse/liuxiaowen.db/lxw_product_names/ -list-corruptfileblocks
hdfsfsck/hivedata/warehouse/liuxiaowen.db/lxw_product_names/part-00168 –move
hdfsfsck/hivedata/warehouse/liuxiaowen.db/lxw_product_names/part-00168 –delete
hdfsfsck/hivedata/warehouse/liuxiaowen.db/lxw_product_names/ -files
参照:http://lxw1234.com/archives/2015/08/452.htm
HDFS balancer
用法:hdfsbalancer [-threshold <threshold>] [-policy <policy>] [-exclude [-f <hosts-file> | <comma-separated list of hosts>]] [-include [-f <hosts-file> | <comma-separated list of hosts>]] [-idleiterations<idleiterations>]
说明:用于平衡hadoop集群中各datanode中的文件块分布,以避免出现部分datanode磁盘占用率高的问题。
-threshold<threshold>:表示的平衡的阀值,取值范围在0%到100%之间。每个Datanode中空间使用率与HDFS集群总的空间使用率的差距百分比。
-policy<policy>:平衡策略,默认DataNode。应用于重新平衡HDFS存储的策略。默认DataNode策略平衡了DataNode级别的存储。这类似于之前发行版的平衡策略。BlockPool策略平衡了块池级别和DataNode级别的存储。BlockPool策略仅适用于Federated HDFS服务。
-exclude/include:参数-exclude和-include是用来选择balancer时,可以指定哪几个DataNode之间重分布,也可以从HDFS集群中排除哪几个节点不需要重分布
-idleiterations<iterations>:迭代检测的次数。
Example:
hdfsbalancer –threshold 10
HDFS Java API
1.创建maven项目,加入如下依赖。
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.3</version>
</dependency>
</dependencies>
2.添加hdfs-site.xml文件,core-site.xml文件到src/main/resources目录中。
3.FileSystem操作HDFS。
Configuration conf= new Configuration();
FileSystemfs= FileSystem.get(conf);
Path srcPath= new Path(“/test”);
fs.mkdirs(srcPath);// 创建test目录