对于GPU并行编程稍有了解的同学,应该知道存储优化是多么重要。减少主机端到设备端的数据传输次数,调用具有合适权限的不同种类的存储,优化数据结构与算法在存储中执行,直接决定了并行的效率。本章我们就来谈下如何针对存储的使用进行优化,来提升并行编程的效率。
1. 端到端的数据传输最小化
Host-Device之间的数据传输速度远低于global memory,因此需要减少数据传输的频率。一些基本的优化原则包括:
中间数据直接在GPU分配,操作和释放;GPU更适合重复计算。
如果数据传输没有减少,性能提升有限。
大块数据传输好于小块数据,数据小于80K,性能会受到延迟影响。
内存传输与计算时间重叠,采取双缓存模式提升效率。
合并访存:global memory带宽很大,但是具有较高的延迟。因此需要在访存时实现基于Wrap的合并访存以提高效率(我的理解是,线程访存与存储位置应该具有次序,以实现合并访存)
2. Shared Memory
比global memory快上百倍,可以通过缓存数据减少global memory访存次数。线程可以通过shared memory协作,用来避免不满足合并条件的访存。
很多线程访问存储器,因此存储器被划分为banks;连续的32位访存被分配到连续的banks;每个bank每个周期可以响应一个地址。如果有多个bank的话可以同时相应更多地址申请。出现多个bank冲突,会影响效率。
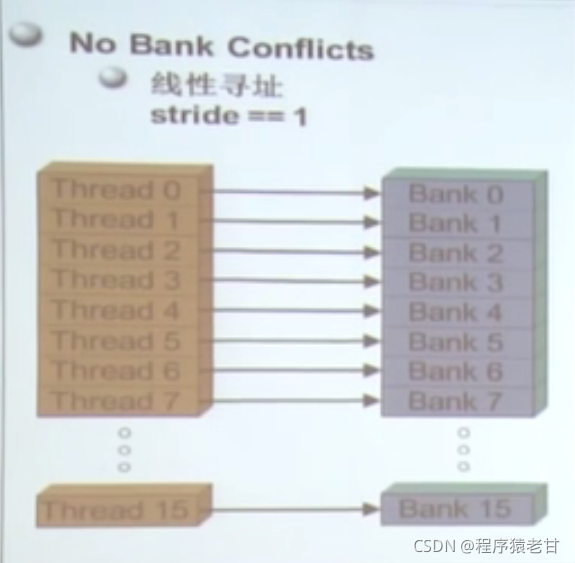
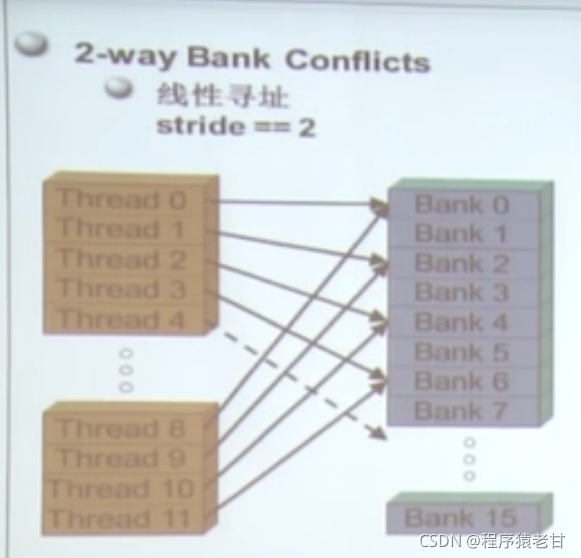
实例:矩阵转置,通过shared memory实现合并访存

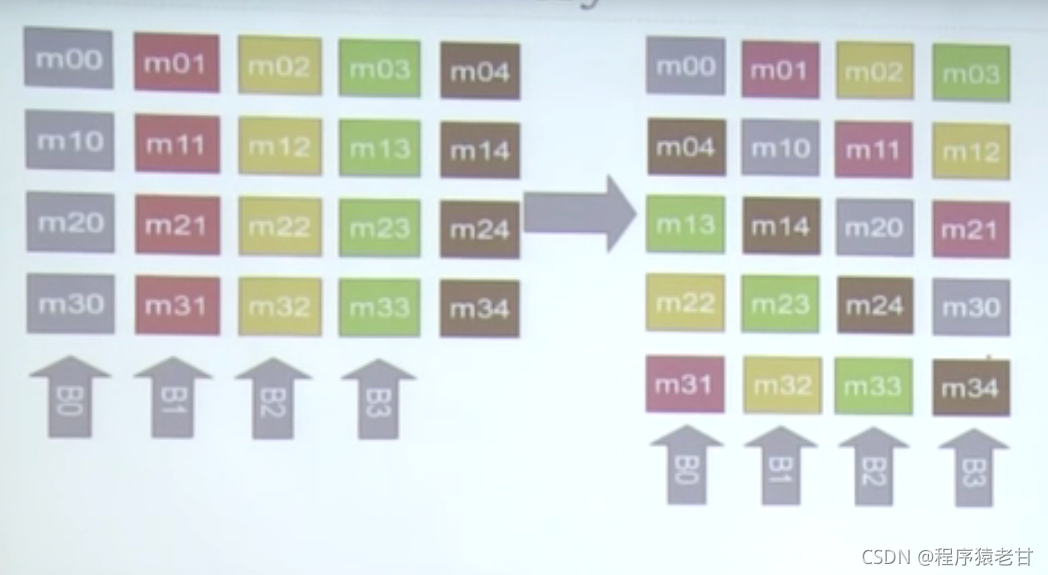
均衡的使用bank来读取数据,来防止bank冲突:
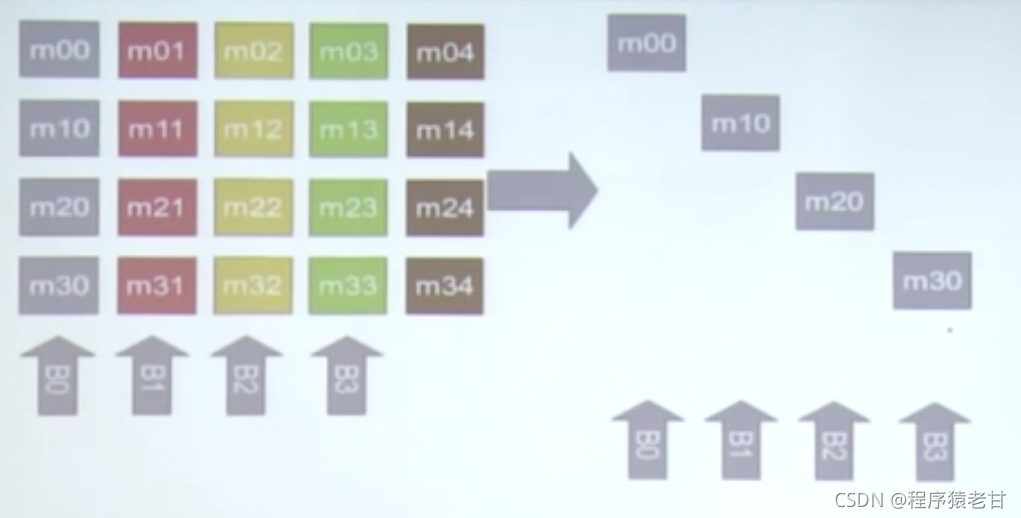
左侧,如果竖向访问,一定会产生bank冲突。但是如果按照右边的方式,逻辑上对左侧矩阵的竖向访问也不会产生bank冲突,因为相邻关系被重新安排了。
3. 隐藏延时
这一部分主要是来讲如何对语句层面的代码进行优化,以实现在存储上的时间开销。
关键点:指令按顺序执行,一个线程的任意操作数没有预备好时将阻塞等待;延时在切换线程时被隐藏。
总结:需要足够多的线程来隐藏延时。
占用率:一个SM里面激活的warp和最大容纳数的比值。

数据预读实例:第二句可以插入到第一句中,实现延时隐藏。

编译器做循环的时候,会执行许多用于循环控制的指令,只有一部分用于浮点运算

如果可以展开循环,则能够提高效率。 这里使用blocksize来直接计算,不用循环。

可以使用语句进行自动展开:

4. 总结
至此,基于NVIDIA Fellow周斌老师的Cuda教学视频所作的Cuda系统性学习系列博客就算告一段落了。其实整个视频还是以做基础技术的介绍为主,主要涉及了Cuda编程中的一些关键技术点,但是并没有整段的程序开发优化介绍,这也许会让你觉得Cuda程序开发还是无从下手。学习Cuda编程,我的一个切身体会是,软件开发者终于不能忽视硬件执行层面的基本事实了,因为即使是访存顺序的偏差,也会大大的影响程序并行的执行效率。一个优秀的Cuda程序开发者需要对硬件层面的数据调用,存储使用以及代码执行有更加底层的,根本性的了解才能实现一段高效的Cuda程序。我第一次接触Cuda是在硕士阶段,我的经验是,Cuda上手容易,但精通却极其困难。但是,当你通过Cuda实现了程序执行质的飞跃时,那种欣喜会激励你继续在这项技术上投入精力。