Spark SQL 初识
今天我们们学习一下Spark 的最最核心的组件,也是Spark中代码量最大,社区花费大量精力的模块
在实际工作中,使用频率最高的当属 Spark SQL,通常一个大数据处理项目中,70% 的数据处理任务都是由 Spark SQL 完成,它贯穿于数据预处理、数据转换和最后的数据分析。由于 SQL 的学习成本低、用户基数大、函数丰富,Spark SQL 也通常是使用 Spark 最方便的方式。此外,由于 SQL 包含了丰富的应用语义,所以 Catalyst 优化器带来的性能巨大提升也使 Spark SQL 成为编写 Spark 作业的最佳方式
由于 Spark 对于 SQL 支持得非常好,而 pandas 在这方面没那么强大,所以,在某些场景,你可以选择 Spark SQL 来代替 pandas,这对于分析师来说非常好用,但是最新版的Spark 已经支持了pandas,这算是数据分析师的福音了。
Spark SQL的地位
首先我们看一下,Spark SQL在Spark家族中的地位

其实我们可以看到Spark SQL 最终还是依赖底层的Spark Core,也就是说最终还是转化到RDD 上执行,既然最终都是转化到RDD 上执行,为什么我们不直接使用RDD 呢,后面我们在解释这个问题。
接下来我们看一下Spark提供的这几个模块在社区中的使用情况,其实从下面的图中我们可到,使用最广泛的还是Spark SQL几乎占据了半壁江山,这也就是我们为什么要重点学习Spark SQL了
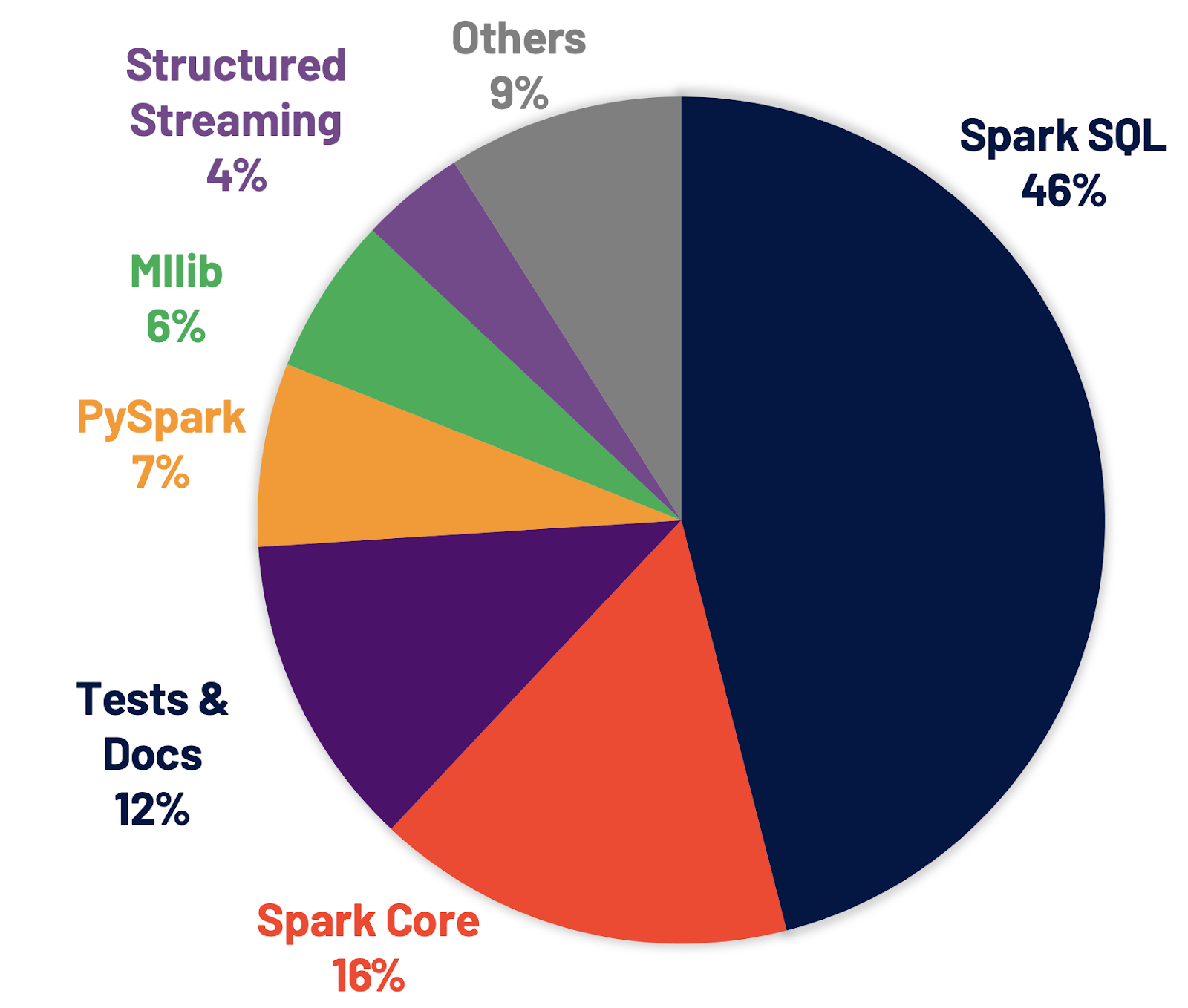
为什么要有Spark SQL
自从 Spark 社区在 1.3 版本发布了 DataFrame,它就开始代替 RDD,逐渐成为开发者的首选。我们知道,新抽象的诞生一定是为了解决老抽象不能搞定的问题。那么,这些问题都是什么呢?下面,我们就一起来分析一下。
RDD之殇—优化空间有限
自从 Spark 社区在 1.3 版本发布了 DataFrame,它就开始代替 RDD,逐渐成为开发者的首选。我们知道,新抽象的诞生一定是为了解决老抽象不能搞定的问题。那么,这些问题都是什么呢?下面,我们就一起来分析一下。
我们知道在 RDD编程中很多 转换和聚合算子,它们都是高阶函数,例如我们最常用的ma、filter、reduceBykey,高阶函数指的是形参包含函数的函数,或是返回结果包含函数的函数。为了叙述方便,我们把那些本身是高阶函数的 RDD 算子,简称“高阶算子”。
对于这些高阶算子,开发者需要以 Lambda 函数的形式自行提供具体的计算逻辑。以 map 为例,我们需要明确对哪些字段做映射,以什么规则映射。再以 filter 为例,我们需要指明以什么条件在哪些字段上过滤。
但这样一来,Spark 只知道开发者要做 map、filter,但并不知道开发者打算怎么做 map 和 filter。也就是说,在 RDD 的开发模式下,Spark Core 只知道“做什么”,而不知道“怎么做”。这会让 Spark Core 两眼一抹黑,除了把 Lambda 函数用闭包的形式打发到 Executors 以外,实在是没有什么额外的优化空间。
对于 Spark Core 来说,优化空间受限最主要的影响,莫过于让应用的执行性能变得低下。一个典型的例子,就是相比 Java 或者 Scala,PySpark 实现的应用在执行性能上相差悬殊。原因在于,在 RDD 的开发模式下,即便是同一个应用,不同语言实现的版本在运行时也会有着天壤之别。
所以这就是为什么Spark SQL一直致力于优化性能
RDD之殇—通用性不高
其实我们知道使用最广泛的编程语言其实是SQL,而且入门门槛低,我们知道Spark底层是使用scala 语言实现的,这也就是我们的spark 编程一般都是使用scala,但是我们很多数据工作者一直都是使用SQL 的。
所以Spark SQL可以弥补Spark在这一方面的不足,但是这不是说Spark SQL就是SQL,它更多的是优化,然后提供了一个 SQL的编程接口。
Spark SQL 编程模式
编程入口
Spark SQL的编程入口是SparkSession,在 Spark 版本演进的过程中,从 2.0 版本开始,SparkSession 取代了 SparkContext,成为统一的开发入口。换句话说,要开发 Spark 应用,你必须先创建 SparkSession,SparkSession持有了SparkContext的引用,所以你可以通过SparkSession实例获取SparkContext对象
val sparkConf = new SparkConf().setAppName("DataLoadAndParse").setMaster("local[2]")
val spark = SparkSession.builder().config(sparkConf).getOrCreate()
val sparkContext = spark.sparkContext
DataFrame 编程
DataFrame 是Spark SQL提供的一个数据结构,底层依赖RDD 也就是Spark Core, 因为DataFrame有了数据类型的信息,所以Spark SQL可以更好的去优化底层层存储,再加上对DataFrame的操作Spark是可以提前感知的,所以在执行的时候也可以更好的去优化。
既然DataFrame是Spark SQL提供的数据结构,那么Spark SQL也在这个数据结构之上定义了很多操作,这些操作可以很方便的完成我们的业务逻辑。
val data=spark
.read
.option("header", true)
.csv(path)
.select("ts_code","trade_date","open","high","low","close","pre_close","change","pct_chg","vol","amount")
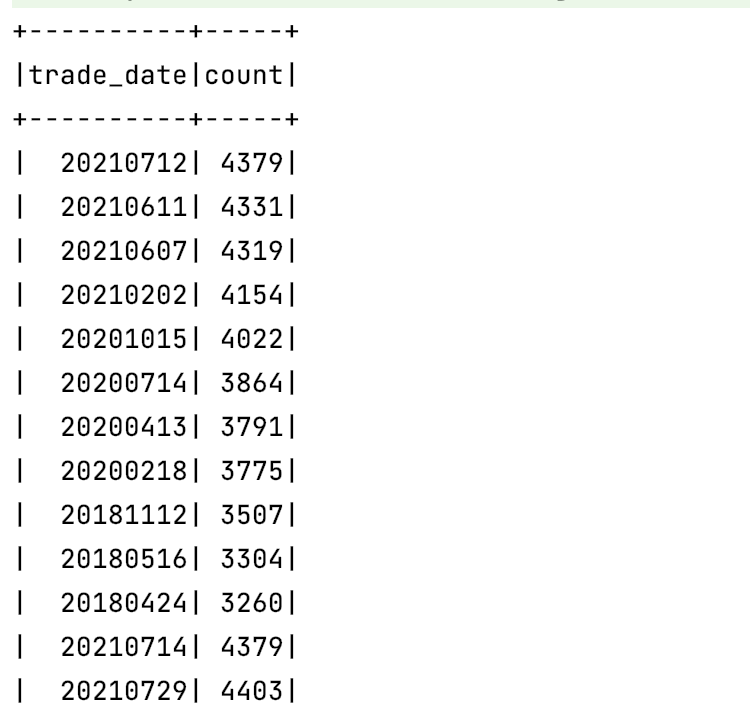
data
.groupBy("trade_date")
.count
.show()
这里我们就是统计了一下股票市场上,每天有多少只股票
SQL 编程
对于很多人不熟悉DataFrame,那Spark SQL 也给你提供了 SQL模式的编程,可以参考下面
val data=spark
.read
.option("header", true)
.csv(path)
.select("ts_code","trade_date","open","high","low","close","pre_close","change","pct_chg","vol","amount")
// close 收盘价 pre_close 昨收价 change 涨跌额 pct_chg 涨跌幅 vol 成交量 (手) amount 成交额 (千元)
data.createOrReplaceTempView("trade")
import spark.sql
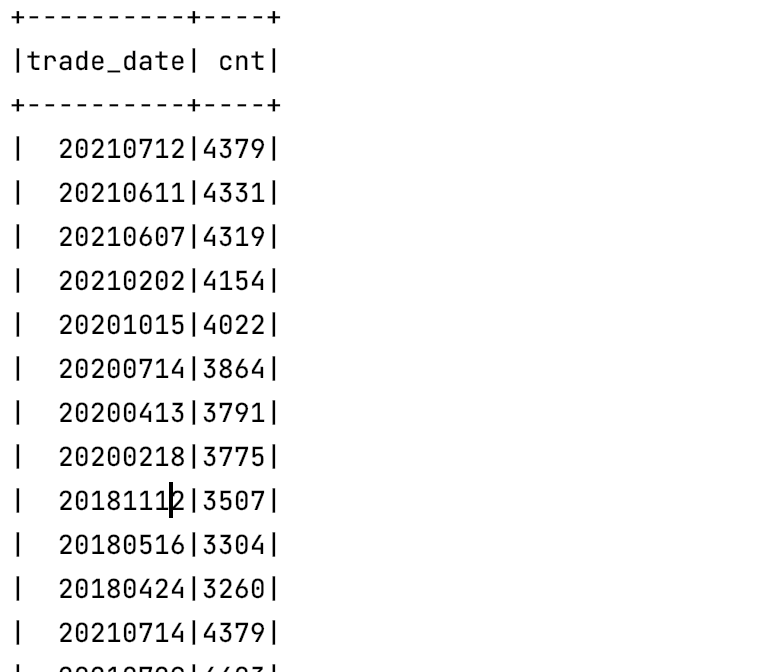
sql(
"""
|select
| trade_date,count(1) as cnt
|from
| trade
|group by
| trade_date
|""".stripMargin
).show()
混合编程
混合编程就是我们可以在一段逻辑里面同时SQL 编程和DataFrame 编程
总结
Spark SQL 是Spark 的最最核心的组件,也是Spark中代码量最大,社区花费大量精力的模块。
Spark SQL可以很方便高效的完成数据清洗数据分析的业务逻辑,主要是性能高和使用方便。
Spark SQL提供了三种编程模式,以及SQL 命令行可以配合Hive 一起使用,这也是使用最广泛的场景。