版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/Suubyy/article/details/82563964
-
Spark SQL定义Spark SQL是Spark的一个模块,它是用来处理结构化数据的。- 它将任务利用
SQL的形式转换成RDD的计算。类似于Hive利用SQL转化成了MapReduce计算。
-
Spark SQL优点- 它与
Spark Core无缝集成,在项目中我们可以与Spark Core配合实现业务逻辑。 - 它提供了同一的数据源接口
- 它内嵌了
Hive,可以连接外部已经部署好的Hive数据源,实现了Hive的集成 - 标准化的数据连接方式,可以开启
thrift server为外部提供jdbc、odbc的连接访问。
- 它与
-
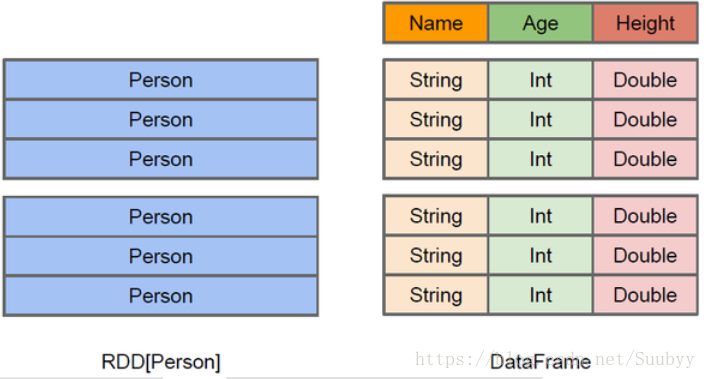
Spark SQl的数据抽象DataFrame(1.3):Spark对RDD的一种抽象,也是一种分布式、不可变的数据集,也只是在RDD之上加入了Schema信息,为RDD中的每个元素的每一列加上了名称与数据类型,这样Spark SQL就知道了数据的内部结构,比如知道了每列的名称和类型是什么,所以我们可以把DataFrame看做是一张数据库表,这样Spark为DataFrame提供了更加丰富的API,并且提供了类似于SQL的语法的操作。性能要比RDD性能高,因为Spark为DataFrame提供了优化器。它的缺点就是编译器是不会进行类型安全检查,只有在运行时进行类型安全检查。DataFrame是懒执行的,它的数据是以二进制的方式存储在非堆内存中,这样大大减少了内存的开销。Spark为DataFrame还提供了执行优化器(catalyst),当我们在利用SparkSQL操作数据的时候,Spark会为我们的查询语法进行自动的优化,提高执行效率。
DataSet(1.6):DataSet是Spark最新的数据抽象,它扩展了DataFrame,弥补了DataFrame的类型安全检查的缺陷,继承了DataFrame的执行优化。DataFrame在编译期间是不知道字段的类型的,只有在运行的时候才知道字段的类型,而DataSet是在编译期间就知道了字段的类型。DataSet支持编解码器。DataFrame=DataSet[Row],可以利用as方法将DataFrame转换成DataSet,DataSet是一直强类型数据集,在编译器就会校验数据类型。
-
Spark SQL查询方式- 利用
API - 注册临时表,利用
SQL查询
package com.lyz.sql.dataframe import org.apache.spark.sql.{DataFrame, SparkSession} object DataFrameTest { def main(args: Array[String]): Unit = { val sparkSession: SparkSession = SparkSession.builder().appName("DataFrameTest").master("local[2]").getOrCreate() val peopleDF: DataFrame = sparkSession.read.json("C:\\Users\\39402\\Desktop\\people.json") //引入隐式转换 import sparkSession.implicits._ /** * 打印结果为 * +---+------+ * |age| name| * +---+------+ * | 10|zhang3| * | 11| li4| * | 12| wang5| * | 13| zhao6| * +---+------+ * * */ peopleDF.show() /** * 打印结果为 * * | 11| li4| * | 12|wang5| * | 13|zhao6| * +---+-----+ * * */ //第一种方式利用Spark API的方式来处理数据 //$"age"这是一种DSL表达式,这个表达式相当一个变量,可以进行逻辑运算,例如:$"age"+10 peopleDF.filter($"age" > 10).show() /** * 打印结果为 * +---+------+ * |age| name| * +---+------+ * | 10|zhang3| * | 11| li4| * | 12| wang5| * | 13| zhao6| * +---+------+ */ //第二种方式利用sql方式处理数据 //转换成临时表,用sql查询 peopleDF.createOrReplaceTempView("people") sparkSession.sql("select * from people").show() } } - 利用