1HashMap
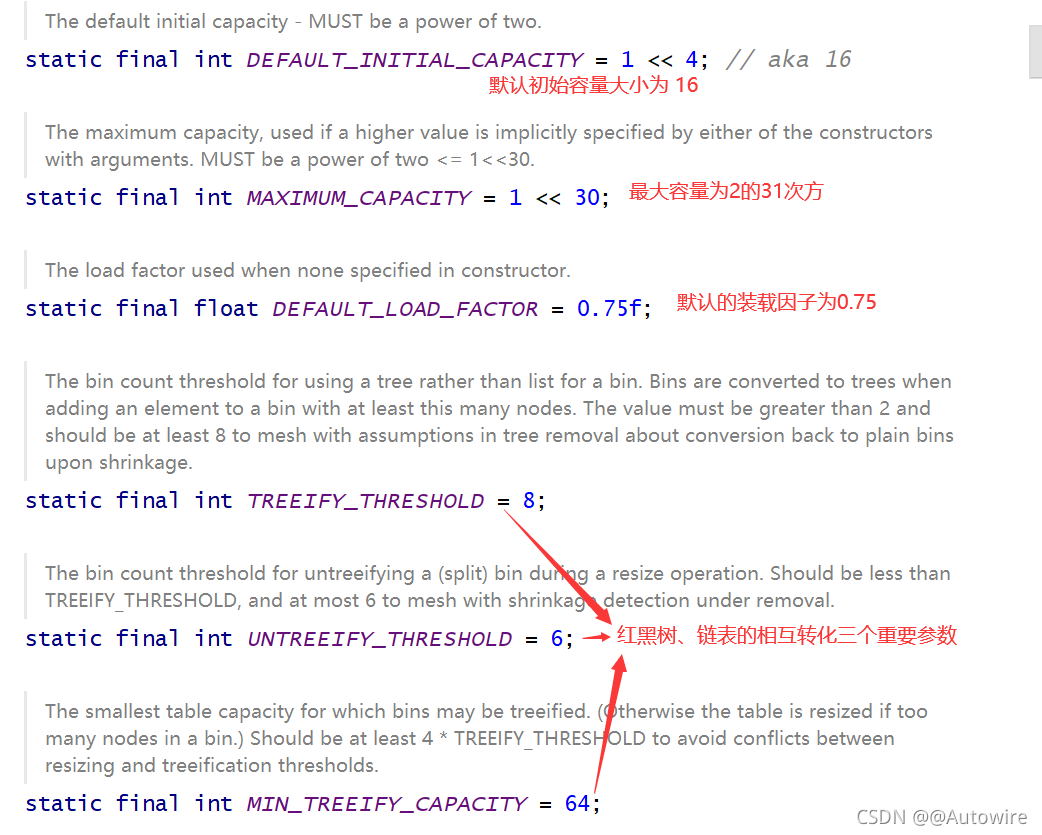

Hash的底层是散列表,而在Java中散列表的实现是通过数组+链表:

1构造方法
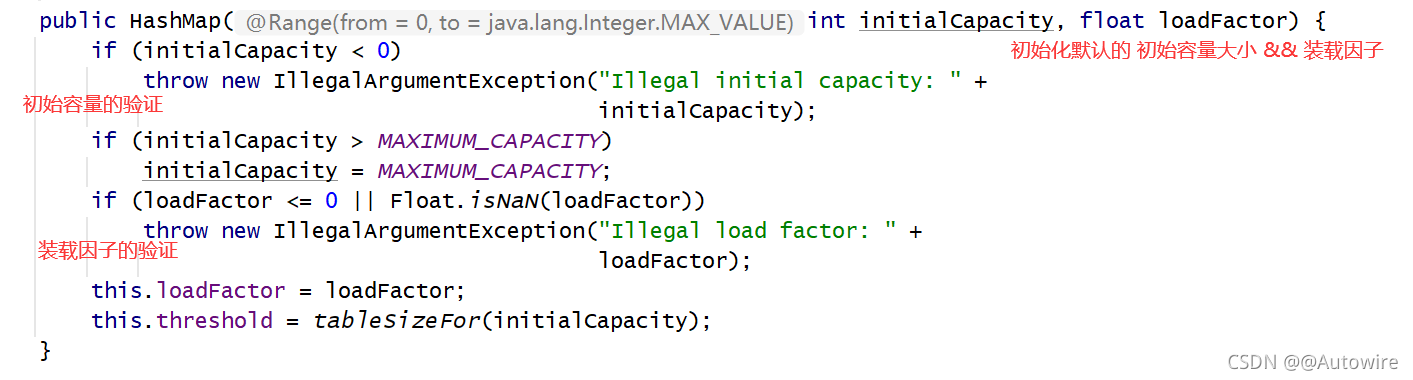
在上面的构造方法最后一行,我们会发现调用了tableSizeFor(),我们进去看看:

threshold这个成员变量是阈值,决定了是否要将散列表再散列。它的值应该是:capacity * load factor才对的。
其实这里仅仅是一个初始化,当创建哈希表的时候,它会重新赋值的:

2put方法

我们来看看它是怎么计算哈希值的:

我们一般来说直接将key作为哈希值不就好了吗,做异或运算是干嘛用的??
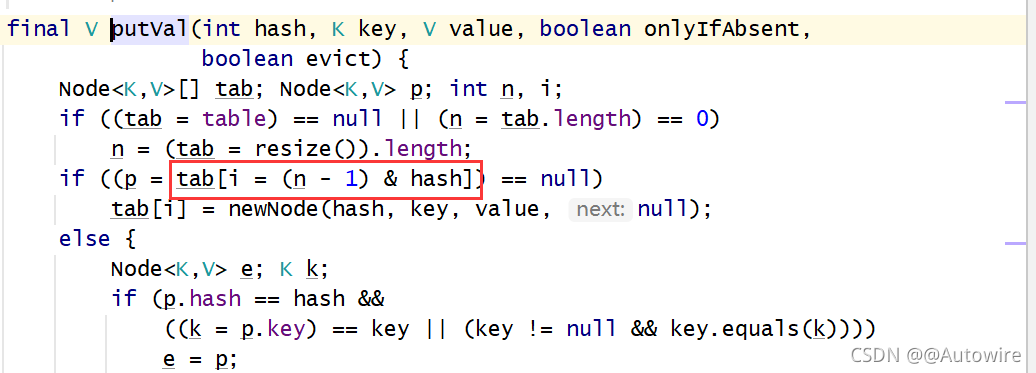
我们是根据key的hashCode来保存在散列表中的,我们表默认的初始容量是16,要放到散列表中,就是0-15的位置上。也就是tab[i = (n - 1) & hash]。可以发现的是:在做&运算的时候,仅仅是后4位有效,那如果我们key的hashCode高位变化很大,低位变化很小,直接拿过去做&运算,这就会导致计算出来的索引i相同的很多。
而设计者将key的hashCode与hashCode的高16位做异或运算,使得在做&运算时,此时的低位实际上是高位与低位的结合,这就增加了随机性,减少了碰撞冲突的可能性!
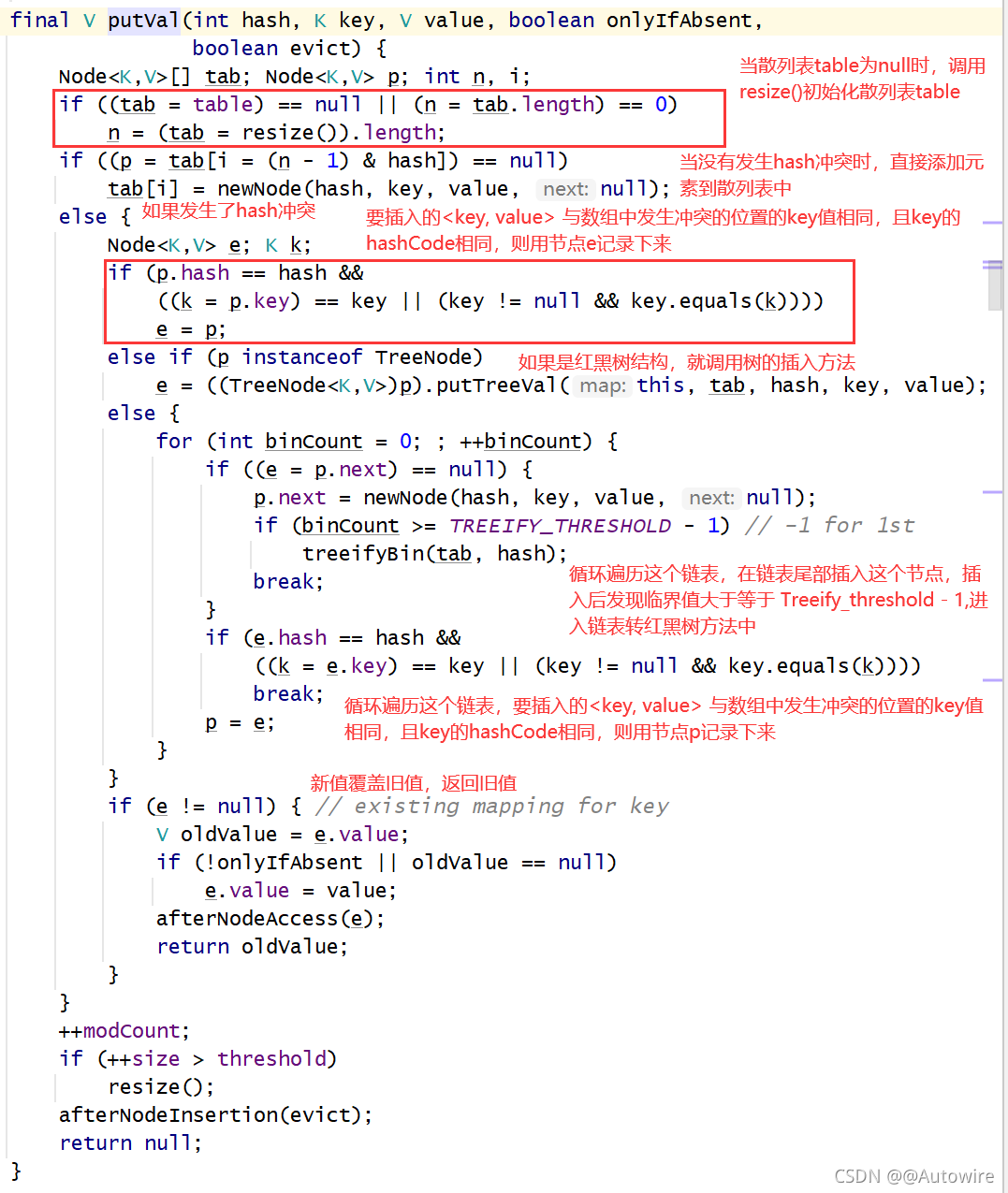
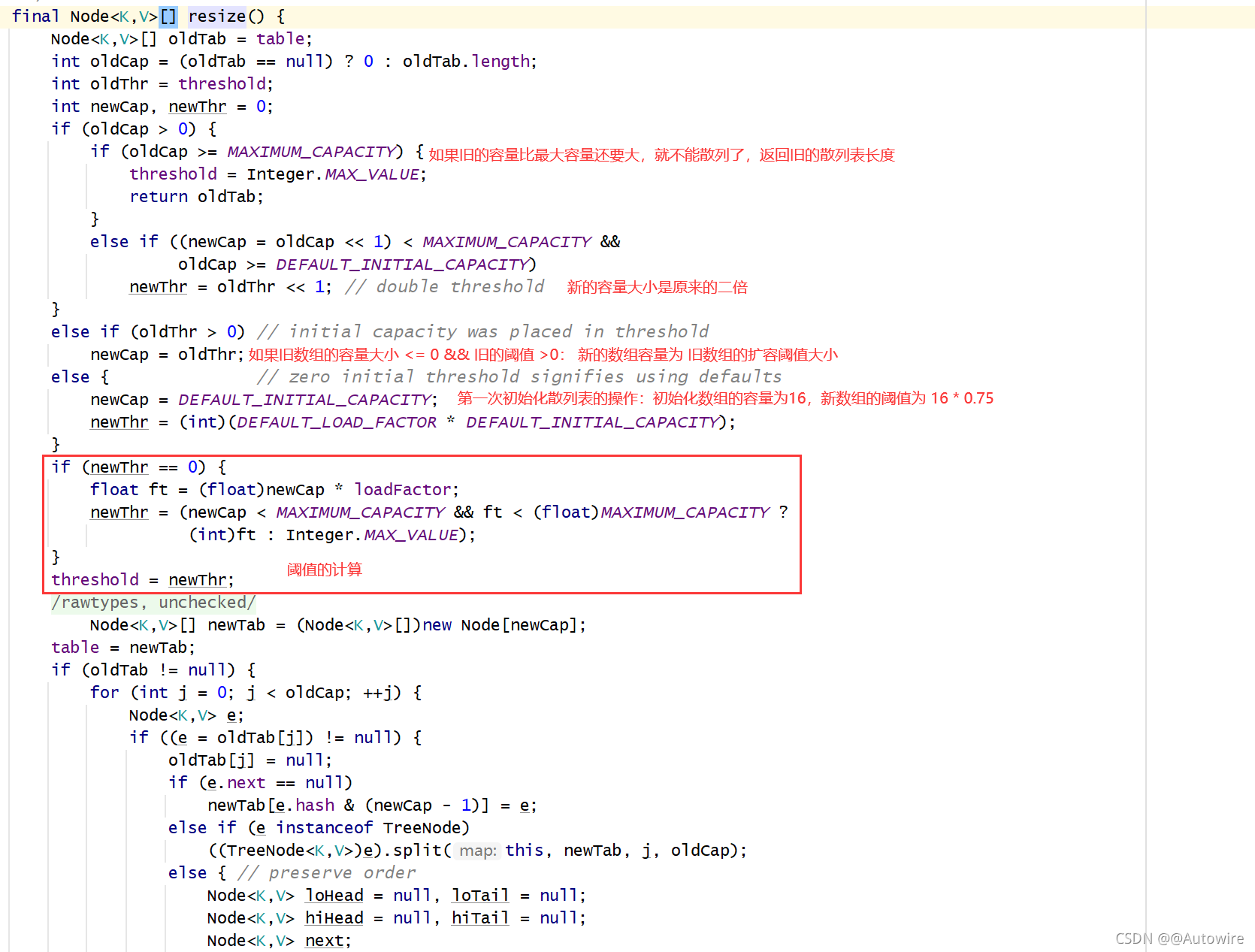
接下来我们看看resize()方法,在初始化的时候要调用这个方法,当散列表元素个数大于capacity * load factor的时候也是调用resize():

3get方法

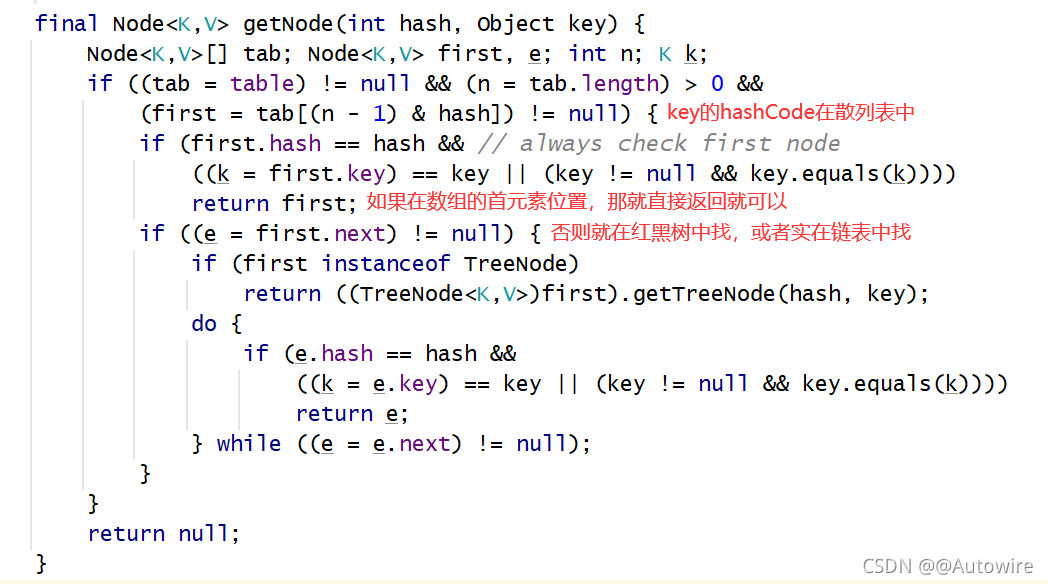
接下来我们看看getNode()是怎么实现的:
4remove方法

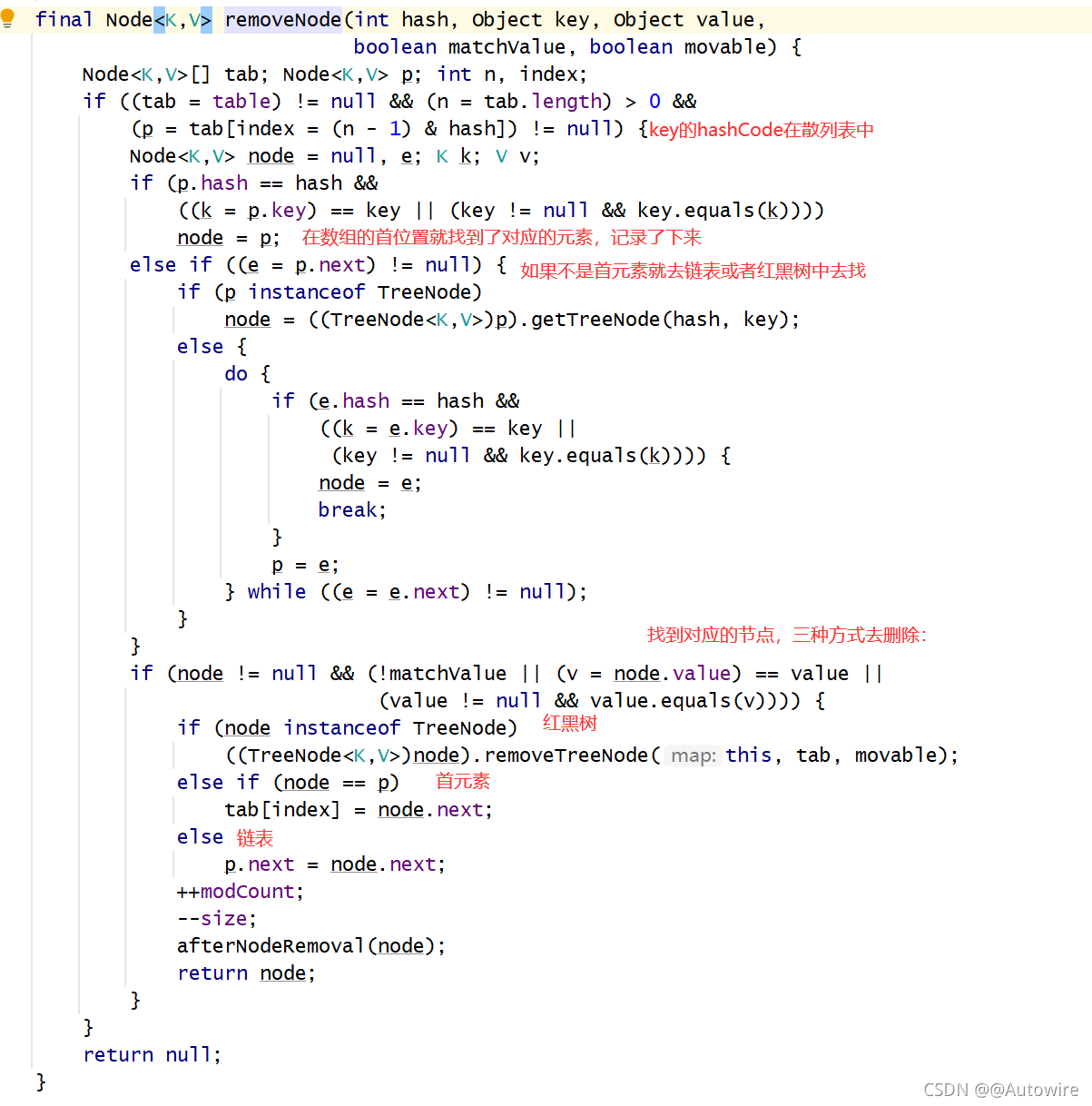
再来看看removeNode()的实现:
2HashMap的扩容机制
https://blog.csdn.net/zs18753479279/article/details/119277282
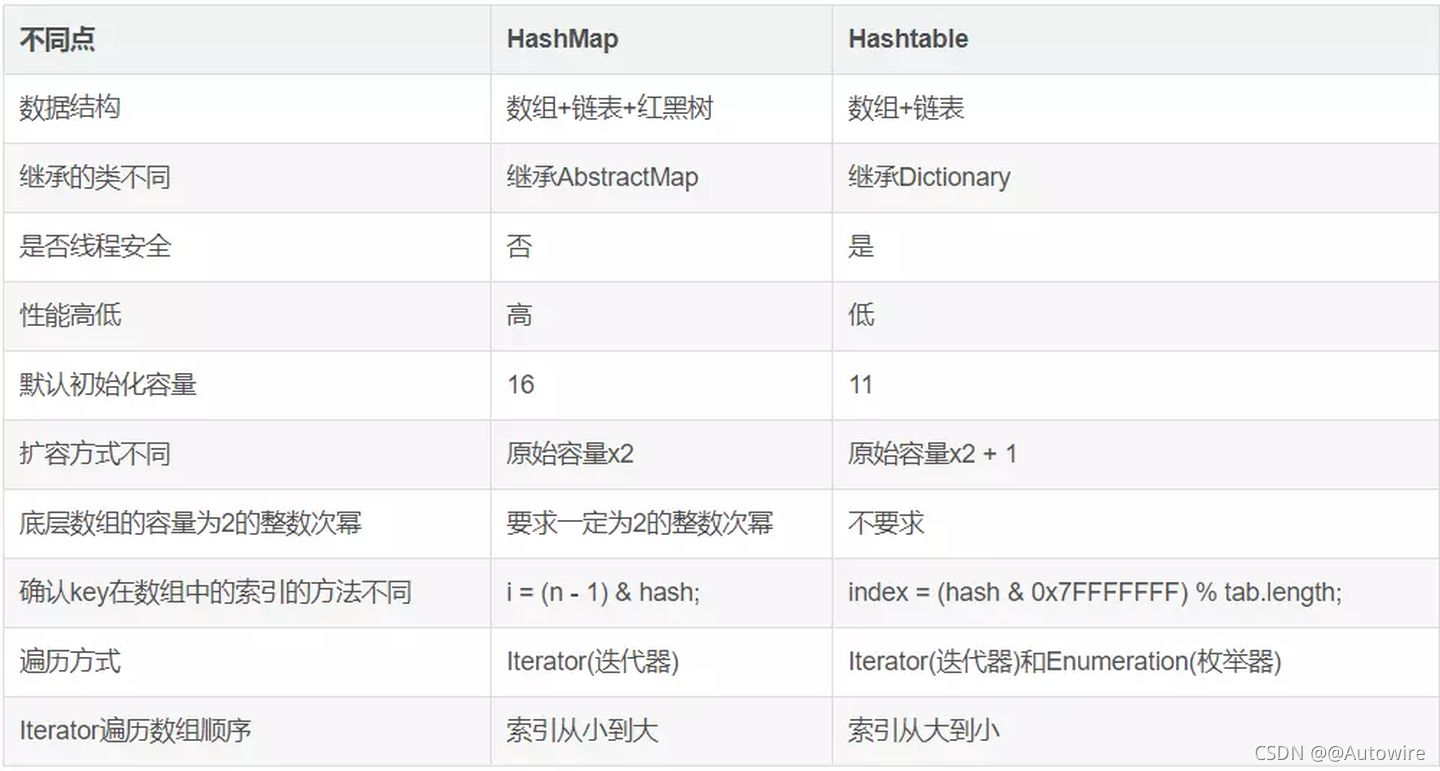
3HashMap与Hashtable对比
从存储结构和实现来讲基本上都是相同的。它和HashMap的最大的不同是它是线程安全的,另外它不允许key和value为null。Hashtable是个过时的集合类,不建议在新代码中使用,不需要线程安全的场合可以用HashMap替换,需要线程安全的场合可以用ConcurrentHashMap替换。

4总结
在JDK8中HashMap的底层是:数组+链表(散列表)+红黑树
在散列表中有装载因子这么一个属性,当装载因子*初始容量小于散列表元素个数时,该散列表会再散列,扩容2倍!
装载因子的默认值是0.75,无论是初始大了还是初始小了对我们HashMap的性能都不好:
装载因子初始值大了,可以减少散列表再散列(扩容的次数),但同时会导致散列冲突的可能性变大(散列冲突也是耗性能的一个操作,要得操作链表(红黑树);
装载因子初始值小了,可以减小散列冲突的可能性,但同时扩容的次数可能就会变多。
初始容量的默认值是16,它也一样,无论初始大了还是小了,对我们的HashMap都是有影响的:
初始容量过大,那么遍历时我们的速度就会受影响;初始容量过小,散列表再散列(扩容的次数)可能就变得多,扩容也是一件非常耗费性能的一件事。
从源码上我们可以发现:HashMap并不是直接拿key的哈希值来用的,它会将key的哈希值的高16位进行异或操作,使得我们将元素放入哈希表的时候增加了一定的随机性。