总述
focal loss就是在cross_entropy_loss 交叉熵前加了权重,让模型注重于去学习更难以学习的样本,并在一定程度上解决类别不均衡问题。在理解focal loss前,一定要先透彻了解交叉熵cross entropy。
交叉熵
信息熵H(x)

相对熵

交叉熵
衡量两个分布的差异,经常作为分类模型的损失函数。
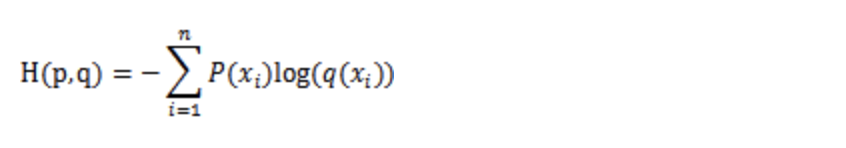
focal loss
focal loss就是在cross entropy的基础上加上权重。让模型注重学习难以学习的样本,训练数据不均衡中占比较少的样本,如果将cross loss定义为:

那focal loss加权后的定义是


相信很多人都迷惑,pt是什么。对一个样本来说,pt就是该样本真实的类别,模型预测样本属于该类别的概率。例如某样本的label是[0,1,0],模型预测softmax输出的各类别概率值为[0.1,0.6,0.3]。该样本属于第二类别,模型预测该样本属于第二类别的概率是0.6。这就是pt。pt实际上就是个分段函数。

为什么pt这么定义,我们先来求下上例的cross entropy是多少,
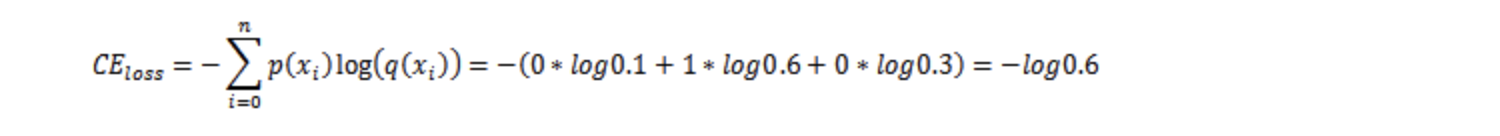
由上面求解过程可知,cross entropy的累加项中只有一个不为0,就是该样本真实类别的这项, loss为-log(pt),pt可理解为指示函数,指示对于某样例,模型预测该样例属于真实类别的概率值。
如果是二分类的话,是个特例。由于这两个的概率值互斥(总和为1),pt定义如下,也就是论文中的公式。其实和多分类一样,只是知道其中一类的概率p(x),另一类的概率用1-p(x)表示而已。

理解为pt后,整个公式就很好理解了。就是在cross loss前加上了两个权重像at和(1-pt)**gamma,分别来解释这两个权重项是怎么定义的,有什么作用。
1. a t a_t at项
a t a_t at项用来处理类别不均衡问题,类似于机器学习中训练样本的class_weight。也是个指示函数。例如训练样本中个类别占比为20%,10%,70%。那么at可以定义如下。其实就是某类别占比较高,就将该类别设置一个较小的权重a,占比较低就将其设置一个将大的权重a。降低占比高的loss。提高占比低的loss

2. ( 1 − p t ) γ (1-p_t)^{\gamma} (1−pt)γ项
个人认为该项有两个作用:
a) 让模型专注于训练难训练的样本,对于模型所属的真实类别,模型的预测值 p t p_t pt的值接近1,说明该样本容易训练, p t p_t pt值接近0(模型预测该样本属于真实类别的概率是0就说明错的很离谱),样本难以训练。提高难以训练样本的loss。降低好训练样本的loss。 p t p_t pt∈[0,1]。同样(1- p t p_t pt)∈[0,1]。 ( 1 − p t ) γ (1-p_t)^{\gamma} (1−pt)γ符合我们的要求。(满足我们需求的函数很多,并不强制要求为此函数)
b) 一定程度上也能解决类别不均衡问题。我们经常会遇到一个问题,如果在二分类中,负样本占比0.9。此时模型倾向于将样本全部判负。考虑正常CE loss中,由于正负样本的权重一样。CE LOSS包含两部分(90%的负样本(模型判别正确),10%的正样本模型判别错误)。也就是错误样本带来的loss在CE LOSS中只占10%。加上 ( 1 − p t ) γ (1-p_t)^{\gamma} (1−pt)γ项后,会提高正样本判负的loss在总loss中的比重。
focal loss 二分类 Keras实现
''' focal loss '''
def binary_focal_loss(gamma=2, alpha=0.25):
alpha = tf.constant(alpha, dtype=tf.float32)
gamma = tf.constant(gamma, dtype=tf.float32)
def binary_focal_loss_fixed(y_true, y_pred):
"""
y_true shape need be (None,1)
y_pred need be compute after sigmoid
"""
y_true = tf.cast(y_true, tf.float32)
alpha_t = y_true * alpha + (K.ones_like(y_true) - y_true) * (1 - alpha)
p_t = y_true * y_pred + (K.ones_like(y_true) - y_true) * (K.ones_like(y_true) - y_pred) + K.epsilon()
focal_loss = - alpha_t * K.pow((K.ones_like(y_true) - p_t), gamma) * K.log(p_t)
return K.mean(focal_loss)
return binary_focal_loss_fixed
model.compile(loss=[binary_focal_loss(alpha=.25, gamma=2)], metrics=["accuracy"], optimizer=optimizer)
-
多分类 focal loss 实现参考:
https://blog.csdn.net/u011583927/article/details/90716942 -
load_model的时候加载自定义损失参考:
https://blog.csdn.net/qq_42363032/article/details/121540487 -
其它关于 focal loss 理解参考:
https://blog.csdn.net/MrR1ght/article/details/93649259
https://www.cnblogs.com/king-lps/p/9497836.html