1. CLR(Cyclical Learning Rate)
优化器是构建神经网络非常重要的一部分,一个好的优化器可以是模型收敛更快,而且可能性能更好。优化器到现在已经迭代了多个版本,从最开始的SGD,到学习率随时间衰减的SGD,再到自适应优化器(Adaptive Learning Rates),典型代表便是AdaGrad, AdaDelta, RMSprop and Adam。现在大部分做法依然是设置一个固定学习率,然后在某个尺度进行衰减。
1.1 什么是CLR:
CLR(Cyclical Learning Rate,循环学习率)是一种新的设置全局学习率的方法,能够避免寻找最优学习率这个过程,在一个合理的区间内变化而不是单调下降。不像Adative Learning Rate,CLR不需要额外的计算。
[6]中对CLR进行了详细的讲解,主要意思也就是在(base_lr,max_lr)之间学习率循环波动,波动函数和iteration、stepsize相关。一个cycle(周期)也就是学习率从最低到最高再到最低的iteration数量。 以下是最简单的形式,学习率的变化均是线性的。
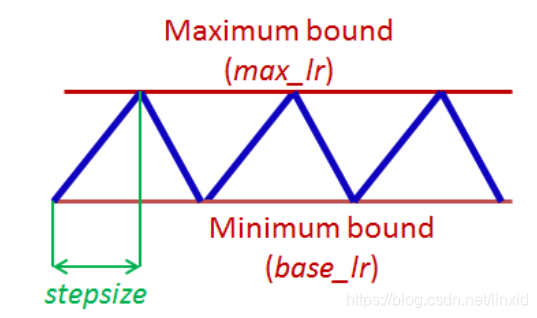
- base_lr : 最低学习率;
- max_lr:最大学习率;
- step_size:每半个周期训练的次数(iterations);
计算一个epoch所需iteration数(总样本数/batch_size)的2-10倍。
1.2 CLR的优势:
- CLR给出一种设置全局学习率方法,避免做大量实验来寻找最优学习率,并且能够更快的跳出鞍点;
- 最优的LR肯定落在最小值和最大值之间。我们确实在迭代过程中使用了最好的LR
1.3 keras实现CLR:
通过[3]可简单实现CLR。
1. 最基本的形式(三角形):
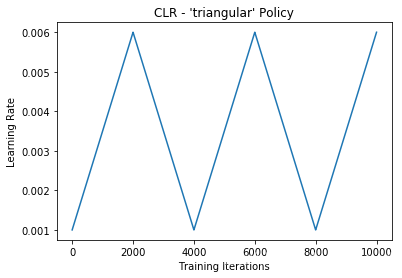
函数形状:
cycle = np.floor(1+iterations/(2*step_size))
x = np.abs(iterations/step_size - 2*cycle + 1)
lr = base_lr + (max_lr-base_lr)*np.maximum(0, (1-x))
直接调用:
clr = CyclicLR(base_lr=0.001, max_lr=0.006,step_size=2000.)
model.fit(X_train, Y_train, callbacks=[clr])
2. 递减式三角(triangular2):
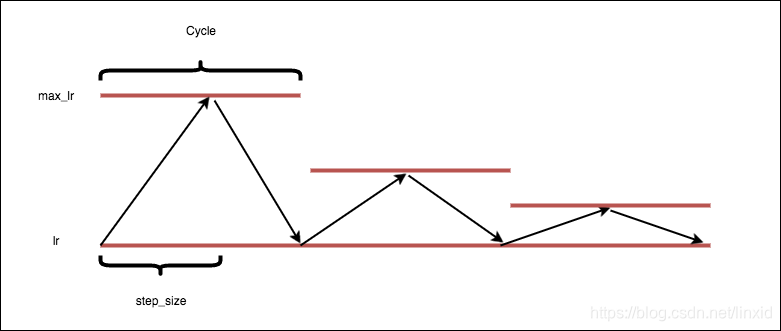
cycle = np.floor(1+iterations/(2*step_size))
x = np.abs(iterations/step_size - 2*cycle + 1)
lr = base_lr + (max_lr-base_lr)*np.maximum(0, (1-x))/float(2**(cycle-1))
clr = CyclicLR(base_lr=0.001, max_lr=0.006,
step_size=2000., mode='triangular2')
model.fit(X_train, Y_train, callbacks=[clr])
其他形式,包括指数衰减等,可以见[6]。
focal loss未完待续。。。
参考资料:
[1] Focal Loss for Dense Object Detection
[2] focal-loss-keras
[3] Cyclical Learning Rate (CLR)
[4] 周期性学习率(Cyclical Learning Rate)技术
[5] Fun. API Keras, F1 metric, Cyclical Learning Rate
[6] Cyclical Learning Rates for Training Neural Networks
[7] Introduction to Cyclical Learning Rates