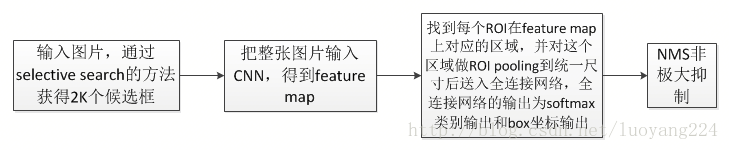
现在fast RCNN从头到尾似乎都顺了,从selective search到CNN提取特征,再到ROI pooling 后接全连接网络,多任务学习
参考faster以及SSD两种检测框架中对于正负样本的选取准则,
首先,检测问题中的正负样本并非人工标注的那些框框,而是程序中(网络)生成出来的ROI,也就是faster rcnn中的anchor boxes以及SSD中在不同分辨率的feature map中的默认框,这些框中的一部分被选为正样本,一部分被选为负样本,另外一部分被当作背景或者不参与运算。不同的框架有不同的策略,**大致都是根据IOU的值,**选取个阈值范围进行判定,在训练的过程中还需要注意均衡正负样本之间的比例。在fast的框架中,也是需要多SS算法生成的框框与GT框进行IOU的判断,进而选取正负样本,总之,正负样本都是针对于程序生成的框框而言,而非GT数据。
一个小技巧:在训练检测网络时,若已经训练出一个较好的检测器,在用它进行测试时,还会有一些误检,这时可以把误检的图像加入负样本中retrain检测网络,迭代次数越多则训练模型越好
2 Selective Search算法
主要思路:输入一张图片,首先通过图像分割的方法(如大名鼎鼎的felzenszwalb算法)获得很多小的区域,然后对这些小的区域不断进行合并,一直到无法合并为止。此时这些原始的小区域和合并得到的区域的就是我们得到的bounding box.
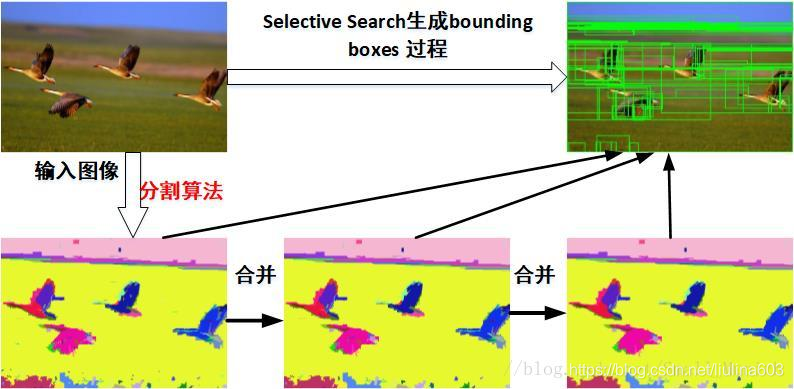
算法分为如下几个大步:
-
生成原始的区域集R(利用felzenszwalb算法)
-
计算区域集R里每个相邻区域的相似度S={s1,s2,…}
-
找出相似度最高的两个区域,将其合并为新集,添加进R
-
从S中移除所有与第3步中有关的子集
-
计算新集与所有子集的相似度
6.跳至第三步,不断循环,合并,直至S为空(到不能再合并时为止)
FPN全称是Feature Pyramid Network, 也就是特征金字塔网络
主要是针对图像中目标的多尺度的这个特点提出的,多尺度在目标检测中非常常见,而且对应不同的问题应该设计不同的FPN。FPN是Facebook于2017年提出的用于目标检测的模块化结构,但FPN在很多计算机视觉任务中都有使用,比如姿态估计、语义分割等领域。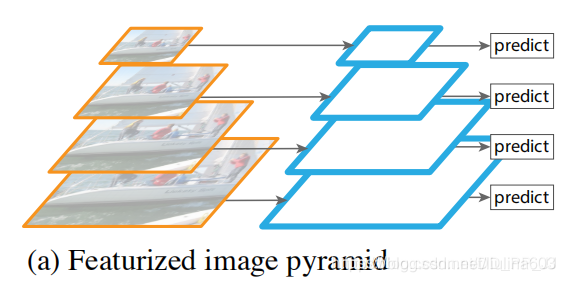
在深度学习兴起以前,很多传统方法都会使用到图像金字塔。图像金字塔如上图所示,就是将图片resize到不同的大小,然后分别得到对应大小的特征,然后进行预测。这种方法虽然可以一定程度上解决多尺度的问题,但是很明显,带来的计算量也非常大。
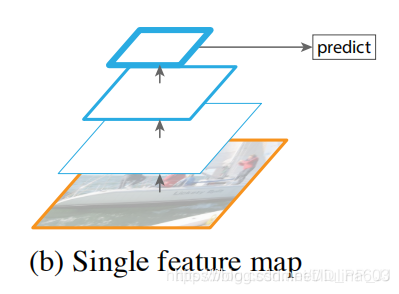
上图是使用单个feature map进行检测,这种结构在17年的时候是很多人在使用的结构,比如YOLOv1、YOLOv2、Faster R-CNN中使用的就是这种架构。直接使用这种架构导致预测层的特征尺度比较单一,对小目标检测效果比较差。ps: YOLOv2中使用了multi-scale training的方式一定程度上缓解了尺度单一的问题,能够让模型适应更多输入尺度。
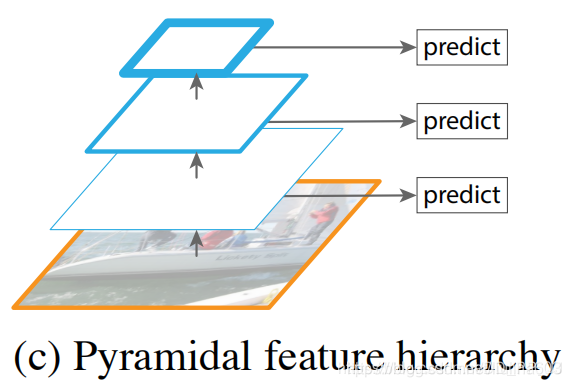
上图进行了在不同大小的feature map上分别进行预测,具有了多尺度预测的能力,但是特征与特征之间没有融合,遵从这种架构的经典的目标检测架构就是SSD, SSD用了非常多的尺度来进行检测。
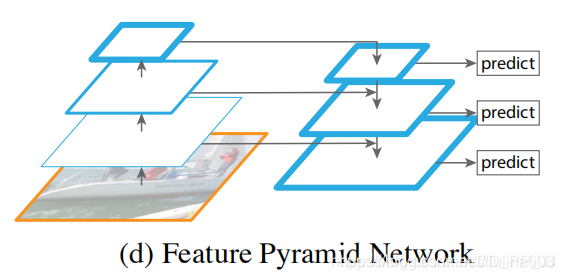
然后就是非常经典的FPN架构,FPN可以非常方便地应用到两阶段网络如Faster R-CNN等或者一阶段网络YOLO、SSD等。FPN通过构造一种独特的特征金字塔来避免图像金字塔中计算量过高的问题,同时能够较好地处理目标检测中的多尺度变化问题,效果能够达到当时的STOA。SSD的一个改进版DSSD就是使用了FPN,取得了比SSD更好的效果。
这里展开描述一下FPN的细节:
为了方便说明,做出以下规定:
图像backbone部分每个层feature map用Ci来标记,比如说C3代表stride=23=8对应的feature map,通常用C1,…C6代表每个feature map。
图像右侧的top-down结构每个feature map用Pi来标记,比如说P3代表对应C3大小的feature map。
FPN特征融合方式
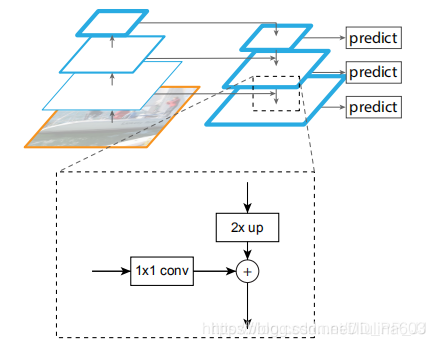
假设当前层为第三层stride=8, 要与stride=16的特征进行融合,那么C3先通过1×1卷积约束通道数和P4层达到一致;来自P4通过2倍上采样得到的feature map大小和C3一致,最终P3是通过P4上采样结果和C3进行element wise add得到结果。
那么为什么FPN采用融合以后效果要比使用pyramidal feature hierarchy这种方式要好呢?有以下几个原因:
1、卷积虽然能够高效地向上提取语义,但是也存在像素错位问题,通过上采样还原特征图的方式很好地缓解了像素不准的问题。
2、backbone可以分为浅层网络和深层网络,浅层网络负责提取目标边缘等底层特征,而深层网络可以构建高级的语义信息,通过使用FPN这种方式,让深层网络更高级语义的部分的信息能够融合到稍浅层的网络,指导浅层网络进行识别。
3、从感受野的角度思考,浅层特征的感受野比较小,深层网络的感受野比较大,浅层网络主要负责小目标的检测,深层的网络负责大目标的检测(比如人脸检测中的SSH就使用到了这个特点)。在之前发了一篇讲感受野和目标检测的文章中提到了理论感受野和实际感受野,如下图所示:

黑色的框是理论感受野,中心呈高斯分布的亮点是实际感受野,FPN中的top-down之路通过融合不同感受野,两个高斯分布的实际感受野进行融合,能够让高层加强低层所对应的感受野。(ps:这一部分是笔者的理解,若有不同见解,欢迎讨论交流)
关于感受野这个观点,FPN论文有一张图,跟之前发表的那篇文章很像,如下图所示:
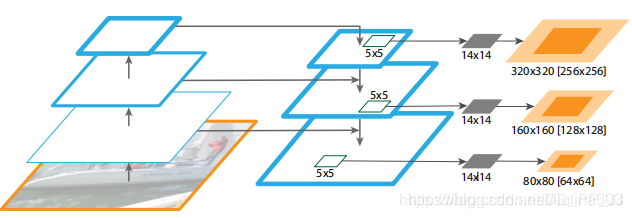
这张图讲的是FPN应用在DeepMask中做实例分割,其中使用了一个5×5的多层感知机来生成一个14×14的分割结果。对应的浅橙色的区域代表的是对应到原图的区域(与理论感受野相似),深橙色区域对应的是典型的目标区域(与实际感受野类似),观察这个图我们可以得到几个结论:
网络越深、特征图越小对应到原图的范围也就越大。这也就可以解释为什么加上FPN以后,小目标的效果提升了,比如在上图的P3到P5中,P3对应的目标区域要小一些,更符合小目标的大小。
在同一层中,理论感受野的范围要大于实际感受野。
以上这点很多讲解FPN网络的作者们都忽略了,如果对这个部分感兴趣,可以到FPN中的附录中找到详细解读。
消融实验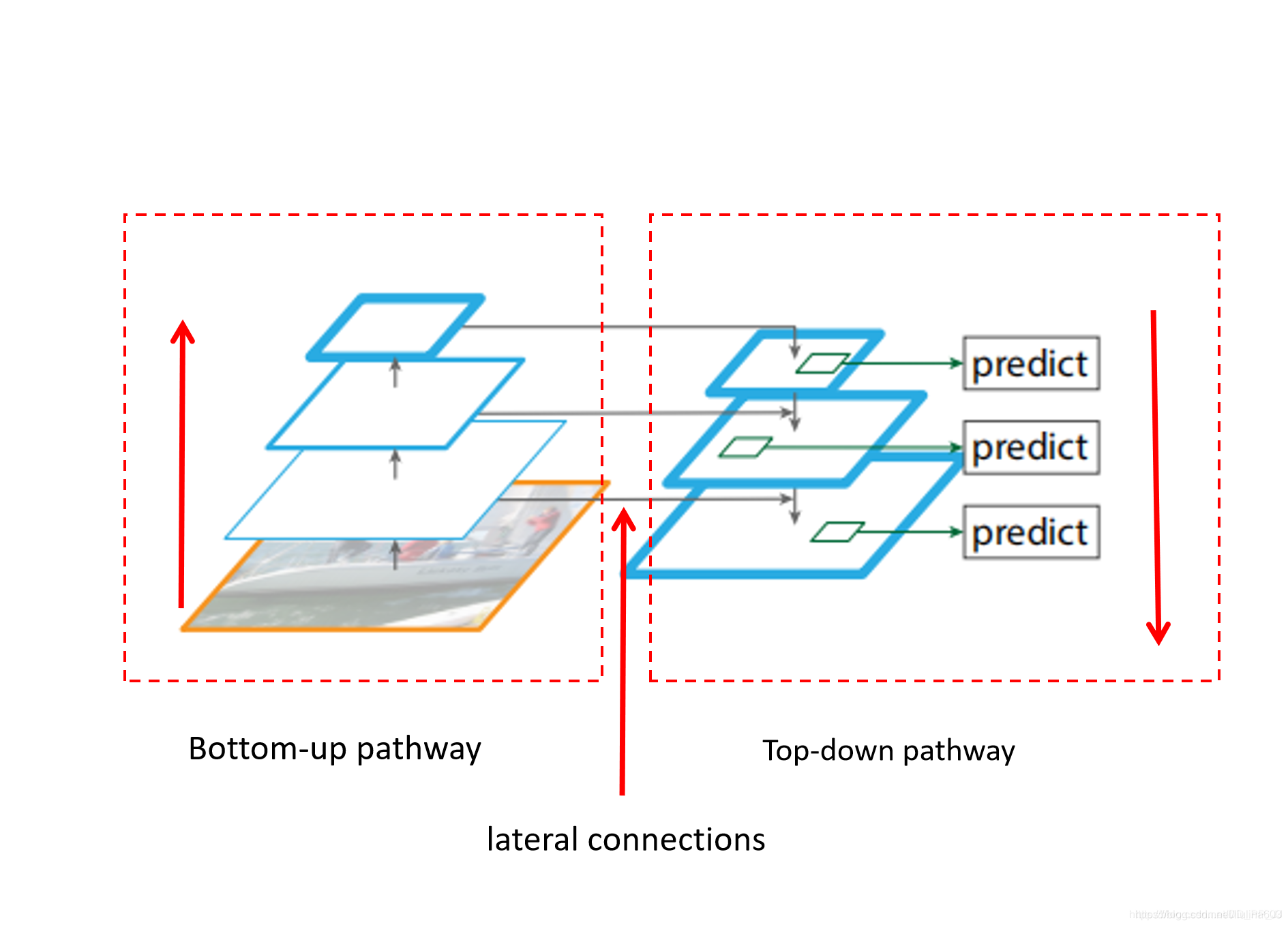
以上是FPN各部分的专有名称,作者详细对比了top-down pathway带来的增益,lateral connection带来的增益,
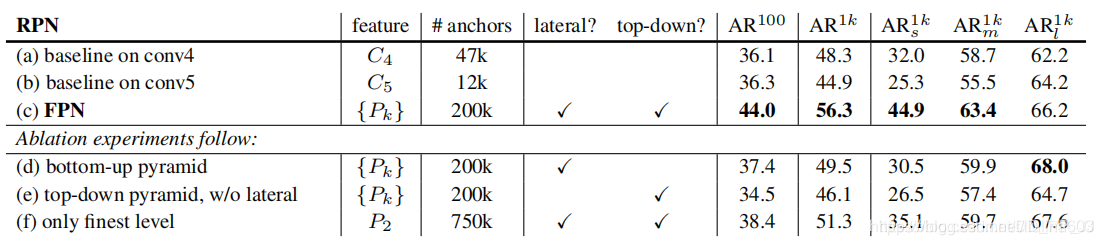
上表中的实验中能得到几个结论:
通过(a)和(b)比较,说明随着网络深入,小目标检测效果会变差,大目标检测效果会变好。
通过(d)和(e)比较,说明lateral connections是非常有必要的
通过(f)和©比较,说明只用最后一层P2效果不如使用P2,P3,P4
通过(f)和©比较,还可以发现由于P2的空间分辨率比较高,anchor非常多,可以得到一个结论就是:仅仅是使用非常多的anchor这一点本身是不足以提升准确率的。
文章中还有几个实验将FPN添加到RPN网络、DeepMask结构中,都带来不错的效果,FPN确实是一个比较好的feature fusion方法,在此之后,有很多架构的网络也不断地被提出来,都带来了一定的提升。
总结
本来这篇文章想要将FPN架构的系列写完,但是这样篇幅太大了,所以将这个列成一个小的系列,专门关心FPN的设计。
之前和一个群友在讨论的时候聊到了FPN的设计,当时灵感迸发,产生以下想法:
浅层网络负责小目标检测,深层网络负责大目标检测,这两部分融合的时候一般是通过简单的add或者concate进行融合的,为什么一定要这样融合?
浅层小目标信息比较丰富,深层网络具有高级语义,能够一定程度上指导小目标的检测,这里的浅层和深层能够添加一个权重来具体决定哪个部分占比比较大吗?
具体怎么决定浅层网络和深层网络的占比?通过先验固定取值,还是自适应通过网络学习得到?
其实看论文比较多的读者可能已经想到了,ASFF, BiFPN,BiSeNet,ThunderNet等,这都是比较好解决这个问题的方法。之后会继续解读这几个网络中关于FPN的设计,也欢迎大家交流自己的想法。
特征融合方式总结
两层特征add,eg:FPN
两层特征concate,eg:YOLOv3
使用注意力机制, eg: BiSeNet, ThunderNet
weighted add, eg: BiFPN
参考
https://medium.com/@jonathanhui/understanding-feature-pyramid-networks-for-object-detection-fpn-45b227b9106c
https://www.zhihu.com/question/306213462
https://arxiv.org/abs/1612.03144