基于密度的噪声应用聚类 ( DBScan ) 是一种无监督学习非线性算法。它确实使用了密度可达性和密度连通性的思想。数据被划分为具有相似特征或集群的组,但不需要事先指定这些组的数量。集群被定义为密集连接点的最大集合。它在带有噪声的空间数据库中发现任意形状的簇。
理论
在 DBScan 聚类中,对维度距离曲线的依赖更多。算法如下:
。
- 随机选择一个点p。
- 根据邻域的最大半径 (EPS) 和 eps 邻域内的最小点数 (Min Pts),检索从 p 密度可达的所有点。
- 如果邻域中的点数大于 Min Pts,则 p 是核心点。
- 对于 p 个核心点,形成一个集群。如果 p 不是核心点,则将其标记为噪声/异常值并移至下一个点。
- 继续该过程,直到处理完所有点。
DBScan 集群对顺序不敏感。
数据集
Iris数据集包含来自 3 种鸢尾属植物(Iris setosa、Iris virginica、Iris versicolor)中的每一种的 50 个样本,以及由英国统计学家和生物学家 Ronald Fisher 在 1936 年的论文 The use of multiple measures in taxonomic questions 中引入的多元数据集。从每个样本测量四个特征,即萼片和花瓣的长度和宽度,基于这四个特征的组合,Fisher 开发了一个线性判别模型来区分物种。
# Loading data
data(iris)
# Structure
str(iris)
|

对数据集执行 DBScan
在包含 11 个人和 6 个变量或属性的数据集上使用 DBScan 聚类算法
# Installing Packages
install.packages("fpc")
# Loading package
library(fpc)
# Remove label form dataset
iris_1 <- iris[-5]
# Fitting DBScan clustering Model
# to training dataset
set.seed(220) # Setting seed
Dbscan_cl <- dbscan(iris_1, eps = 0.45, MinPts = 5)
Dbscan_cl
# Checking cluster
Dbscan_cl$cluster
# Table
table(Dbscan_cl$cluster, iris$Species)
# Plotting Cluster
plot(Dbscan_cl, iris_1, main = "DBScan")
plot(Dbscan_cl, iris_1, main = "Petal Width vs Sepal Length")
|
输出:
- 模型 dbscan_cl:
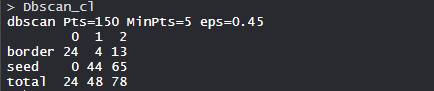
在模型中,有 150 个点,最小点数为 5,eps 为 0.5。
- 集群识别:

显示了模型中的集群。
- 绘图集群:
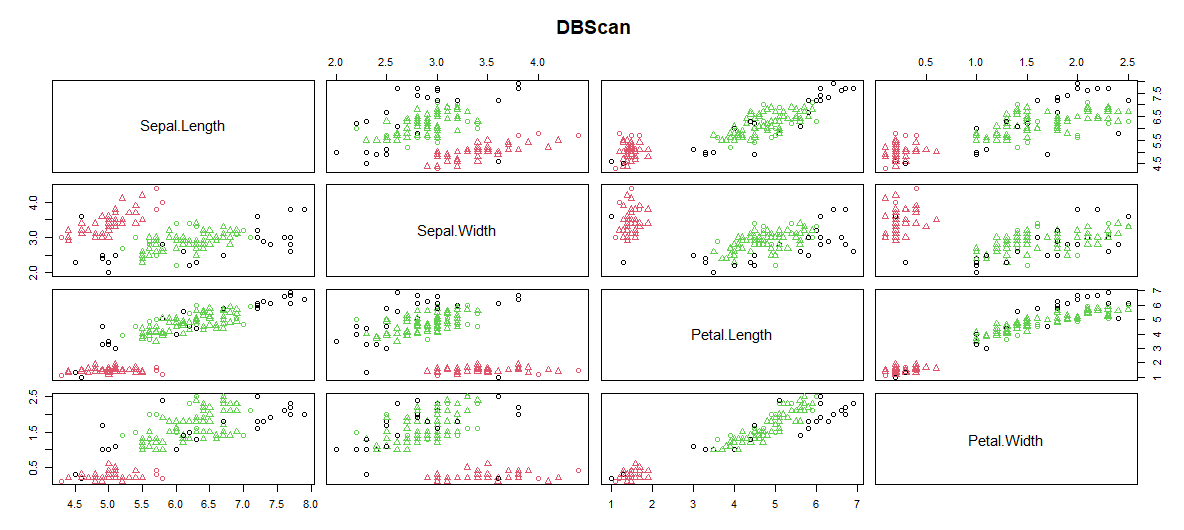
DBScan 簇是用 Sepal.Length、Sepal.Width、Petal.Length、Petal.Width 绘制的。

该图绘制在 Petal.Width 和 Sepal.Length 之间。
因此,DBScan 聚类算法也可以形成不寻常的形状,这对于在行业中查找非线性形状的集群很有用。